
Latte:Latent diffusion transformer for video generation


.png)


Latte: Latent Diffusion Transformer for Video Generation - 知乎项目地址: Latte: Latent Diffusion Transformer for Video Generation (maxin-cn.github.io)GitHub: https://github.com/Vchitect/Latte简介作者提出了一个novel Latent Diffusion Transformer,叫做Latte,它…![]() https://zhuanlan.zhihu.com/p/6846081901.introduction
https://zhuanlan.zhihu.com/p/6846081901.introduction
DiT和U-ViT将ViT的架构融入图像生成的扩散模型,基于transformer的潜在扩散模型能够提升视频生成的现实感?latte使用预训的VAE将输入视频编码为潜在空间的特征,从中提取出token,然后输入到transformer中。clip patch embedding,model variants,timestep-class information和learning strategies上做了大量改进。
2.methodology
3.1 preliminary of latent diffusion models
扩展了适用于视频生成的LDM,1.编码器将每个视频帧压缩到潜在空间;2.扩散过程在视频的潜在空间中进行,以建模潜在的时空信息。
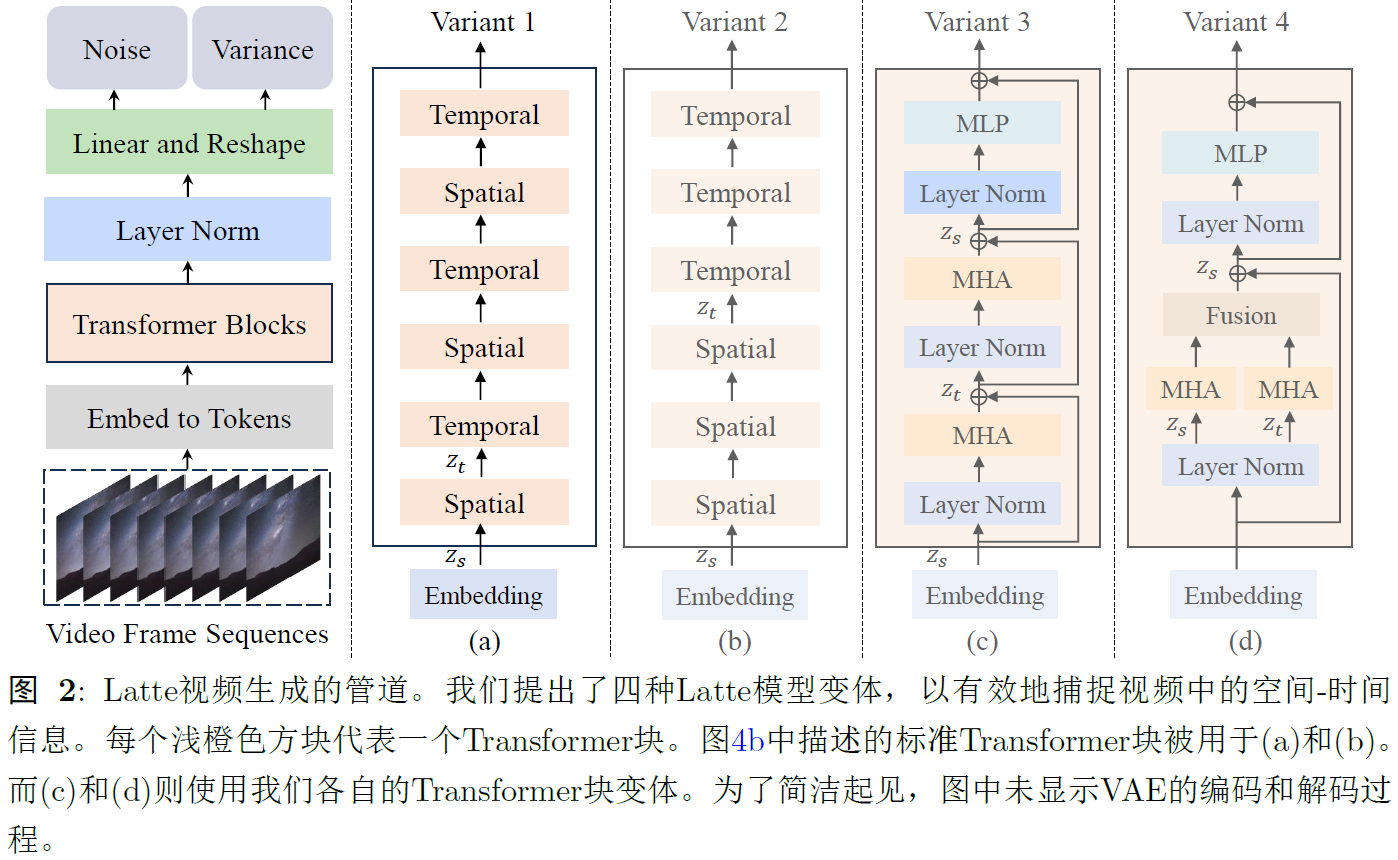
3.2 The model variants of Latte
Variant 1.transformer backbone包括spatial transformer blocks和temporal transformer blocks。前者专注于同一temporal index上共享的token之间捕捉空间信息,后者以interleaved fusion方式捕捉时间维度上的信息。
