
redis中的zset与B+树的区别


.png)



zset之前先了解一下set
-
介绍 : set 类似于 Java 中的 HashSet 。Redis 中的 set 类型是一种无序集合,集合中的元素没有先后顺序。当你需要存储一个列表数据,又不希望出现重复数据时,set 是一个很好的选择,并且 set 提供了判断某个成员是否在一个 set 集合内的重要接口,这个也是 list 所不能提供的。可以基于 set 轻易实现交集、并集、差集的操作。比如:你可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。Redis 可以非常方便的实现如共同关注、共同粉丝、共同喜好等功能。这个过程也就是求交集的过程。
-
常用命令: sadd,spop,smembers,sismember,scard,sinterstore,sunion 等。
-
应用场景: 需要存放的数据不能重复以及需要获取多个数据源交集和并集等场景
zset概念
-
介绍: 和 set 相比,sorted set 增加了一个权重参数 score,使得集合中的元素能够按 score 进行有序排列,还可以通过 score 的范围来获取元素的列表。有点像是 Java 中 HashMap 和 TreeSet 的结合体。
-
常用命令: zadd,zcard,zscore,zrange,zrevrange,zrem 等。
-
应用场景: 需要对数据根据某个权重进行排序的场景。比如在直播系统中,实时排行信息包含直播间在线用户列表,各种礼物排行榜,弹幕消息(可以理解为按消息维度的消息排行榜)等信息。
什么是跳表
传统链表上面增加索引,增加一层索引时,结构可以类似于哈希表,当增加多级索引时,查找的时间复杂度大大降低,这就是跳表的底层原理实现.
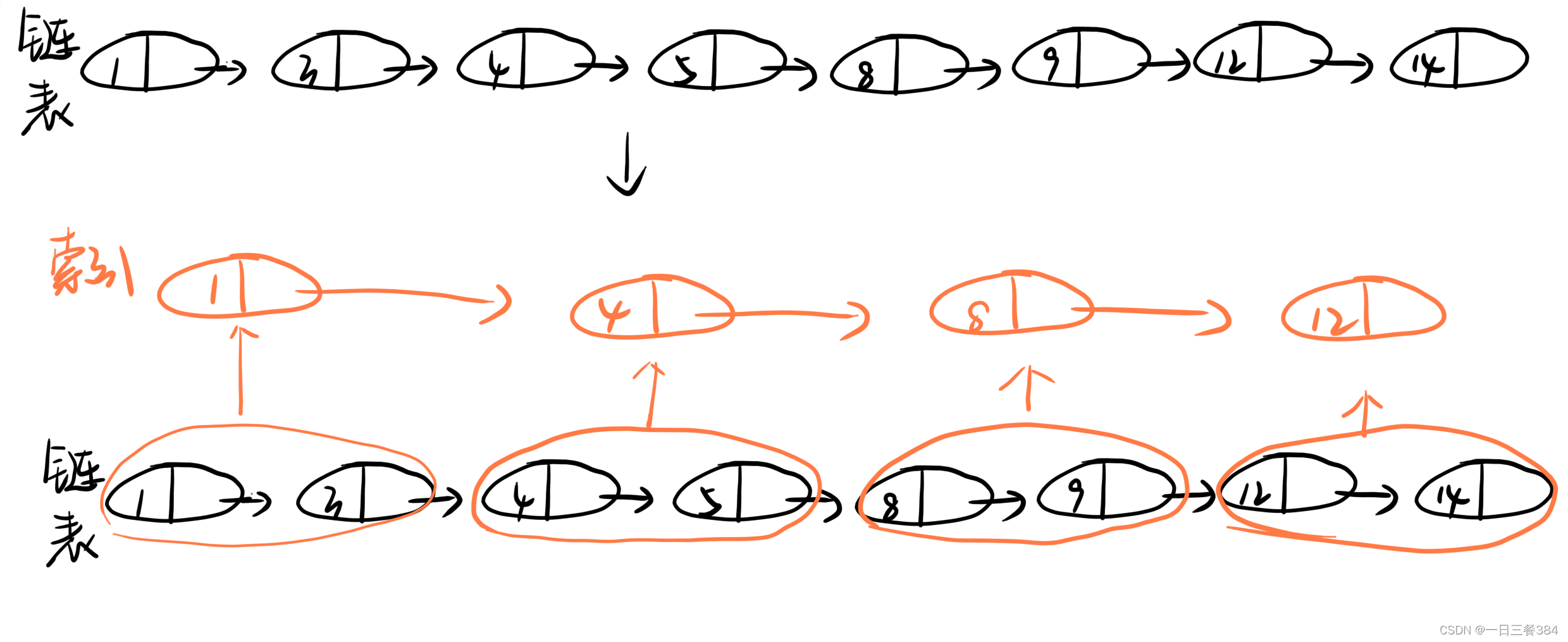
查找过程

mysql为什么采用B+树,没有采用跳表
首先说B+树的优点
1)B+树的磁盘读写代价更低
B+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B
树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了;
2)B+树查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当;
3)B+树便于范围查询(最重要的原因,范围查找是数据库的常态)
B树在提高了IO性能的同时并没有解决元素遍历的我效率低下的问题,正是为了解决这个问题,B+树应用而生。B+树只需要去遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作或者说效率太低;
B+树的节点只存储索引key值,具体信息的地址存在于叶子节点的地址中。这就使以页为单位的索引中可以存放更多的节点。减少更多的I/O支出。
为什么不选择跳表
mysql把数据存到磁盘中,我们读取需要io操作,比较矮,壮实,一次io读的就越多,越高一次io就少。
为什么b+树不是b树
b树带着数据,所以一次读取的数据量更少,b+树存储索引,那么我一次读取的数据就很多

")


")

