
算法与数据结构
温馨提示:这篇文章已超过377天没有更新,请注意相关的内容是否还可用!
算法与数据结构
前言
什么是算法和数据结构?
你可能会在一些教材上看到这句话:
程序 = 算法 + 数据结构
算法(Algorithm):是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机制。也就是说,能够对一定规范的输入,在有限时间内获得所要求的输出。(任何代码片段都可视为算法)
数据结构(Data Structures):是计算机存储和组织数据的一种方式,可以用来高效地处理数据。
什么样的程序才是好的程序?好的程序设计无外乎两点,“快"和"省”。"快"指程序执行速度快,高效,"省"指占用更小的内存空间。这两点其实就对应"时间复杂度"和"空间复杂度"的问题。
举个例子:二分查找就是一个非常经典的算法,而二分查找经常需要作用在一个有序数组上。这里二分就是一种折半的算法思想, 而数组是我们最常用的一种数据结构,支持根据下标快速访问。很多算法需要特定的数据结构来实现,所以经常把它们放到一块讲。
实际上,在真正的项目开发中,大部分时间都是 从数据库取数据 -> 数据操作和结构化 -> 返回给前端,在数据操作过程中需要合理地抽象, 组织、处理数据,如果选用了错误的数据结构,就会造成代码运行低效。这也是我们需要学习算法和数据结构的原因。
学习方法
这里我们用一种很原始的方法来学习算法:
- 阅读资料了解算法思想
- 纸笔模拟尝试理解
- 用自己熟悉的编程语言来实现
数据结构与类型
在往常我们的开发的的时候,经常使用的数据类型,或者我们自定义的类。都是可以理解成是一个抽象的数据类型(ADT: Abstract Data Type),它们泛指一类数据,他们有拥有共同的属性与方法。
举例:水杯
class glass: def __init__(self,pin_pai,size,height,color): pass实现ADT时,我们应注意什么?
- 如何选用恰当的数据结构作为存储?
- 选取的数据结构能否满足 ADT 的功能需求
- 实现效率如何?
大O表示法
大O表示法使用大写字母O,可以认为其含义为"order of"(大约是)
大O表示法可以告诉我们算法的快慢
大O比较的是操作数,它指出了算法运行时间的增速
O(n) 括号里的是操作数
理解不同的大O运行时间
画一个16个格子的网格,下面分别列举几种不同的画法,并用大O表示法表示
-
一次画一个格子。O(n)

-
折叠纸张,折叠四次就能出现16个格子。O(log n)

**注意:**大O表示法所表示的是一个算法在最糟糕情况下的运行时间
常见的大O运行时间
- O(log n),也叫对数时间,二分查找。
- O(n),也叫线性时间,简单查找。
- O(n * log n),快速排序——一种速度较快的排序算法。
- O(n²),选择排序——一种速度较慢的排序算法。
- O(n!),旅行商问题的解决方案——一种非常慢的算法。

通过图我们可以比较不同的大O值,O(1)是优秀,O(logN)是良好,O(N)是还可以,O(N^2)则很差了
主要启示
- 算法的速度指的是操作数的增速,而非时间。
- 谈论算法速度说的是随着输入的增加,其运行时间将以什么样的速度增加。
- 用大O表示法表示算法的运行时间。
- 随着元素的增加,快算法比慢算法增加的速度是指数级的。比如,O(log n)和O(n)
线性结构
本节我们从最简单和常用的线性结构开始,并结合 Python 语言本身内置的数据结构和其底层实现方式来讲解。 虽然本质上数据结构的思想是语言无关的,但是了解 Python 的实现方式有助于你避免一些坑
数组 array
数组是最常用到的一种线性结构,其实 python 内置了一个 array 模块,但是大部人甚至从来没用过它。 Python 的 array 是内存连续、存储的都是同一数据类型的结构,而且只能存数值和字符。
我建议你课下看下 array 的文档:https://docs.python.org/2/library/array.html
最常用的还是接下来要说的 list, 本节最后我们会用 list 来实现一个固定长度、并且支持所有 Python 数据类型的数组 Array.
