
openEuler搭建hadoop Standalone 模式
Standalone
- 升级软件
- 安装常用软件
- 关闭防火墙
- 修改主机名和IP地址
- 修改hosts配置文件
- 下载jdk和hadoop并配置环境变量
- 配置ssh免密钥登录
- 修改配置文件
- 初始化集群
- windows修改hosts文件
- 测试
1、升级软件
yum -y update
2、安装常用软件
yum -y install gcc gcc-c++ autoconf automake cmake make \ zlib zlib-devel openssl openssl-devel pcre-devel \ rsync openssh-server vim man zip unzip net-tools tcpdump lrzsz tar wget
3、关闭防火墙
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config setenforce 0
systemctl stop firewalld systemctl disable firewalld
4、修改主机名和IP地址
hostnamectl set-hostname hadoop
vim /etc/sysconfig/network-scripts/ifcfg-ens32
参考如下:
TYPE=Ethernet PROXY_METHOD=none BROWSER_ONLY=no BOOTPROTO=none DEFROUTE=yes IPV4_FAILURE_FATAL=no IPV6INIT=yes IPV6_AUTOCONF=yes IPV6_DEFROUTE=yes IPV6_FAILURE_FATAL=no IPV6_ADDR_GEN_MODE=eui64 NAME=ens32 UUID=55e7ac28-39d7-4f24-b6bf-0f9fb40b7595 DEVICE=ens32 ONBOOT=yes IPADDR=192.168.10.24 PREFIX=24 GATEWAY=192.168.10.2 DNS1=192.168.10.2
5、修改hosts配置文件
vim /etc/hosts
修改内容如下:
192.168.10.24 hadoop
重启系统
reboot
6、下载jdk和hadoop并配置环境变量
创建软件目录
mkdir -p /opt/soft
进入软件目录
cd /opt/soft
下载 JDK
下载 hadoop
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
解压 JDK 修改名称
tar -zxvf jdk-8u411-linux-x64.tar.gz
mv jdk1.8.0_411 jdk-8
解压 hadoop 修改名称
tar -zxvf hadoop-3.3.6.tar.gz
mv hadoop-3.3.6 hadoop-3
配置环境变量
