
33个可用于抓取数据的开源爬虫软件工具
温馨提示:这篇文章已超过527天没有更新,请注意相关的内容是否还可用!
用户需要熟悉 XML 和正则表达式。目前该工具可以用于抓取各种论坛、贴吧、各种CMS系统。、phpbb、论坛和博客这样的文章可以通过这个工具轻松捕获。爬网定义完全采用 XML 格式,适合 Java 开发人员。使用 WebContent/sql 下的 wcc.sql 文件创建示例数据库。当有参数时,名称为配置文件名。系统自带了3个例子,分别是baidu.xml来抓取百度知道,example.xml来抓取我的javaeye博客,bbs.xml来抓取discuz论坛的内容。然后,打开目标页面,分析该页面的HTML结构,并获取所需数据的XPath。Webmagic是一个无需配置、易于二次开发的爬虫框架。这是一个非常简单易用的抓取工具。国内首个针对微博数据的爬虫程序!
这个项目还很不成熟,但是功能已经基本完成了。 用户需要熟悉 XML 和正则表达式。 目前该工具可以用于抓取各种论坛、贴吧、各种CMS系统。 像 Discuz!、phpbb、论坛和博客这样的文章可以通过这个工具轻松捕获。 爬网定义完全采用 XML 格式,适合 Java 开发人员。
指示:
下载右边的.war包,导入到eclipse中。
使用 WebContent/sql 下的 wcc.sql 文件创建示例数据库。
修改src包下wcc.core的dbConfig.txt,将用户名和密码设置为自己的mysql用户名和密码。
然后运行SystemCore。 运行时,会出现在控制台中。 如果没有参数,将执行默认的example.xml配置文件。 当有参数时,名称为配置文件名。
系统自带了3个例子,分别是baidu.xml来抓取百度知道,example.xml来抓取我的javaeye博客,bbs.xml来抓取discuz论坛的内容。
特点:通过 XML 配置文件进行高度可定制和可扩展
12.蜘蛛侠
Spiderman是一款基于微内核+插件架构的网络蜘蛛。 其目标是通过简单的方法捕获复杂的目标网页信息并将其解析为它需要的业务数据。
如何使用?
首先,确定你的目标网站和目标网页(即你想要获取数据的某类网页,比如网易新闻的新闻页面)
然后,打开目标页面,分析该页面的HTML结构,并获取所需数据的XPath。 请参阅下文了解如何获取 XPath。
最后,在xml配置文件中填写参数并运行Spiderman!
特点:灵活、扩展性强,微内核+插件架构,无需编写一行代码,通过简单配置即可完成数据采集
13. 网络魔法
Webmagic是一个无需配置、易于二次开发的爬虫框架。 它提供了简单灵活的API,只需要少量的代码就可以实现爬虫。

Webmagic采用完全模块化设计,功能覆盖整个爬虫生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取、自动重试以及定制UA/Cookies等功能。
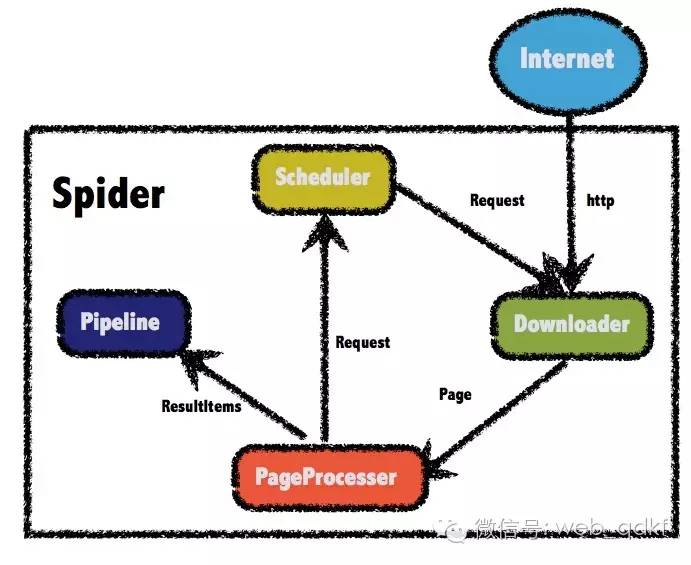
Webmagic 包含强大的页面提取功能。 开发者可以方便地使用CSS选择器、xpath和正则表达式来提取链接和内容,并支持多个选择器的链式调用。
webmagic使用文档:
查看源代码:
特点:功能覆盖整个爬虫生命周期,使用Xpath和正则表达式提取链接和内容。
注:这是黄一华贡献的国产开源软件
14. 网络收获