操作 平均时间复杂度 list[index] O(1) list.append O(1) list.insert O(n) list.pop(index) O(1) list.remove O(n) 用 list 实现 Array ADT
因为在别的语言中,array是定长的,因此我们在此,通过List来实现一个定长的数组
class Array(): def __init__(self, size): self.__size = size self.__item = [None] * size def __getitem__(self, index): return self.__item[index] def __setitem__(self, key, value): self.__item[key] = value def __len__(self): return self.__size def clear(self, value=None): for i in range(len(self.__size)): self.__item[i] = value def __iter__(self): for v in self.__item: yield v if __name__ == '__main__': a = Array(10) a[0] = 10 a[2] = 20 print(len(a)) print(a.__len__())练习:
- 完成容量内容扩展
- 完在删除功能
参考:https://github.com/python/cpython
链式结构
本节我们讲解最常见的单链表和双链表。
上一节我们分析了 list 的各种操作是如何实现的,如果你还有印象的话,list 在头部进行插入是个相当耗时的操作(需要把后边的元素一个一个挪个位置)。
假如你需要频繁在数组两头增删,list 就不太合适。
今天我们介绍的链式结构将摆脱这个缺陷,当然了链式结构本身也有缺陷,比如你不能像数组一样随机根据下标访问,你想查找一个元素只能老老实实从头遍历。 所以嘛,学习和了解数据结构的原理和实现你才能准确地选择到底什么时候该用什么数据结构,而不是瞎选导致代码性能很差。
单链表
和线性结构不同,链式结构内存不连续的,而是一个个串起来的,这个时候就需要每个链接表的节点保存一个指向下一个节点的指针。 这里可不要混淆了列表和链表(它们的中文发音类似,但是列表 list 底层其实还是线性结构,链表才是真的通过指针关联的链式结构)。 看到指针你也不用怕,这里我们用的 python,你只需要一个简单赋值操作就能实现,不用担心 c 语言里复杂的指针。
先来定义一个链接表的节点,刚才说到有一个指针保存下一个节点的位置,我们叫它 next, 当然还需要一个 value 属性保存值
class Node: def __init__(self, value, next=None): self.value = value self.next = next然后就是我们的单链表 LinkedList ADT:
class LinkedList(object): """ 链接表 ADT [root] -> [node0] -> [node1] -> [node2] """来看下时间复杂度:
链表操作 平均时间复杂度 linked_list.append(value) O(1) linked_list.appendleft(value) O(1) linked_list.find(value) O(n) linked_list.remove(value) O(n) 代码实现:
class Node(): def __init__(self,value=None,next=None): self.value = value self.next = next def __str__(self): return 'Node:{}'.format(self.value) class LinkedList(): def __init__(self): self.root = Node() self.size = 0 #记录有多少元素 self.next = None #增加新数据时,将新数据的地址与谁关联 def append(self,value): node = Node(value) # 判断是否已经有数据 if not self.next: #如果没有节点时 self.root.next = node #将新节点挂到root后面 else: self.next.next = node #将新节点挂到最后一个节点上 self.next = node self.size += 1 def append_first(self,value): node = Node(value) if not self.next: self.root.next = node self.next = node else: temp = self.root.next # 获取原来root后面的那个节点 self.root.next = node # 将新的节点挂到root上 node.next = temp # 新的节点的下一个节点是原来的root后的节点 self.size += 1 def __iter__(self): current = self.root.next if current: while current is not self.next: yield current.value current = current.next yield current.value def find(self,value): for v in self.__iter__(): if v == value: return True def find2(self,value): current = self.root.next if current: while current is not self.next: if current.value == value: return current current = current.next def remove(self,value): current = self.root.next if current: while current is not self.next: if current.value == value: temp.next = current.next del current self.size -= 1 return True temp = current current = current.next if __name__ == "__main__": link = LinkedList() link.append('孙悟空') link.append('猪八戒') link.append_first('唐僧') for v in link: print(v) # print(link.find('孙悟空')) # print(link.find('六儿猕猴')) # print(link.find2('孙悟空')) # print(link.find2('六儿猕猴')) print('-'*30) link.remove('孙悟空') for v in link: print(v)双链表
上边我们亲自实现了一个单链表,但是能看到很明显的问题,单链表虽然 append 是 O(1),但是它的 find 和 remove 都是 O(n)的, 因为删除你也需要先查找,而单链表查找只有一个方式就是从头找到尾,中间找到才退出。 我们需要在一个链表里能高效的删除元素, 并把它追加到访问表的最后一个位置,这个时候单链表就满足不了了。
这里就要使用到双链表了,相比单链表来说,每个节点既保存了指向下一个节点的指针,同时还保存了上一个节点的指针。
class Node(object): # 如果节点很多,我们可以用 __slots__ 来节省内存,把属性保存在一个 tuple 而不是 dict 里 # 感兴趣可以自行搜索 python __slots__ __slots__ = ('value', 'prev', 'next') def __init__(self, value=None, prev=None, next=None): self.value, self.prev, self.next = value, prev, next对, 就多了 prev,有啥优势嘛?