假设有一个潜在空间中的video clip VL∈FxHxWxC,现将VL转成tokens,记Z'∈nf x nh x nw xd,F表示帧数,HWC表示潜在空间中视频帧的高宽通道数,video clip在潜在空间中的token总数是nf x nh x nw,d表示每个token的维度,将spatial-temporal positional embedding p添加在Z'中,得到Z=Z'+p,作为transformer backbone的输入。
将Z reshape为Zs∈nf x t x d作为spatial transformer的输入,用于捕捉空间信息,t=nhxnw表示每个时间索引的token数量,随后包含空间信息的Zs被reshape为Zt∈txnfxd,作为时间transformer的输入,用于捕捉时间信息。
Variant 2.不使用交错融合,而是先空间再时间。
Variant 3. 1和2主要关注transformer的分解,3关注分解transformer中的multi-head attention,首先仅在空间维度上计算self-attention,然后在时间维度上进行,因此,每个transformer同时捕捉空间和时间信息。
Variant 4.多头注意力分解成两部分。
transformer backbone之后,解码视频token序列以预测噪声和协方差。
3.3 the empirical analysis of latte
3.3.1 latent video clip patch embedding
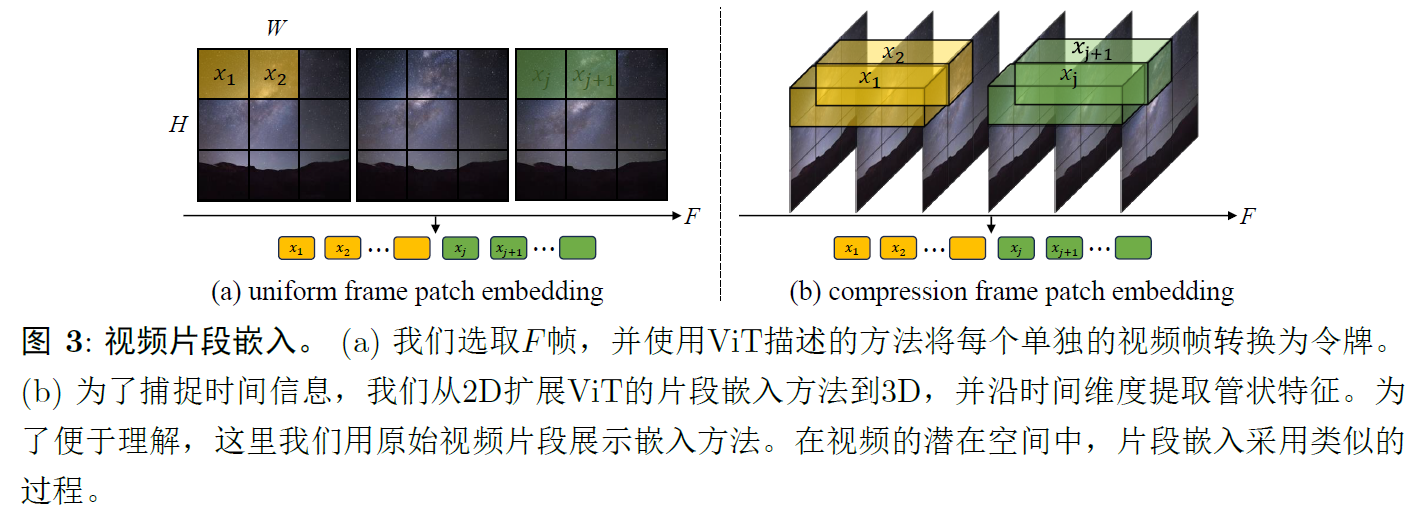
嵌入video clip,两种方法:uniform frame patch embedding和compression frame patch embedding,前者如图3a所示,ViT的帧块embedding,对每个视频单独处理,从每个视频帧中提取非重叠的图像块。后者如b所示,将ViT的帧块embedding扩展到temporal维度,以在潜在的video cllip中建模时间维度,沿着时间维度以步长s提取特征,然后映射到token,在使用压缩帧块嵌入时,额外的步骤包括在standard linear decoder和reshaping operation之后,应用3D transposed conv进行时间上采样,以提升输出潜在视频的分辨率。