vim /etc/profile.d/my_env.sh
编写以下内容:
export JAVA_HOME=/opt/soft/jdk-8 export HDFS_NAMENODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_ZKFC_USER=root export HDFS_JOURNALNODE_USER=root export HADOOP_SHELL_EXECNAME=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root export HADOOP_HOME=/opt/soft/hadoop-3 export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
生成新的环境变量
source /etc/profile
7、配置ssh免密钥登录
创建本地秘钥并将公共秘钥写入认证文件
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
ssh-copy-id root@hadoop
8、修改配置文件
hadoop-env.sh
core-site.xml
hdfs-site.xml
workers
mapred-site.xml
yarn-site.xml
hadoop-env.sh
文档末尾追加以下内容:
export JAVA_HOME=/opt/soft/jdk-8 export HDFS_NAMENODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_ZKFC_USER=root export HDFS_JOURNALNODE_USER=root export HADOOP_SHELL_EXECNAME=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native
core-site.xml
fs.defaultFS
hdfs://hadoop:9000
hadoop.tmp.dir
/home/hadoop_data
hadoop.http.staticuser.user
root
dfs.permissions.enabled
false
hadoop.proxyuser.root.hosts
*
hadoop.proxyuser.root.groups
*
hdfs-site.xml
dfs.replication
1
dfs.namenode.secondary.http-address
hadoop:9868
workers
注意:
hadoop2.x中该文件名为slaves
hadoop3.x中该文件名为workers
hadoop
mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.application.classpath
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*
yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME
9、初始化集群
# 格式化文件系统 hdfs namenode -format # 启动 NameNode SecondaryNameNode DataNode start-dfs.sh # 查看启动进程 jps # 看到 DataNode SecondaryNameNode NameNode 三个进程代表启动成功
# 启动 ResourceManager daemon 和 NodeManager start-yarn.sh # 看到 DataNode NodeManager SecondaryNameNode NameNode ResourceManager 五个进程代表启动成功
重点提示:
# 关机之前 依关闭服务 stop-yarn.sh stop-dfs.sh # 开机后 依次开启服务 start-dfs.sh start-yarn.sh
或者
# 关机之前关闭服务 stop-all.sh # 开机后开启服务 start-all.sh
#jps 检查进程正常后开启胡哦关闭在再做其它操作
10、修改windows下hosts文件
C:\Windows\System32\drivers\etc\hosts
追加以下内容:
192.168.171.10 hadoop
Windows11 注意 修改权限
-
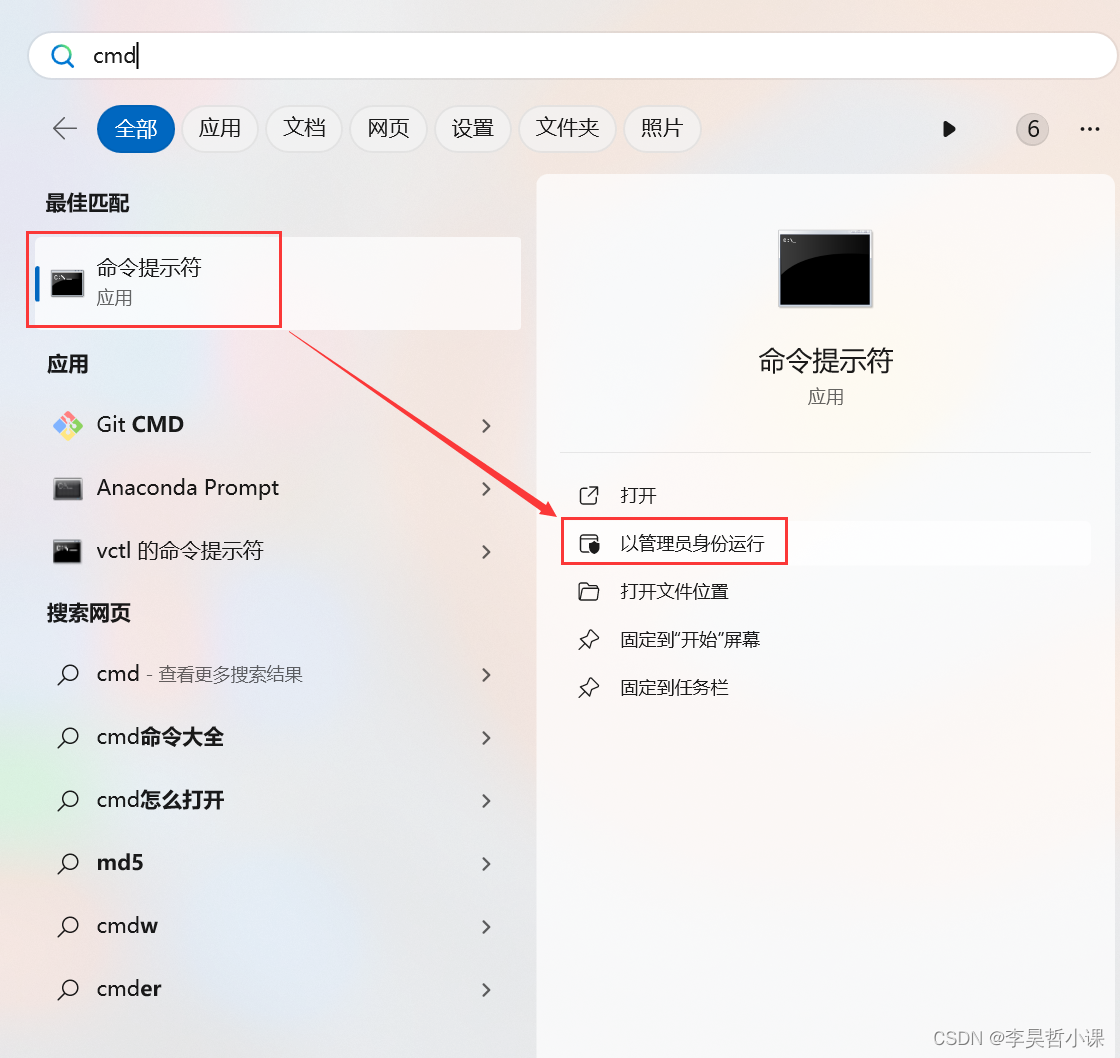
开始搜索 cmd
找到命令头提示符 以管理身份运行
-
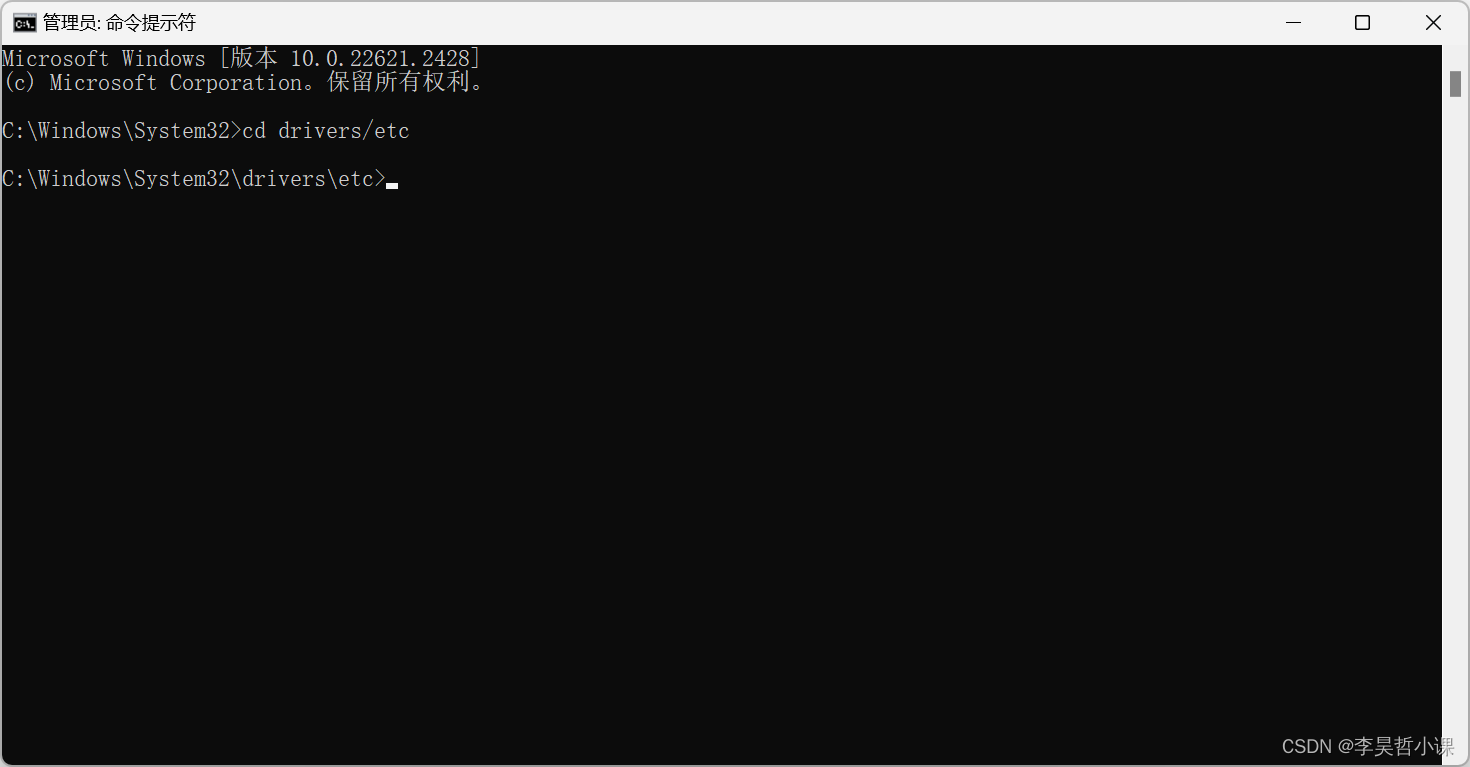
进入 C:\Windows\System32\drivers\etc 目录
cd drivers/etc
-
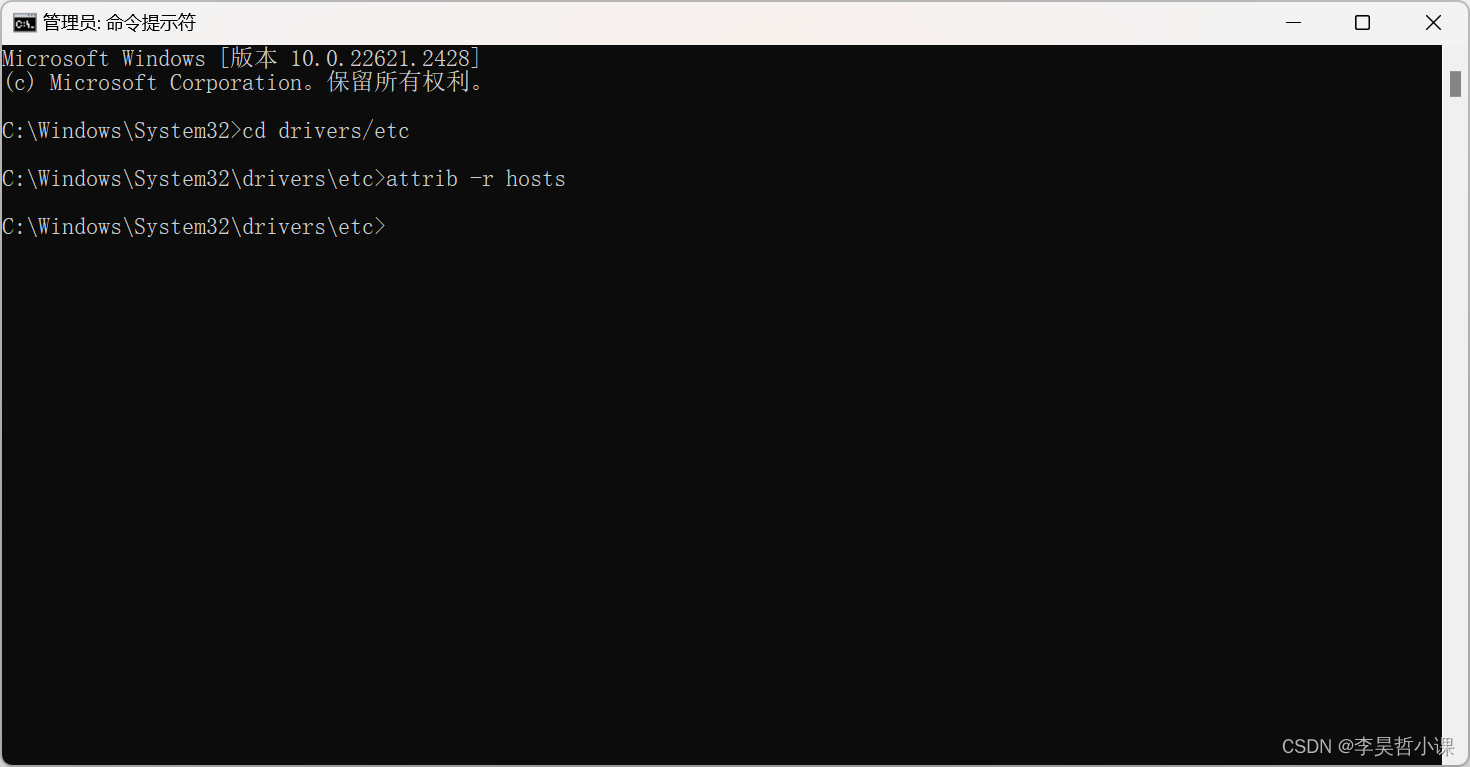
打开 hosts 配置文件
start hosts
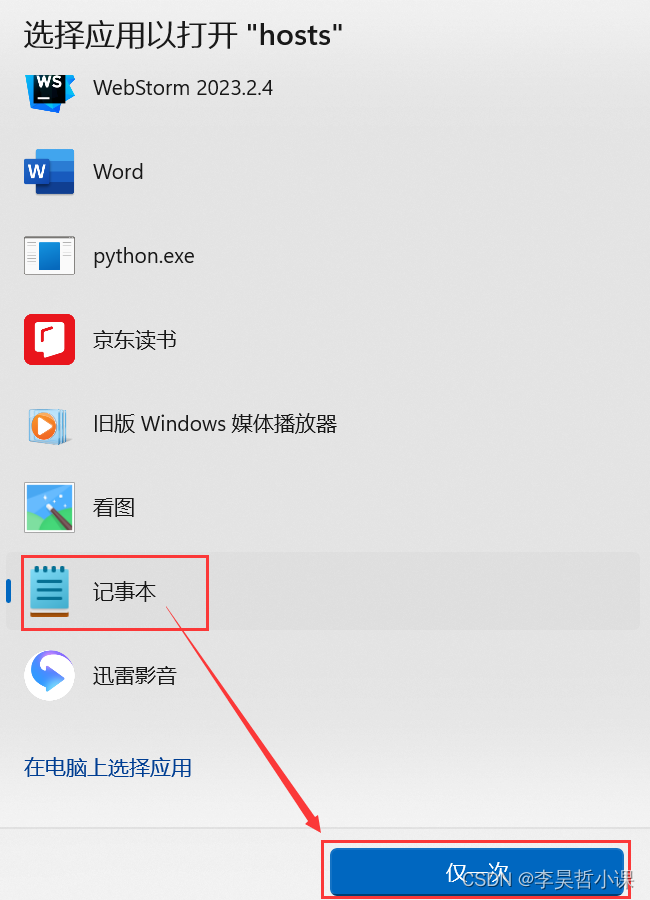
-
追加以下内容后保存
192.168.10.24 hadoop
11、测试
11.1 浏览器访问hadoop
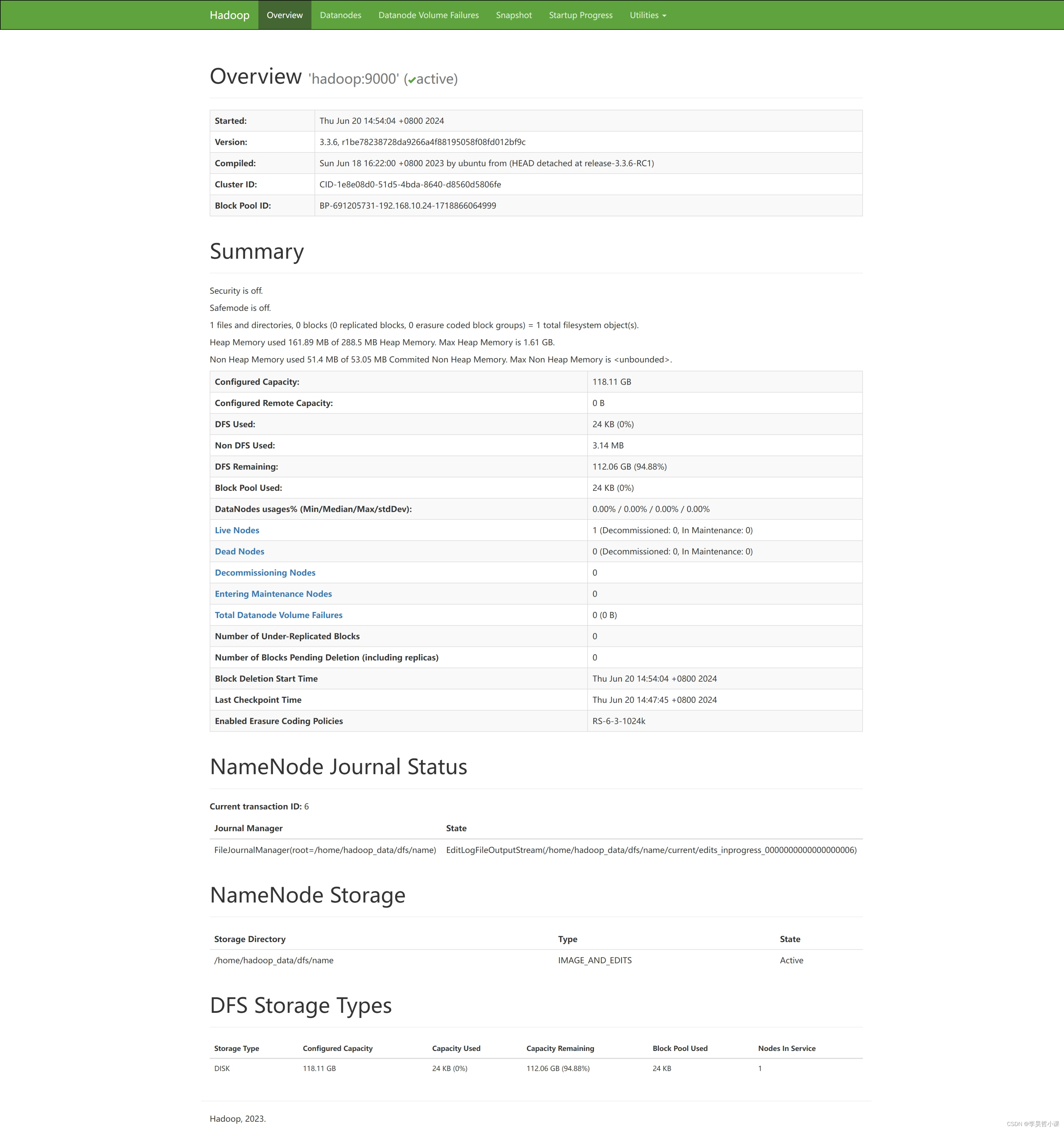
浏览器访问: http://hadoop:9870
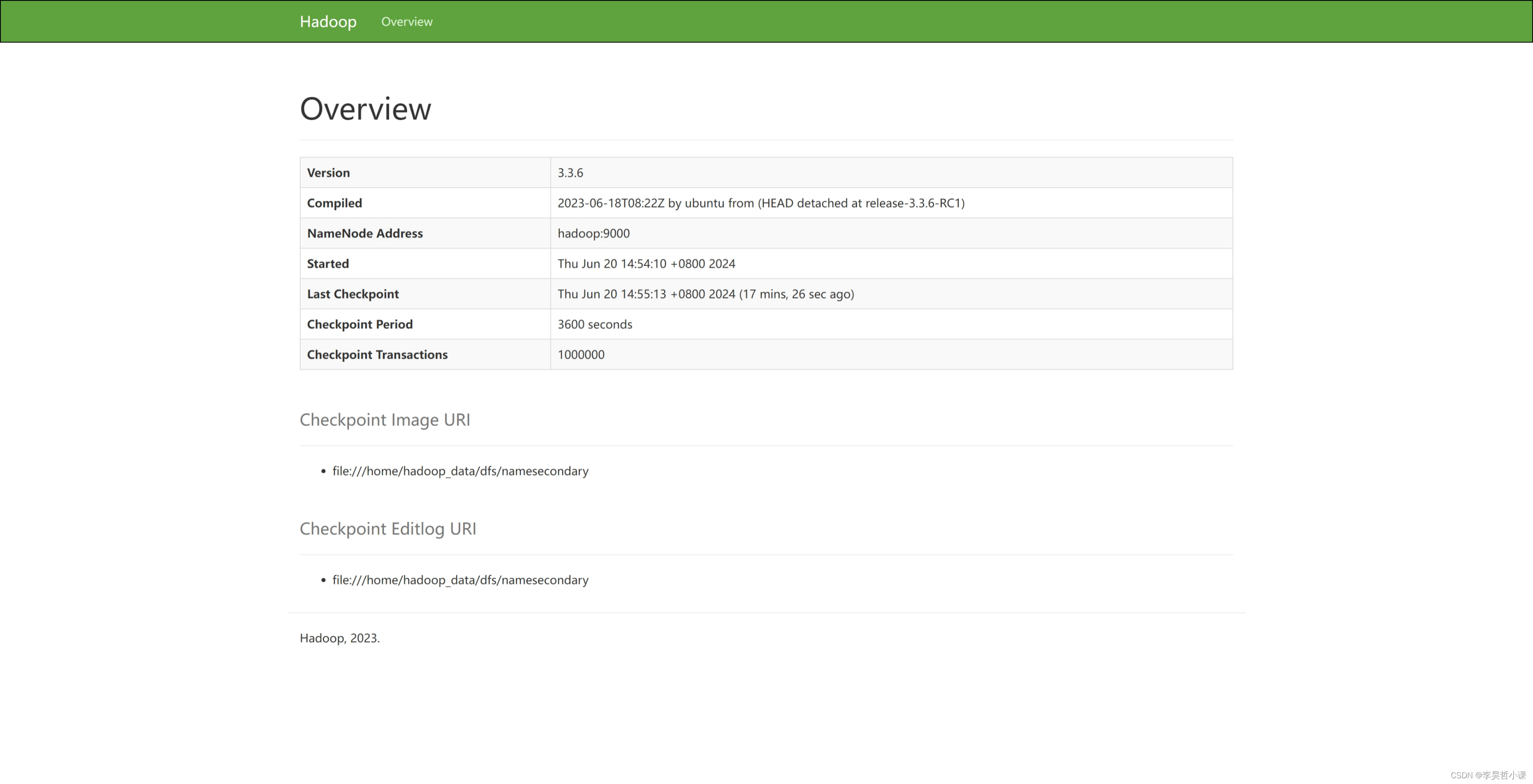
浏览器访问:http://hadoop:9868/
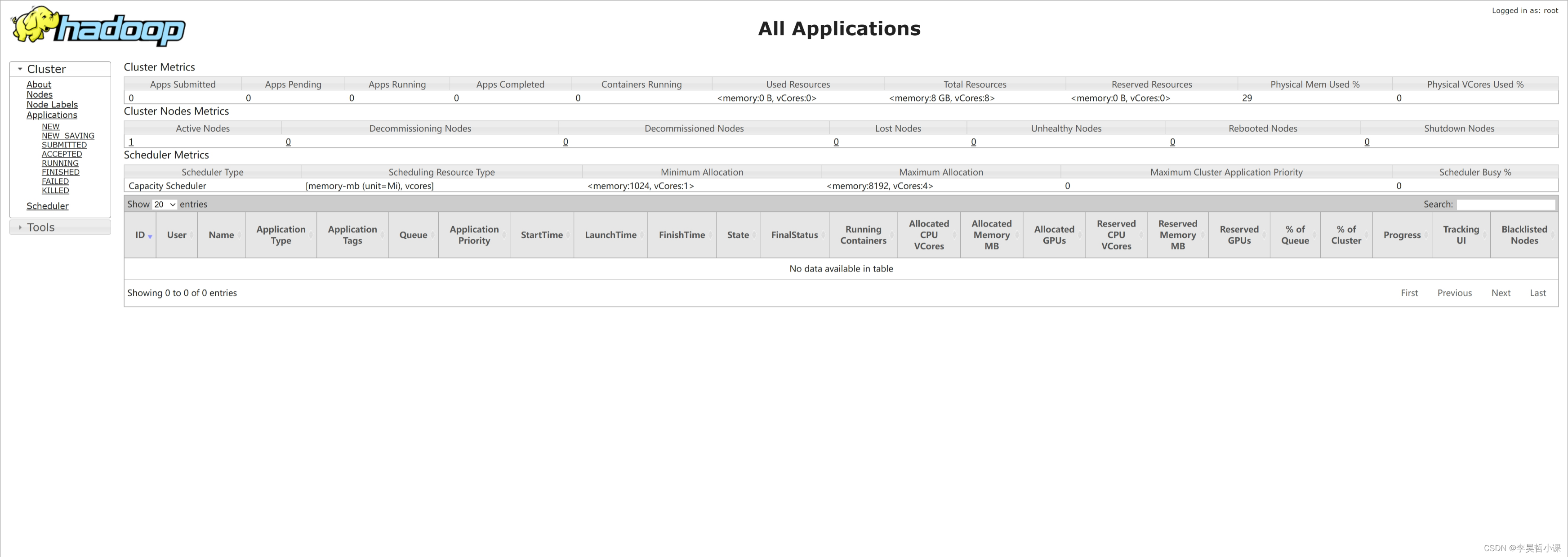
浏览器访问:http://hadoop:8088
11.2 测试 hdfs
本地文件系统创建 测试文件 wcdata.txt
vim wcdata.txt