- 看似我们反过来遍历双链表了。反过来从哪里开始呢?我们只要让 root 的 prev 指向 tail 节点,不就串起来了吗?
- 直接删除节点,当然如果给的是一个值,我们还是需要查找这个值在哪个节点? - 但是如果给了一个节点,我们把它拿掉,直接让它的前后节点互相指过去不就行了?哇欧,删除就是 O(1) 了,两步操作就行啦
循环双端链表操作 平均时间复杂度 cdll.append(value) O(1) cdll.appendleft(value) O(1) cdll.remove(node),注意这里参数是 node O(1) cdll.headnode() O(1) cdll.tailnode() O(1) 代码:
class Node(): def __init__(self,value=None,prev= None, next=None): self.value = value self.prev = prev self.next = next def __str__(self): return 'Node: value:{}'.format(self.value) class DoubleLinkedList(): def __init__(self): self.root = Node() self.size = 0 #记录有多少元素 self.next = None #增加新数据时,将新数据的地址与谁关联 def append(self,value): node = Node(value) # 判断是否已经有数据 if not self.next: #如果没有节点时 self.root.next = node # 将新节点挂到root后面 node.prev = self.root # 设置新节点的上一个节点为root节点 else: self.next.next = node #将新节点挂到最后一个节点上 node.prev = self.next # 设置新节点的上一个节点了,之前的最后一个节点 self.next = node # 更新最后一个节点为新加的node self.size += 1 def append_first(self,value): node = Node(value) if not self.next: node.prev = self.root # 设置新节点的上一个节点为root节点 self.next = node else: temp = self.root.next # 获取原来root后面的那个节点 node.prev = self.root # 设置新node的上一个节点为root node.next = temp # 新的节点的下一个节点是原来的root后的节点 temp.prev = node # 原来Node的上个节点是新的节点 self.root.next = node # 将新的节点挂到root上 self.size += 1 def __iter__(self): current = self.root.next if current: while current is not self.next: yield current.value current = current.next yield current.value def revese_iter(self): current = self.next #获取最后一节点 if current: while current is not self.root: yield current current = current.prev def find(self,value): for v in self.__iter__(): if v == value: return True def find2(self,value): current = self.root.next if current: while current is not self.next: if current.value == value: return current current = current.next def remove(self): if self.end is None: return -1 else: temp_node = self.root.next self.root.next = temp_node.next temp_node.next.top = self.root self.size -= 1 return 1 if __name__ == "__main__": link = DoubleLinkedList() link.append('孙悟空') link.append('猪八戒') link.append_first('唐僧') for v in link.revese_iter(): print(v)练习:
- 手动实现双端链表
- 是否可以实现循环链表
队列和栈
本节讲解的队列与栈,如果你对之前的线性和链式结构顺利掌握了,那么下边的队列和栈就小菜一碟了。因为我们会用前两节讲到的东西来实现队列和栈。 之所以放到一起讲是因为这两个东西很类似,队列是先进先出结构(FIFO, first in first out), 栈是后进先出结构(LIFO, last in first out)。
生活中的数据结构:
- 队列。没错就是咱平常排队,第一个来的第一个走
本章我们详细讲讲常用的队列
队列 Queue
如果你熟悉了上两节讲的内容,这里你会选取哪个数据结构作为队列的底层存储?
class Queue(): def __init__(self): self.item = DoubleLinkedList() def push(self, value): self.item.append(value) def pop(self): value = self.item.top_node().value self.item.remove(value) return value用数组实现队列
难道用数组就不能实现队列了吗?其实还是可以的。只不过数组是预先分配固定内存的,所以如果你知道了队列的最大长度,也是 可以用数组来实现的。
想象一下,队列就俩操作,进进出出,一进一出,pop 和 push 操作。 似乎只要两个下标 head, tail 就可以了。 当我们 push 的时候赋值并且前移 head,pop 的时候前移 tail 就可以了。你可以在纸上 模拟下试试。列队的长度就是 head-pop,这个长度必须不能大于初始化的最大程度。
如果 head 先到了数组末尾咋办?重头来呗,只要我们保证 tail 不会超过 head 就行。
head = 0,1,2,3,4 … 0,1,2,3,4 …
重头再来,循环往复,仿佛一个轮回。。。。 怎么重头来呢?看上边数组的规律你如果还想不起来用取模,估计小学数学是体育老师教的。
maxsize = 5 for i in range(100): print(i % maxsize)我们来实现一个空间有限的循环队列。ArrayQueue,它的实现很简单,但是缺点是需要预先知道队列的长度来分配内存。
class Queue: def __init__(self, maxsize=4): self.item = Array(maxsize) self.head = 0 self.end = 0 self.maxsize = maxsize def push(self, value): self.item[self.head % self.maxsize] = value self.head += 1 def pop(self): value = self.item[self.end % self.maxsize] self.end +=1 return value双端队列 Double ended Queue
你可能还听过双端队列。上边讲到的队列 队头出,尾尾进,我们如果想头部和尾巴都能进能出呢? 这就是双端队列了,如果你用过 collections.deque 模块,就是这个东西。他能高效在两头操作。
假如让你实现你能想起来嘛? 似乎我们需要一个能 append() appendleft() popleft() pop() 都是 O(1) 的数据结构。
上边我们实现 队列的 LinkedList 可以吗?貌似就差一个 pop() 最后边的元素无法实现了。 对,我们还有双端链表。它有这几个方法:
- append
- appendleft
- headnode()
- tailnode()
- remove(node)
栈 Stack
from collections import deque class Stack(): def __init__(self): self.item = deque() def add(self,value): self.item.append(value) def pop(self): return self.item.pop()练习
- 使用 python 的 deque 来实现 queue ADT 吗?