Web-Harvest是一个Java开源Web数据提取工具。 它能够收集指定的网页并从这些页面中提取有用的数据。 Web-Harvest主要利用XSLT、XQuery、正则表达式等技术来实现text/xml操作。
实现原理是使用httpclient根据预定义的配置文件获取页面全部内容(本博客有的文章已经介绍了httpclient的内容),然后使用XPath、XQuery、正则表达式等技术来实现text/xml 内容过滤操作,选择精确的数据。 近两年流行的垂直搜索(如酷讯等)也是采用类似原理实现的。 对于Web-Harvest应用程序来说,关键是理解和定义配置文件,剩下的就是考虑如何处理数据的Java代码。 当然,在爬虫启动之前,也可以将Java变量填充到配置文件中,实现动态配置。
特点:使用XSLT、XQuery、正则表达式等技术操作Text或XML,具有可视化界面
15.WebSPHINX
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。 网络爬虫(也称为机器人或蜘蛛)是自动浏览和处理网页的程序。 WebSPHINX由两部分组成:爬虫工作平台和WebSPHINX类包。
许可协议:阿帕奇
开发语言:Java
特点:由爬虫工作平台和WebSPHINX类包两部分组成
16. 亚西
YaCy是一个基于p2p的分布式网络搜索引擎。 它也是一个Http缓存代理服务器。 该项目是一种基于p2p构建Web索引网络的新方法。 它可以搜索自己或全局索引,也可以爬行自己的网页或开始分布式爬行等。
特点:基于P2P的分布式Web搜索引擎
Python爬虫17、QuickRecon
QuickRecon 是一个简单的信息收集工具,可以帮助您查找子域名、执行区域传输、收集电子邮件地址以及使用微格式查找关系等。QuickRecon 用 python 编写,支持 Linux 和 Windows 操作系统。
功能:查找子域名、收集电子邮件地址、查找关系等功能
18.PyRailgun
这是一个非常简单易用的抓取工具。一个简单、实用、高效的Python网络爬虫模块,支持爬取JavaScript渲染的页面。
特点:简单、轻量、高效的网络爬虫框架
注:这个软件也是中国人打开的
github 下载:#readme
19. Scrapy
Scrapy是一个基于Twisted的异步处理框架,用纯Python实现的爬虫框架。 用户只需要定制和开发几个模块,就可以轻松实现一个爬虫来爬取网页内容和各种图像。 非常方便~
github源代码:
特点:基于Twisted的异步处理框架,文档齐全
C++爬虫20、hispider
HiSpider是一款快速、高性能的蜘蛛,速度快
严格来说,它只能是一个蜘蛛系统框架。 无需细化。 目前只能提取URL、URL去重、异步DNS解析、队列任务、支持N机分布式下载、支持网站定向下载(需要配置hispiderd.ini白名单)。
特点及用途:
工作过程:
许可证:BSD
开发语言:C/C++
操作系统:Linux
特点:支持多机分布式下载,支持网站定向下载
21. 拉宾
Larbin是法国年轻人Sébastien Ailleret独立开发的开源网络爬虫/网络蜘蛛。 larbin的目的是能够跟踪页面的URL进行扩展爬行,最终为搜索引擎提供广泛的数据源。 Larbin只是一个爬虫,也就是说larbin只爬取网页,而如何解析则由用户自己完成。 另外larbin没有提供如何存储到数据库以及创建索引。 一个简单的larbin爬虫每天可以获取500万个网页。