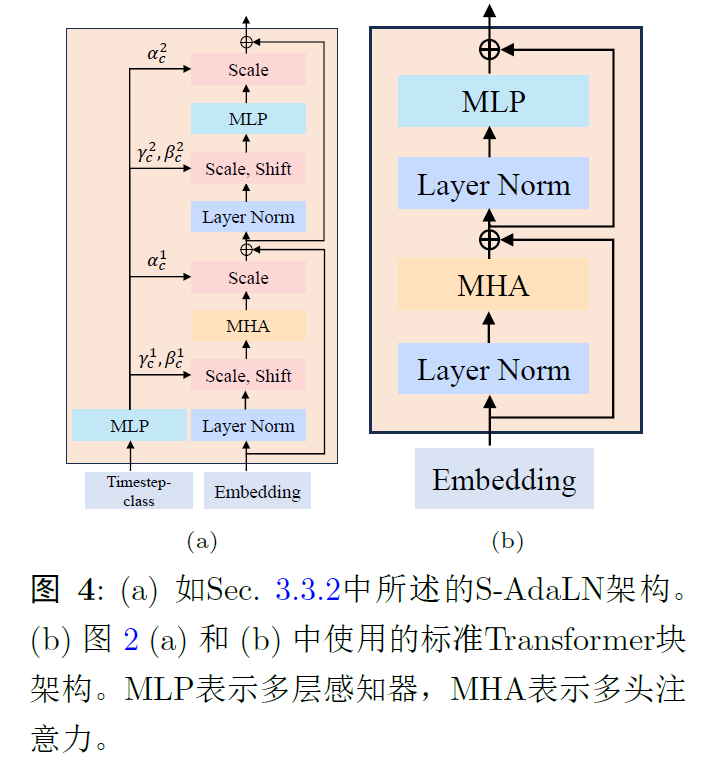
3.3.2 Timestep-class information injection
将时间步或类别融入模型方法。两种方法:将其视为tokens和类似于自适应层归一化AdaLN。
3.3.3 Temporal positional embedding
两种方法:1.绝对位置编码采用不同频率的正弦和余弦函数,2.相对位置编码使用RoPE.
3.3.4 Enhancing video generation with learning strategies
预训练模型和图像-视频联合训练。从ImageNet上预训练的DiT迁移到Latte,每个token应用一个positional embedding,Latte是预训练DiT的nf倍,沿着时间维度将positional embedding重复nf次。删除DiT中的类别嵌入,并使用领初始化。CNN-besed的SD都应用了图像-视频的联合训练,这里作者也把图像-视频的联合训练应用到了Latte中,作者从同一个训练数据集中随机选取了若干video frames(看代码选择了8帧,video clip是16帧),然后拼接在chosen videos后面一起送入Transformer backbone中,但是在Transformer内部有一些区别,区别在于,chosen videos会经过temporal block,但是选取的若干video frames不会经过temporal block。
4.Experiments
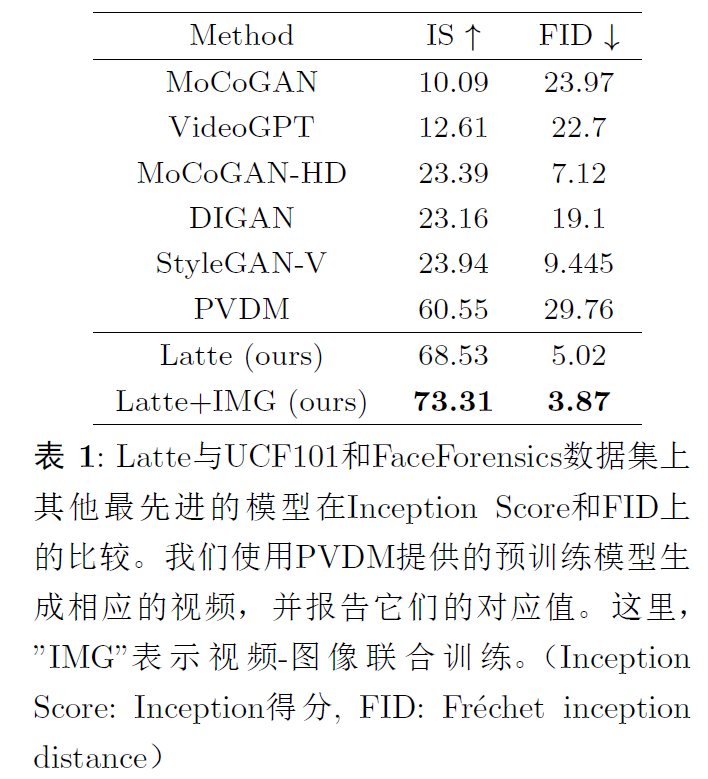

4.1 Experimental setup
数据集:FaceForensics,SkyTimelaps,UCF101,Taich-HD.提取16帧,256x256.

")


")