- 是否能完成循环队列
哈希表
哈希表是种数据结构,它可以提供快速的插入操作和查找操作。第一次接触哈希表时,它的优点多得让人难以置信。不论哈希表中有多少数据,插入和删除(有时包括侧除)只需要接近常量的时间即0(1)的时间级。
哈希表简单的理解:在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使每个关键字和结构中一个唯一的存储位置相对应。 哈希表最常见的例子是以学生学号为关键字的成绩表,1号学生的记录位置在第一条,10号学生的记录位置在第10条…
哈希表的工作原理
哈希表基于数组的,正因为数组创建后难于扩展某些哈希表被基本填满时,性能下降得非常严重,所以程序虽必须要清楚表中将要存储多少数据(或者准备好定期地把数据转移到更大的哈希表中,这是个费时的过程)
如何定位数据存储的位置呢?
h(key) = key % size
这里取模运算使得 h(key) 的结果不会超过数组的长度下标。我们来分别插入以下元素:
765, 431, 96, 142, 579, 226, 903, 388
先来计算下它们应用哈希函数后的结果:
size = 13 h(765) = 765 % size = 11 h(431) = 431 % size = 2 h(96) = 96 % size = 5 h(142) = 142 % size = 12 h(579) = 579 % size = 7 h(226) = 226 % size = 5 h(903) = 903 % size = 6 h(388) = 388 % size = 11
哈希冲突 (collision)
这里到插入 226 这个元素的时候,不幸地发现 h(226) = h(96) = 5,不同的 key 通过我们的哈希函数计算后得到的下标一样, 这种情况成为哈希冲突。怎么办呢?聪明的计算机科学家又想到了办法,其实一种直观的想法是如果冲突了我能不能让数组中 对应的槽变成一个链式结构呢?这就是其中一种解决方法,叫做 链接法(chaining)。如果我们用链接法来处理冲突,后边的插入是这样的:
问题,但是如果哈希函数选不好的话,可能就导致冲突太多一个链变得太长,这样查找就不再是 O(1) 的了。 还有一种叫做开放寻址法(open addressing),它的基本思想是当一个槽被占用的时候,采用一种方式来寻找下一个可用的槽。 (这里槽指的是数组中的一个位置),根据找下一个槽的方式不同,分为:
- 线性探查(linear probing): 当一个槽被占用,找下一个可用的槽。 $ h(k, i) = (h^\prime(k) + i) % m, i = 0,1,…,m-1 $
- 二次探查(quadratic probing): 当一个槽被占用,以二次方作为偏移量。 $ h(k, i) = (h^\prime(k) + c_1 + c_2i^2) % m , i=0,1,…,m-1 $
- 双重散列(double hashing): 重新计算 hash 结果。 $ h(k,i) = (h_1(k) + ih_2(k)) % m $
我们选一个简单的二次探查函数 $ h(k, i) = (home + i^2) % m $,它的意思是如果 遇到了冲突,我们就在原始计算的位置不断加上 i 的平方。我写了段代码来模拟整个计算下标的过程:
inserted_index_set = set() M = 13 def h(key, M=13): return key % M to_insert = [765, 431, 96, 142, 579, 226, 903, 388] for number in to_insert: index = h(number) first_index = index i = 1 while index in inserted_index_set: # 如果计算发现已经占用,继续计算得到下一个可用槽的位置 print('\th({number}) = {number} % M = {index} collision'.format(number=number, index=index)) index = (first_index + i*i) % M # 根据二次方探查的公式重新计算下一个需要插入的位置 i += 1 else: print('h({number}) = {number} % M = {index}'.format(number=number, index=index)) inserted_index_set.add(index)这段代码输出的结果如下:
h(765) = 765 % M = 11 h(431) = 431 % M = 2 h(96) = 96 % M = 5 h(142) = 142 % M = 12 h(579) = 579 % M = 7 h(226) = 226 % M = 5 collision h(226) = 226 % M = 6 h(903) = 903 % M = 6 collision h(903) = 903 % M = 7 collision h(903) = 903 % M = 10 h(388) = 388 % M = 11 collision h(388) = 388 % M = 12 collision h(388) = 388 % M = 2 collision h(388) = 388 % M = 7 collision h(388) = 388 % M = 1Cpython 如何解决哈希冲突
如果你对 cpython 解释器的实现感兴趣,可以参考下这个文件 dictobject.c。 不同 cpython 版本实现的探查方式是不同的,后边我们自己实现 HashTable ADT 的时候会模仿这个探查方式来解决冲突。
The first half of collision resolution is to visit table indices via this recurrence: j = ((5*j) + 1) mod 2**i For any initial j in range(2**i), repeating that 2**i times generates each int in range(2**i) exactly once (see any text on random-number generation for proof). By itself, this doesn't help much: like linear probing (setting j += 1, or j -= 1, on each loop trip), it scans the table entries in a fixed order. This would be bad, except that's not the only thing we do, and it's actually *good* in the common cases where hash keys are consecutive. In an example that's really too small to make this entirely clear, for a table of size 2**3 the order of indices is: 0 -> 1 -> 6 -> 7 -> 4 -> 5 -> 2 -> 3 -> 0 [and here it's repeating]哈希函数
到这里你应该明白哈希表插入的工作原理了,不过有个重要的问题之前没提到,就是 hash 函数怎么选? 当然是散列得到的冲突越来越小就好啦,也就是说每个 key 都能尽量被等可能地散列到 m 个槽中的任何一个,并且与其他 key 被散列到哪个槽位无关。 如果你感兴趣,可以阅读后边提到的一些参考资料。视频里我们使用二次探查函数,它相比线性探查得到的结果冲突会更少。
装载因子(load factor)
如果继续往我们的哈希表里塞东西会发生什么?空间不够用。这里我们定义一个负载因子的概念(load factor),其实很简单,就是已经使用的槽数比哈希表大小。 比如我们上边的例子插入了 8 个元素,哈希表总大小是 13, 它的 load factor 就是 $ 8/13 \approx 0.62 $。当我们继续往哈希表插入数据的时候,很快就不够用了。 通常当负载因子开始超过 0.8 的时候,就要新开辟空间并且重新进行散列了。
重哈希(Rehashing)
当负载因子超过 0.8 的时候,需要进行 rehashing 操作了。步骤就是重新开辟一块新的空间,开多大呢?感兴趣的话可以看下 cpython 的 dictobject.c 文件然后搜索 GROWTH_RATE 这个关键字,你会发现不同版本的 cpython 使用了不同的策略。python3.3 的策略是扩大为已经使用的槽数目的两倍。开辟了新空间以后,会把原来哈希表里 不为空槽的数据重新插入到新的哈希表里,插入方式和之前一样。这就是 rehashing 操作。
HashTable ADT
实践是检验真理的唯一标准,这里我们来实现一个简化版的哈希表 ADT,主要是为了让你更好地了解它的工作原理,有了它,后边实现起 dict 和 set 来就小菜一碟了。 这里我们使用到了定长数组,还记得我们在数组和列表章节里实现的 Array 吧,这里要用上了。