使用larbin,我们可以轻松获取/确定单个网站的所有链接,甚至可以镜像一个网站; 我们还可以用它来创建一个URL列表组,比如对所有网页进行url检索,然后获取xml链接。 无论是 mp3,还是定制的 larbin,都可以用作搜索引擎的信息源。
特点:高性能爬虫软件,只负责爬取,不解析
22.Methabot
Methabot 是一款速度优化、高度可配置的爬虫软件,适用于 WEB、FTP 和本地文件系统。
特点:超速优化,能够爬取WEB、FTP和本地文件系统
源代码:
C#爬虫23、NWebCrawler
NWebCrawler是一个开源的、C#开发的网络爬虫程序。
特征:
许可协议:GPLv2
开发语言:C#
操作系统:Windows
项目主页:
特点:统计信息、执行过程可视化
24. 西纳勒
国内首个针对微博数据的爬虫程序! 前身为“新浪微博爬虫”。
登录后,您可以指定用户为起点,以用户的关注者和粉丝为线索,通过人脉关系收集用户的基本信息、微博数据、评论数据。
本应用获得的数据可作为科学研究、新浪微博相关研发等的数据支撑,但请勿用于商业用途。 该应用程序基于.NET2.0框架,需要SQL SERVER作为后端数据库,并为SQL Server提供数据库脚本文件。
另外,由于新浪微博API的限制,爬取的数据可能不够完整(如粉丝数量限制、微博数量限制等)
本程序的版权归作者所有。 您可以自由地:复制、分发、展示和表演当前作品以及创作衍生作品。 您不得将当前作品用于商业目的。
5.x版本已经发布! 该版本共有6个后台工作线程:爬取用户基本信息的机器人、爬取用户关系的机器人、爬取用户标签的机器人、爬取微博内容的机器人、爬取微博评论的机器人和爬取微博评论的机器人。调整请求。 机器人出现的频率。 更好的性能! 最大限度发挥爬虫的潜力! 从目前的测试结果来看,个人使用足够了。
该程序的特点:
6 个后台工作线程,最大限度地发挥爬虫性能潜力!
界面提供参数设置,灵活方便
放弃app.config配置文件,自行实现配置信息加密存储,保护数据库账号信息
自动调整请求频率,防止超过限制,避免速度过慢降低效率。
随意控制爬虫,可以随时暂停、继续、停止爬虫
良好的用户体验
许可协议:GPLv3
开发语言:C#.NET
操作系统:Windows
25. 蜘蛛网
Spidernet 是一个以递归树为模型的多线程网络爬虫程序。 支持text/html资源的获取。 可设置爬取深度、最大下载字节限制,支持gzip解码,支持gbk(gb2312)和utf8编码。 资源; 存储在 sqlite 数据文件中。
源代码中的TODO:标记描述了未完成的功能,希望您能提交您的代码。
github源代码:
特点:基于递归树的多线程网络爬虫,支持GBK(gb2312)和utf8编码的资源,使用sqlite存储数据
26. 网络爬虫
mart和Simple Web Crawler是一个网络爬虫框架。 集成 Lucene 支持。 爬虫可以从单个链接或链接数组开始,提供两种遍历模式:最大迭代和最大深度。 您可以设置过滤器来限制抓取的链接。 默认提供三个过滤器:ServerFilter、BeginningPathFilter 和 RegularExpressionFilter。 这三个过滤器可以通过 AND、OR 和 NOT 进行组合。 可以在解析过程或页面加载之前和之后添加侦听器。 介绍内容来自Open-Open
特点:多线程,支持抓取PDF/DOC/EXCEL等文档源
27. 网络矿工