Spark HBaseHive Flink Storm Hadoop HBase SparkFlinkHBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase HiveHadoop Spark HBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase Hive Spark HBaseHive Flink Storm Hadoop HBase SparkFlinkHBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase HiveHadoop Spark HBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase Hive Spark HBaseHive Flink Storm Hadoop HBase SparkFlinkHBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase HiveHadoop Spark HBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase Hive HiveHadoop Spark HBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase Hive Spark HBaseHive Flink Storm Hadoop HBase SparkFlinkHBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase HiveHadoop Spark HBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase Hive Spark HBaseHive Flink Storm Hadoop HBase SparkFlinkHBase StormHBase Hadoop Hive HiveHadoop Spark HBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase Hive Spark HBaseHive Flink Storm Hadoop HBase SparkFlinkHBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase HiveHadoop Spark HBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase Hive Spark HBaseHive Flink Storm Hadoop HBase SparkFlinkHBase StormHBase Hadoop Hive Spark HBaseHive Flink Storm Hadoop HBase SparkFlinkHBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase HiveHadoop Spark HBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase Hive Spark HBaseHive Flink Storm Hadoop HBase SparkFlinkHBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase HiveHadoop Spark HBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase Hive HiveHadoop Spark HBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase Hive Spark HBaseHive Flink Storm Hadoop HBase SparkFlinkHBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase HiveHadoop Spark HBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase Hive Spark HBaseHive Flink Storm Hadoop HBase SparkFlinkHBase StormHBase Hadoop Hive Spark HBaseHive Flink Storm Hadoop HBase SparkFlinkHBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase HiveHadoop Spark HBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase Hive Spark HBaseHive Flink Storm Hadoop HBase SparkFlinkHBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase HiveHadoop Spark HBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase Hive HiveHadoop Spark HBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase Hive Spark HBaseHive Flink Storm Hadoop HBase SparkFlinkHBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase HiveHadoop Spark HBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase Hive Spark HBaseHive Flink Storm Hadoop HBase SparkFlinkHBase StormHBase Hadoop Hive Spark