解决冲突我们使用二次探查法,模拟 cpython 二次探查函数的实现。我们来实现三个哈希表最常用的基本操作,这实际上也是使用字典的时候最常用的操作。
- add(key, value)
- get(key, default)
- remove(key)
class Slot(object): """定义一个 hash 表 数组的槽 注意,一个槽有三种状态,看你能否想明白 1.从未使用 HashMap.UNUSED。此槽没有被使用和冲突过,查找时只要找到 UNUSED 就不用再继续探查了 2.使用过但是 remove 了,此时是 HashMap.EMPTY,该探查点后边的元素扔可能是有key 3.槽正在使用 Slot 节点 """ def __init__(self, key, value): self.key, self.value = key, value class HashTable(object): pass具体的实现和代码编写在视频里讲解。这个代码可不太好实现,稍不留神就会有错,我们还是通过编写单元测试验证代码的正确性。
递归与栈
递归
递归是很多算法都使用的一种编程方法,具体的表现在于自己调用自己。
举例:
从前有座山,山里有座庙,庙里有个老和尚,正在给小和尚讲故事呢!故事是什么呢?"从前有座山,山里有座庙,庙里有个老和尚,正在给小和尚讲故事呢!故事是什么呢?'从前有座山,山里有座庙,庙里有个老和尚,正在给小和尚讲故事呢!故事是什么呢?……
买的礼品,包装盒子里有第二层包装盒,第二层包装盒里有第三层包装盒,第三层包装盒里有包装纸…
如上的故事翻译成伪代码如下:
def gu_shi(): print('从前有座山,山里有座庙,庙里有个老和尚,正在给小和尚讲故事呢!') gu_shi() def bao_zhuang(): print('有包装,继续拆') bao_zhuang()基线条件和递归条件
由于递归函数调用自己,因此编写这样的函数时很容出错,进而导致无线循环。例如,假设你要编写一个倒计时的函数
5…4…3…2…1
为此,我们可以用递归的方式编写,如下所示:
def count_down(i): print(i) count_donw(i-1)
如果运行上面代码,那么就会进入死循环,直到内存益处或者强制退出(Ctrl+C)
编写递归函数时,必须告诉它何时停止递归。正因为如此,每个递归函数都有两部分:基线条件 与 递归条件,递归条件指的是函数调用自己,而基线条件则指的是函数不再调用自己,从而避免形成无限循环。
修改上面的代码如下:
def count_down(i): print(i) if i array[j+1]: array[j], array[j+1] = array[j+1], array[j]选择排序(Selection sort)
选择排序(Selection sort)是一种简单直观的排序算法
算法原理
第一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,然后再从剩余的未排序元素中寻找到最小(大)元素,然后放到已排序的序列的末尾。以此类推,直到全部待排序的数据元素的个数为零。选择排序是不稳定的排序方法。
举例:
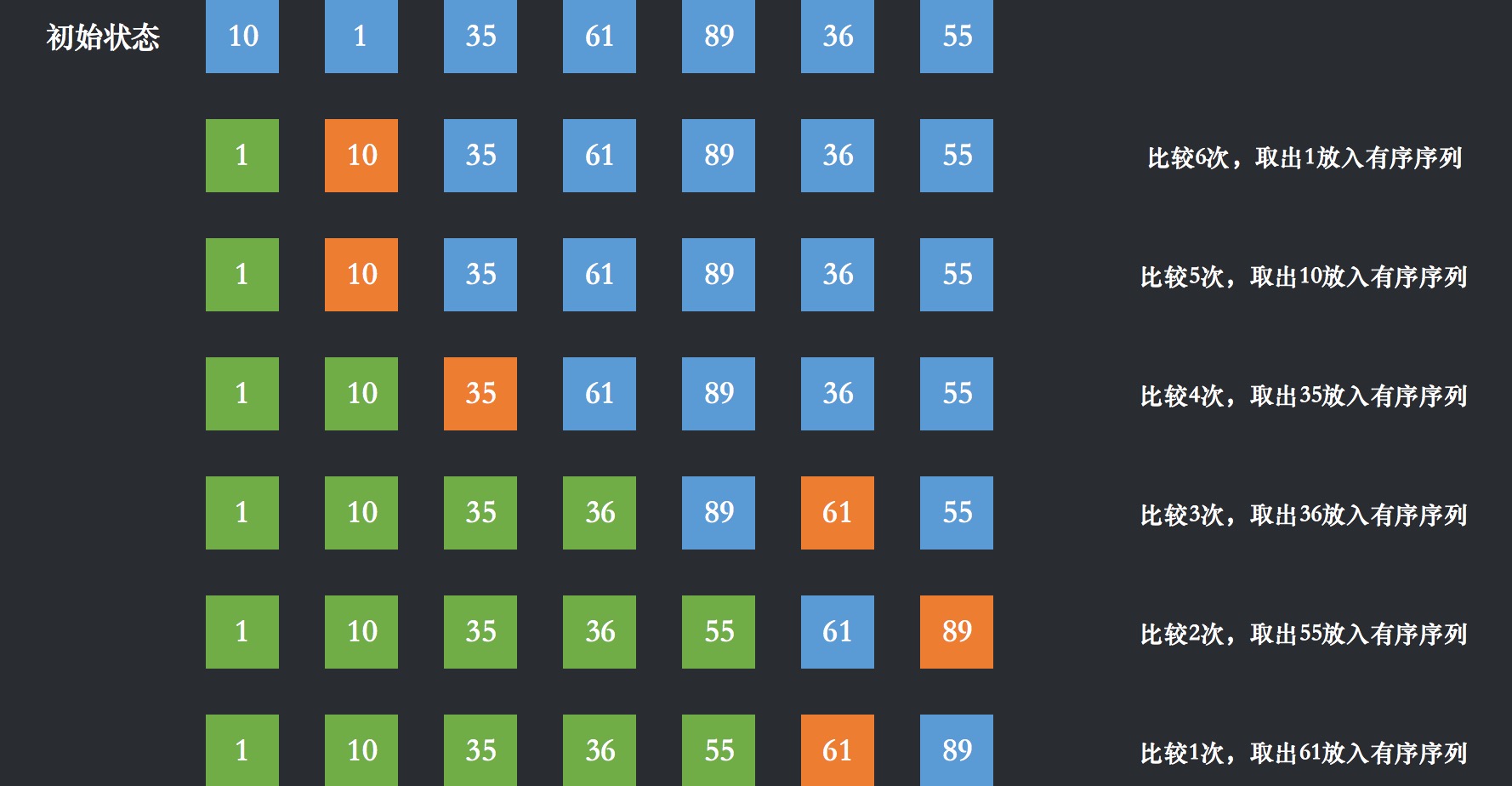
第一趟排序:所有数据中找出最小1,与第1位 10 交换位置 [1 | 10,35,61,89,36,55]
第二趟排序:[10,35,61,89,36,55] 找出最小10,放到第2位 [1,10 | 35,61,89,36,55]
第三趟排序:[35,61,89,36,55]找出最小35,放到第3位 [1,10,35 | 61,89,36,55]
第四趟排序:[61,89,36,55]找出最小36,放到第4位 [1,10,35,36 | 61,89,55]
第五趟排序:[61,89,55]找出最小55,放到第5位 [1,10,35,36,55 | 61,89]
第六趟排序:[61,89]找出最小61,放到第6位 [1,10,35,36,55,61 | 89]
第一趟总共进行了六次比较,排序结果: [1,10,35,36,55,61,89]
代码:
def selection_sort(list2): for i in range(0, len (list2)-1): min_ = i for j in range(i + 1, len(list2)): if list2[j]插入排序(Insertion sort)
插入排序(Insertion sort)是一种简单直观且稳定的排序算法
算法原理:
它的原理是 每插入一个数 都要将它 和 之前的 已经完成排序的序列进行重新排序,也就是要找到新插入的数对应原序列中的位置。那么也就是说,每次插入一个数都要对原来排序好的那部分序列进行重新的排序,时间复杂度同样为O(n²)。 这种算法是稳定的排序方法。
举例:

第一趟排序:取出第2个数据10,与第1个数据排序 [1,10 | 35,61,89,36,55]
第二趟排序:取出第3个数据35,与前2数据排序 [1,10, 35 | 61,89,36,55]
第三趟排序:取出第4个数据61,与第3个数据排序 [1,10,35,61 | 89,36,55]
第四趟排序:取出第5个数据89,与第4个数据排序 [1,10,35,61,89 | 36,55]
第五趟排序:取出第6个数据36,与第5个数据排序 [1,10,35,36, 61,89 | 55]
第六趟排序:取出第7个数据55,与第6个数据排序 [1,10,35,36,55,61,89]
第一趟总共进行了六次比较,排序结果: [1,10,35,36,55,61,89]
代码:
def insert_sort(list): for i in range(1,Length): # 默认第一个元素已经在有序序列中,从后面元素开始插入 for j in range(i,0,-1): # 逆向遍历比较,交换位置实现插入 if list[j]归并排序(Merge sort)
归并排序(Merge sort)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
算法原理
从归并排序的定义来看,其主要是归并操作,而归并操作的前提是两个已经排序的序列,所以首先需要将一个序列划分一个个有序的的序列,然后再进行归并。 它的核心思想是:先分后归(先拆分为一个个有序的子序列,再将一个个有序子序列进行归并操作最后合并为一个有序的序列)

第一次分解:将主序列分解成2个序列 [1,10,35,61] [89,36,55]
第二次分解:将2个序列分解成4个序列 [1,10] [ 35,61] [89,36] [55]
第三次分解:将4个序列分解成7个序列 [1] [10] [35] [61] [89] [36] [55]
第四次合并:将7个序列合成成4个序列,合并时排序 [1,10] [35,61] [36, 89 ] [55]
第五趟排序:将4个序列合成成2个序列,合并时排序序 [1,10, 35,61] [36, 55,89 ]
第六趟排序:将2个序列合成成1个序列,合并时排序 [1,10,35,36,55,61,89]
第一趟总共进行了六次比较,排序结果: [1,10,35,36,55,61,89]
def merge_sort(lists): if len(lists) 'data': 'A', 'left': 'B', 'right': 'C', 'is_root': True}, {'data': 'B', 'left': 'D', 'right': 'E', 'is_root': False}, {'data': 'D', 'left': None, 'right': None, 'is_root': False}, {'data': 'E', 'left': 'H', 'right': None, 'is_root': False}, {'data': 'H', 'left': None, 'right': None, 'is_root': False}, {'data': 'C', 'left': 'F', 'right': 'G', 'is_root': False}, {'data': 'F', 'left': None, 'right': None, 'is_root': False}, {'data': 'G', 'left': 'I', 'right': 'J', 'is_root': False}, {'data': 'I', 'left': None, 'right': None, 'is_root': False}, {'data': 'J', 'left': None, 'right': None, 'is_root': False}, ] } ''' { 'A':node('A','B','C') 'B:node ... } ''' for n in node_list: node = Node(n['data'], n['left'], n['right']) node_dict[n['data']] = node for n in node_list: node = node_dict[n['data']] ''' data:a left: node(b,d,e) right:c ''' if node.left: node.left = node_dict[node.left] if node.right: node.right = node_dict[node.right] if n['is_root']: self.root = nodep大功告成,这样我们就构造了一棵二叉树对象。