网站数据采集软件 Network Miner Collector(原Soukey Picking)
Soukey Picking网站数据采集软件是一款基于.Net平台的开源软件,也是网站数据采集软件类型中唯一的开源软件。 Soukey虽然采用开源,但并不影响软件的功能,甚至比一些商业软件还要丰富。
特点:功能丰富,不亚于商业软件
PHP爬虫28、OpenWebSpider
OpenWebSpider 是一个开源的多线程网络蜘蛛(机器人:robot,爬虫:crawler)和搜索引擎,包含许多有趣的功能。
特点:开源多线程网络爬虫,具有许多有趣的功能
29.PhpDig
PhpDig是一个用PHP开发的网络爬虫和搜索引擎。 通过索引动态和静态页面来构建词汇表。 当搜索查询时,它会按照一定的排序规则显示包含关键字的搜索结果页面。 PhpDig 包括一个模板系统,可以索引 PDF、Word、Excel 和 PowerPoint 文档。 PHPdig适合更专业、更深入的个性化搜索引擎。 用它来构建某个领域的垂直搜索引擎是最好的选择。
演示:
特点:具有采集网页内容、提交表单的功能。
30.思考
ThinkUp是一个社交媒体透视引擎,可以从Twitter和Facebook等社交网络收集数据。 通过从个人社交网络帐户收集数据,归档和处理交互式分析工具,并将数据绘制成图表以便更直观地查看。
github源代码:
特点:社交媒体透视引擎,从Twitter、Facebook等社交网络收集数据,并可以进行交互式分析并以可视化形式展示结果
31.微购物
微商社交购物系统是一个基于ThinkPHP框架开发的开源购物分享系统。 也是一款面向站长的开源淘宝建站程序。 集成了300多家淘宝、天猫、淘宝等商品数据采集接口,为淘宝站长提供万无一失的淘宝建站服务。 如果您了解 HTML,则可以制作程序模板。 它是免费的并可供下载。 是淘宝站长的首选。
演示网址:
许可协议:GPL
开发语言:PHP
操作系统:跨平台
ErLang爬虫32、Ebot
Ebot是一个用ErLang语言开发的可扩展的分布式网络爬虫。 URL 保存在数据库中,可以通过 RESTful HTTP 请求进行查询。
github源代码:
项目主页:
特点:可扩展的分布式网络爬虫
Ruby爬虫33、Spidr
Spidr是一个Ruby网络爬虫库,可以完全抓取整个网站、多个网站以及本地的某个链接。
特点:本地可完整抓取一个或多个网站及一个链接
本文由36大数据收集整理
专注于软件设计和架构以及技术管理。 善于用通俗易懂的语言解释技术。 对技术管理工作有一定的意见。 文章将尽快在本站发表。 欢迎大家关注和参观!
“完成的?”
“你不再每天工作到凌晨两点了吗?”
“你不用一遍遍核对数据吗?”
“不再需要研究那些难读的映射规则了?”
“你是在做梦,还是醒着?”
当我睁开眼睛的时候,已经是下午两点了。 为期一年的数据迁移工作于昨晚结束。 经过多次上线,数亿条数据从旧系统进入新系统,开启了新的生命。
回顾整个数据迁移的过程,可以说是极其痛苦的。 当然,也获得了宝贵的经验。
据说每个程序员都至少会涉及一次数据迁移。 如果你想在轮到你的时候减轻痛苦,我们不妨继续阅读。
为什么数据迁移项目很难
如果你从未做过数据迁移项目,很容易低估数据迁移的难度。
“不就是将数据从一个数据库传输到另一个数据库吗?选择+插入就完成了!” 如果你抱着这样的想法开始数据迁移,你和你的团队很快就会陷入深渊。
现在让我们揭开数据迁移“简单”的外衣,找出阻碍迁移成功的小恶魔。
新旧系统的所有DB设计你都熟悉吗?