HBaseHive Flink Storm Hadoop HBase SparkFlinkHBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase HiveHadoop Spark HBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase Hive Spark HBaseHive Flink Storm Hadoop HBase SparkFlinkHBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase HiveHadoop Spark HBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase Hive Spark HBaseHive Flink Storm Hadoop HBase SparkFlinkHBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase HiveHadoop Spark HBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase Hive HiveHadoop Spark HBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase Hive Spark HBaseHive Flink Storm Hadoop HBase SparkFlinkHBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase HiveHadoop Spark HBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase Hive Spark HBaseHive Flink Storm Hadoop HBase SparkFlinkHBase StormHBase Hadoop Hive HiveHadoop Spark HBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase Hive Spark HBaseHive Flink Storm Hadoop HBase SparkFlinkHBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase HiveHadoop Spark HBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase Hive Spark HBaseHive Flink Storm Hadoop HBase SparkFlinkHBase StormHBase Hadoop Hive Spark HBaseHive Flink Storm Hadoop HBase SparkFlinkHBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase HiveHadoop Spark HBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase Hive Spark HBaseHive Flink Storm Hadoop HBase SparkFlinkHBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase HiveHadoop Spark HBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase Hive HiveHadoop Spark HBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase Hive Spark HBaseHive Flink Storm Hadoop HBase SparkFlinkHBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase HiveHadoop Spark HBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase Hive Spark HBaseHive Flink Storm Hadoop HBase SparkFlinkHBase StormHBase Hadoop Hive Spark HBaseHive Flink Storm Hadoop HBase SparkFlinkHBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase HiveHadoop Spark HBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase Hive Spark HBaseHive Flink Storm Hadoop HBase SparkFlinkHBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase HiveHadoop Spark HBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase Hive HiveHadoop Spark HBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase Hive Spark HBaseHive Flink Storm Hadoop HBase SparkFlinkHBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase HiveHadoop Spark HBase StormHBase Hadoop Hive FlinkHBase Flink Hive StormHive Flink HadoopHBase Hive Spark HBaseHive Flink Storm Hadoop HBase SparkFlinkHBase StormHBase Hadoop Hive
