
稳态视觉诱发电位 (SSVEP) 分类学习系列 (3) :3DCNN
稳态视觉诱发电位分类学习系列:3DCNN
- 0. 引言
- 1. 主要贡献
- 2. 提出的方法
- 2.1 解码主要步骤
- 2.2 网络具体结构
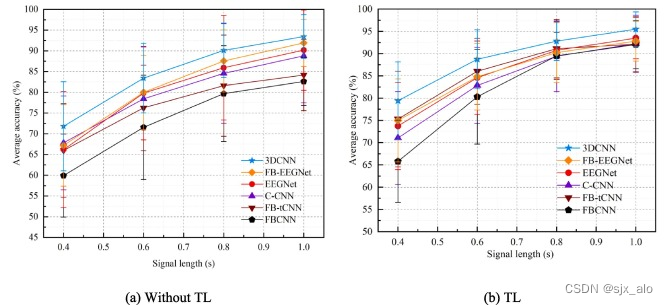
- 2.3 迁移策略
- 3. 结果和讨论
- 3.1 数据集1上的结果
- 3.2 数据集2上的结果
- 3.3 零填充
- 4. 总结
- 欢迎来稿
论文地址:https://www.sciencedirect.com/science/article/abs/pii/S1746809423013642
论文题目:Deep transfer learning-based SSVEP frequency domain decoding method
论文代码:暂无
0. 引言
目的
提高基于稳态视觉诱发电位的脑机接口(SSVEP-BCI)系统的解码精度和信息传递速率(ITR),缩小主体间方差是SSVEP-BCI系统应用的关键。为此,我们提出了一种基于深度迁移学习的SSVEP频域解码方法,以提高解码性能。
方法
使用滤波器组和基于零填充的快速傅里叶变换技术提取具有丰富空间域和频域特征的输入数据表示。设计了一种简洁高效的三维卷积神经网络(3DCNN)模型,用于输入数据的特征提取和解码。提出了一种迁移学习策略,以进一步提高解码精度并缩小主体间差异。
结果
我们提出的3DCNN在信号长度为1 s的基准数据集上实现了89.35%的平均分类准确率和173.02比特/分钟的ITR。在我们的实验室数据集中,当信号长度为0.6 s时,3DCNN的平均分类精度和ITR分别达到88.75%和120.33 bit/min。
总的来说:零填充感觉是一个很不错的数据增强的方法。。关于为什么结构是3DCNN其实还是很疑惑的,没有感觉到从网络结构的层面上表现出来。。。
1. 主要贡献
- 设计了一种结合滤波组技术和零填充快速傅里叶变换的特征提取方法,有效地获得了脑电图中丰富的空间域和频域特征。
- 构建了高效的深度学习模型,能够很好地学习输入的潜在语义特征,实现较高的信息传递速率和解码精度。
- 所提出的迁移学习训练策略有效缓解了模型训练数据不足的问题,降低了主体间变异性,提高了模型的泛化性能。
2. 提出的方法
SSVEP信号解码过程如下图所示:
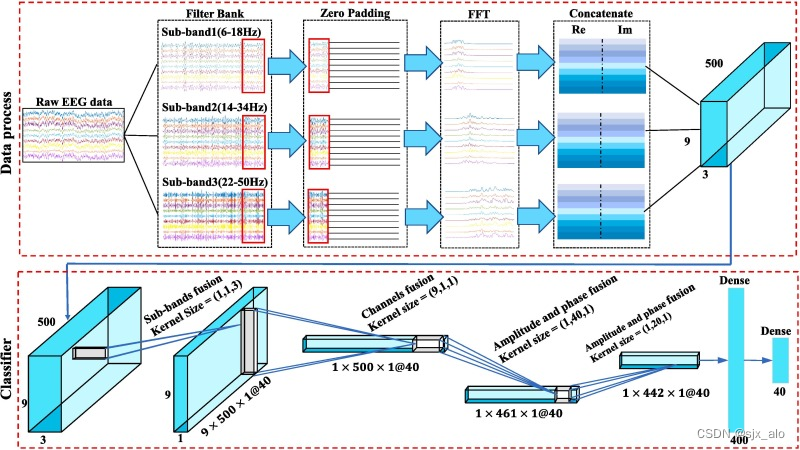
2.1 解码主要步骤
解码的主要步骤如下:
- 对数据进行带通滤波。滤波器组分别为:6-18 Hz、14-34 Hz、22-50 Hz。
- 对信号末端进行零填充。可以提高频率密度,并减少FFT计算频谱的采样误差。但是需要注意FFT分辨率发生了变化。
- 进行FFT变换,并将实部和虚部进行合并,左边实部右边虚部。