“你熟悉新系统的DB设计吗?”
“当然!我参与了核心业务逻辑的开发!这是我自己的儿子!”
“那你了解旧系统的数据库设计吗?”
“你绝对听不懂!我们的同事都不应该听懂!”
“迁移规则怎么写?”
“这……让BA想办法吧”
“BA可能连新系统的数据库都不熟悉……”
“……”
如何连接不同数据库的数据?
“你了解MySql吗?”
“废话,我们开发的系统不是用Mysql吗?”
“那你知道xxxx吗?”
“这是新技术吗?”
“这是一个诞生于20世纪70年代的数据库。即将被新系统取代的旧系统使用这个数据库。”
“什么?”
数据量、性能
“您知道要迁移的数据量吗?”
“据说有好几个T!”
“发射当晚一切都完成了吗?”
“是的,业务需要在3小时内完成。”
“……”
数据不正确如何处理?
“你看,很多数据导入失败了。”
“看错误信息,大部分都是迁移验证太严格了。”
“你为什么不放心地检查支票呢?”
“然后新系统刚上线,脏数据就很多!”
“不迁移这些数据怎么样?”
“商界人士会同意吗?”
“那就让业务人员修正一下数据吧!”

“但是很多数据是无法通过界面更改的!”
“那你觉得我们该怎么办……”
“我们先吃饭,一会儿再说……”
业务部门期望太高
“项目启动会上,业务经理要求数据导入100%成功!”
“这是不可能的!”
“企业说数据是公司的财富,公司的资产不能因为改系统而丢失!”
“这样说也没有什么错。”
“没问题吗?那你们今年的KPI就是保证数据迁移100%准确!”
“……你就说今年不给我奖金吧!”
数据迁移已开发完成,但新系统开发尚未完成
“数据迁移项目将于下周正式启动!”
“啊?四个月后新系统的业务需求不是还要开发吗?业务逻辑都还不确定,怎么开发迁移程序呢?”
“我们会等到业务需求确定后才开始建设。明年这个时候可能还无法完工……”
“但随着业务的变化,确定的迁移规则也必须改变……如何避免错过新的业务场景?”
“嘿嘿,一步一步来,做到了,并且珍惜……”
“什么?”
需要开发的不仅仅是数据迁移程序
“加班两个月,终于完成了迁移程序!下周我会休息两天去旅行。”
“嗯……确实,迁移的逻辑部分已经快完成了。但是现在迁移任务只能通过调整API来完成,这么多任务很容易让人困惑。”
“我明白了,我会编写一个 API 将相关任务串联起来!”
“但是还有很多 API 调用要做,为什么不另外写一个页面,通过按钮触发呢?”
“没问题!”
“我们还是需要开发一个统计成功率的工具,不能一直手动统计成功率!玩Excel的人都用Python!”
“好吧,应该不复杂!我们毕竟是专业人士!”
“还有客户想要的错误日志分析报告,我们需要分类、分析、提供错误数据,每次手动统计都需要半天时间,也可以写个程序来做!”
“这个稍微复杂一点,不过没关系!”
“还有,如果每次测试都想重新运行数据,把上次导入的数据删除也挺麻烦的,你想个办法怎么样?”
“……”
“我知道任务很多,但都是必须的……”
“喂?老婆,请退下周去马尔代夫的机票吧!我可能会去封闭式开发……”
迁移工具和技术的学习成本高昂且难以添加资源。
“经理,最近进度有点紧,迁移规则变化很大,QA也报告了很多Bug。”
“要不我调几个开发人员来支援你三周?”
“项目中使用的这些工具和技术,很难快速找到合适的开发人员。没有经验的开发人员只需要两周的时间就能熟悉,而且还剩下一周的时间去做任何事情……”
“那你觉得我们应该怎么做?”