在 HDFS 上创建目录 /wordcount/input
hdfs dfs -mkdir -p /wordcount/input
查看 HDFS 目录结构
hdfs dfs -ls /
hdfs dfs -ls /wordcount
hdfs dfs -ls /wordcount/input
上传本地测试文件 wcdata.txt 到 HDFS 上 /wordcount/input
hdfs dfs -put wcdata.txt /wordcount/input
检查文件是否上传成功
hdfs dfs -ls /wordcount/input
hdfs dfs -cat /wordcount/input/wcdata.txt
11.3 测试 mapreduce
计算 PI 的值
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar pi 10 10
单词统计
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /wordcount/input/wcdata.txt /wordcount/result
hdfs dfs -ls /wordcount/result
hdfs dfs -cat /wordcount/result/part-r-00000
dcount
```bash hdfs dfs -ls /wordcount/input
上传本地测试文件 wcdata.txt 到 HDFS 上 /wordcount/input
hdfs dfs -put wcdata.txt /wordcount/input
检查文件是否上传成功
hdfs dfs -ls /wordcount/input
hdfs dfs -cat /wordcount/input/wcdata.txt
11.3 测试 mapreduce
计算 PI 的值
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar pi 10 10
单词统计
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /wordcount/input/wcdata.txt /wordcount/result
hdfs dfs -ls /wordcount/result
hdfs dfs -cat /wordcount/result/part-r-00000
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们,邮箱:ciyunidc@ciyunshuju.com。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!