- 将3个子带特征在深度方向上串联,得到新的数据输入形式 ( N c ∗ N F c ∗ N d ) (N_c*N_{Fc}*N_d) (Nc∗NFc∗Nd), N c N_c Nc表示脑电通道数, N F c N_{Fc} NFc表示特征数, N d N_d Nd表示子带个数(深度)。
- 将数据输入3DCNN网络结构。
2.2 网络具体结构
网络具体结构如下所示:
注意:代码框架是Tensorflow2

2.3 迁移策略
对于数据集1而言有35名被试,每名被试进行了6组,每组40次的实验。使用其中34名被试的所有数据用来做预训练,然后使用最后一名被试的5组实验数据来做微调,最后使用最后1组实验来做测试。进行6次实验来取平均值作为该名被试的实验结果。
3. 结果和讨论
3.1 数据集1上的结果
不同分类算法的比较:
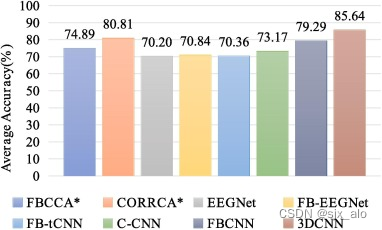
3.2 数据集2上的结果
数据集 2 的平均分类准确率如下图所示:
3.3 零填充
本研究主要分析了不同输入数据点对1 Hz(无零填充)、0.5 Hz、0.33 Hz、0.25 Hz和0.2 Hz下FFT分辨率结果的影响。实验结果表明,当分辨率从1 Hz提高到0.5 Hz时,在输入数据点250处进行零填充,分类精度显著提高。然而,当FFT分辨率继续提高时,分类精度会降低。经过分析可以知道,当分辨率为1 Hz、0.5 Hz、0.33 Hz、0.25 Hz、0.2 Hz时,250个输入数据点对应的频段范围分别为0-125 Hz、0-62.5 Hz、0-41.25 Hz、0-31.25 Hz和0-25 Hz。在输入数据点数为250个的前提下,1 Hz FFT分辨率具有较宽的频率范围。然而,由于分辨率低,对于整数频率只能观察到有限的频率信息。这被称为共同围栏效应。当分辨率为 0.5 Hz 时,频带范围缩小到 0-62.5 Hz,但在我们感兴趣的频段范围 (6-50 Hz) 中可以观察到更多的频点信息。这相当于移动围栏以在其他频率点进行观察。这就解释了为什么通过缩小频带来提高分类精度。同样,FFT分辨率不断提高,但分类精度逐渐降低的现象也可以解释。这是因为由于频带的逐渐变窄,许多高频信息丢失了。此外,我们还发现,通过将输入数据点的数量从 250 个增加到 500 个,可以提高分类准确性。这是因为增加输入数据点的数量可以扩大频率范围。这弥补了高分辨率导致的高频信息丢失问题。然而,通过进一步增加输入数据点的数量,无法显著提高分类精度,因为这只会增加一些无用的频率信息和计算。

4. 总结
到此,使用 稳态视觉诱发电位 (SSVEP) 分类学习系列 (3) :3DCNN 已经介绍完毕了!!! 如果有什么疑问欢迎在评论区提出,对于共性问题可能会后续添加到文章介绍中。
如果觉得这篇文章对你有用,记得点赞、收藏并分享给你的小伙伴们哦😄。
欢迎来稿
欢迎投稿合作,投稿请遵循科学严谨、内容清晰明了的原则!!!! 有意者可以后台私信!!