“只能加班了,一会儿我们休息一下吧。”
“好吧,等这个项目完成之后,你大概可以休息一个月了!”
“想想看,我还是很期待的!”
做好数据迁移,仅此而已
看完以上数据迁移过程中的各种问题,你是否感到头疼呢? 事实上,这些问题都是有解决办法的。 根据经验,我细化了以下数据迁移项目中需要注意的事项。
映射规则管理
映射规则是数据迁移的要求。 要写出好的映射规则,需要熟悉新系统和旧系统。 并熟悉数据库设计。 一个人同时熟悉新旧系统几乎是不可能的。 一般来说,需要新旧系统各有一个熟悉系统的成员来共同讨论Mapping规则。

这里我建议开发同学参与Mapping规则的讨论和制定。 因为这个人不仅需要熟悉业务,还需要熟悉数据是如何存储的。
映射规则还需要明确需要迁移的数据范围。 需要明确哪些业务数据需要迁移,需要迁移多长时间。
Mapping规则制定后,需与业务部门明确并确认。 并告知他们成功率不可能是100%,并尽量降低业务预期。
更改映射规则时要格外小心,尤其是在开发结束时,原因如下:
更改了Mapping规则,是为了允许多条报错的数据进入新系统,可能会导致更多数据无法进入。 对映射规则的修改可能会影响系统性能。
如果映射规则错误,必须更改,则必须注意以上两个问题。 不要只关注映射规则更改的实施。
工具和技术培训
数据迁移一般使用ETL工具,当然你也可以开发自己的程序。 迁移方案的重点是如何高效、快速地处理数据,这与业务开发的重点完全不同。 因此,所使用的技术栈也有很大不同。 由于数据迁移所使用的工具和技术在业务开发中很少用到,所以需要提前投入时间进行学习。 并且需要制定长期的学习计划,在项目启动后保持团队的学习和技术交流。
注意保留你学习和分享的材料。 以后新人加入的时候,可以直接学习。 加速整合。 否则新人就很难加入这个项目。
编程
架构师需要首先设计整体代码框架,定义开发规范和流程,编写示例代码。 这确保了当开发集中到项目中时,可以尽快生产出来。 方案设计应考虑以下事项:
迁移任务的记录、解耦和依赖管理日志设计。 需要包含任务名称、错误数据业务主键小节等关键信息。 总之,要方便统计和定位错误。 通过模板化,开发可以只关注业务逻辑。 这降低了映射规则实现的复杂性。 方便调整并发数等性能相关参数。成功率统计、编程、错误日志分析、编程其他辅助工具如何兼容业务系统的新变化
让我重点讨论最后一点。 很多时候在迁移程序开发阶段,业务系统还没有开发出来。 解决业务逻辑变更、表变更对数据迁移的影响是一个难题。 首先,我们可以通过调整业务API来屏蔽业务逻辑的变化,完成数据迁移。 因为它不是表到表转换后直接写入SQL,而是通过业务API写入。 那么当API输入发生变化时,迁移程序就会报错。 另外,如果逻辑调整了,数据自然会按照最新的逻辑进入数据库。
对于新字段、新表,我们可以通过工具对比现有映射规则的表和字段,找出变化点,然后分析是否需要添加映射规则来迁移这些数据。
程序设计和框架代码开发必须在开发高峰到来之前完成。 否则,开发团队就会陷入困境。
性能调优
大规模的数据迁移肯定会出现性能问题。 数据迁移时,新系统和旧系统都不可用。 因此,业务部门肯定希望数据迁移时间尽可能短。 这是一个巨大的性能挑战。 关于性能优化,我有以下建议:
必须有APM工具。 还有针对虚拟机、数据库和其他资源的监控工具。 只有借助工具,才能让性能状况变得透明。 性能瓶颈在哪里一目了然,不然就乱吃药了。 绩效应该是全局考虑的,而不仅仅是流程中单个点的绩效。 很多时候,他们是互相制约的。 减少网络 IO 数量并允许每个请求传输更多数据。 但越多并不总是越好,你需要找到性能的平衡点。 如果数据量太大,可以分批迁移,分批上线。 变化不大的非交易数据可以提前上线。 甚至交易数据也可以考虑提前上线,真正上线的时候再进行增量迁移。 在高并发的迁移过程中,任何参数的调整都可能对性能产生意想不到的影响。 不断尝试,不要想当然。成功率和错误分析报告
没有数据迁移经验的团队很可能会错过项目早期的这两部分开发工作。 诚然,数据迁移的核心是迁移,但业务最关心的是成功率。
这两份报告必须提前设计好。 迁移程序的设计和开发应考虑报告的需求,以记录任务成功率和日志。 否则,如果等到程序开发出来才考虑报表程序的开发,很可能会改变原来的迁移程序的逻辑。
这两份报告需要与业务部门进行澄清,以确定如何处理错误数据。 误差数据处理一般分为以下三类:
对于数据问题,业务可以更改数据。 让企业自行修改。 对于数据问题,无法直接修改业务。 您可以通知商家自行备份数据。 映射规则未考虑的场景。 修改映射规则以适应这些数据。
除了这两份报告之外,迁移过程中还涉及到很多小工具,比如数据清理、环境状态检查工具等,期待这些工具的开发力度。
上线演练
在上线之前,如果可能的话,一定要使用真实的环境和数据进行练习。 时间和执行步骤也应与启动计划一致。
开展线上演练的时机还不能太早。 太早做,会导致演练数据与上线时相差太大,削弱演练效果。 但演练不能进行得太晚,否则就没有时间解决发现的问题。 我的经验是,上线时间提前了两周。
由于演练的时间点与上线时间比较接近,除非发现严重的Bug,才会进行修改。 最好把小问题放在网上,稍后再修复,而不是更改代码来修复它们。 因为你不知道它是否会带来更严重的问题。
在线故障计划
尽管您的发布经历可能从未失败过,但不要认为这次会成功。 如果出现问题,是全部回滚还是部分回滚,必须提前规划好。 是先上线再添加历史数据的解决方案。 直接终止启动并重新启动旧系统也是一种解决方案。 无论计划如何,都需要提前与业务沟通。 因为上线期间的时间非常宝贵。 切忌临时制定计划,导致决策困难,甚至无人决策。
在线的
经过几轮测试和演练,终于到了上线的时间。 对于上网我有以下建议:
合理配置资源。 如果晚上上线,就不要做所有的开发来支持夜间上线。 第二天留下人力提供在线支持。 根据上线计划,认真执行步骤,确保每项操作至少由两对同事完成。 每一步操作完成后必须进行相应的检查。 上线前需要预测可能出现的异常情况及解决方案。 如果出现意外错误,不要惊慌,冷静思考解决方案。在线支持
我向你保证,迁移的数据一定会出现各种问题。 一般来说,修复数据的方法有以下几种:
SQL修复
修复问题数据涉及的表在同一个DB且逻辑不复杂的情况,直接写SQL即可修复
存储过程修复
修复问题数据涉及的表在同一个DB且逻辑复杂的情况。 可以编写存储过程来修复。 优点是不需要发布程序。 缺点是调试和维护困难。
程序修复
当需要跨DB修复问题数据时,需要编写程序进行修复。 这种场景也是最复杂的。
无论采用哪种方法,都需要经过充分的测试。 数据修复是一项非常危险的操作。 一旦程序出现问题,好的数据就可能被破坏。 此外,必须测试修复程序的性能并估计执行时间。
另外,修复生产环境之前必须备份数据。
总结
数据迁移一直是一件棘手的事情。 一定要做好计划,提前想好问题。 团队中最好有做过数据迁移的成员。 即使没有,如果您解决了本文提到的问题,您的数据迁移工作也会轻松很多!