下边我们看看它的一些常用操作。/p h4二叉树的遍历/h4 p不知道你有没有发现,二叉树其实是一种递归结构,因为单独拿出来一个 subtree 子树出来,其实它还是一棵树。那遍历它就很方便啦,我们可以直接用递归的方式来遍历它。但是当处理顺序不同的时候,树又分为三种遍历方式:/p ulli先(根)序遍历: 先处理根,之后是左子树,然后是右子树/lili中(根)序遍历: 先处理左子树,之后是根,最后是右子树/lili后(根)序遍历: 先处理左子树,之后是右子树,最后是根 p我们来看下实现,其实算是比较直白的递归函数:/p pre class="brush:python;toolbar:false" def iter_node1(self, node): if node is not None: print(node.data) self.iter_node1(node.left) self.iter_node1(node.right) /pre p怎么样是不是挺简单的,比较直白的递归函数。如果你不明白,视频里我们会画个图来说明。/p h4二叉树层序遍历/h4 p除了递归的方式遍历之外,我们还可以使用层序遍历的方式。层序遍历比较直白,就是从根节点开始按照一层一层的方式遍历节点。 我们可以从根节点开始,之后把所有当前层的孩子都按照从左到右的顺序放到一个列表里,下一次遍历所有这些孩子就可以了。/p pre class="brush:python;toolbar:false" def iter_node2(self, node): node_list = [node] for node in node_list: print(node.data) if node.left: node_list.append(node.left) if node.right: node_list.append(node.right) /pre p还有一种方式就是使用一个队列,之前我们知道队列是一个先进先出结构,如果我们按照一层一层的顺序从左往右把节点放到一个队列里, 也可以实现层序遍历:/p pre class="brush:python;toolbar:false"def layer_trav_use_queue(self, subtree): q = Queue() q.append(subtree) while not q.empty(): cur_node = q.pop() print(cur_node.data) if cur_node.left: q.append(cur_node.left) if cur_node.right: q.append(cur_node.right) from collections import deque class Queue(object): # 借助内置的 deque 我们可以迅速实现一个 Queue def __init__(self): self._items = deque() def append(self, value): return self._items.append(value) def pop(self): return self._items.popleft() def empty(self): return len(self._items) == 0 /pre h4反转二叉树/h4 pre class="brush:python;toolbar:false" def reverse(self, subtree): if subtree is not None: subtree.left, subtree.right = subtree.right, subtree.left self.reverse(subtree.left) self.reverse(subtree.right) /pre h3堆(heap)/h3 h4什么是堆?/h4 p堆是一种完全二叉树(请你回顾下上一章的概念),有最大堆和最小堆两种。/p ulli最大堆: 对于每个非叶子节点 V,V 的值都比它的两个孩子大,称为 最大堆特性(heap order property) 最大堆里的根总是存储最大值,最小的值存储在叶节点。/lili最小堆:和最大堆相反,每个非叶子节点 V,V 的两个孩子的值都比它大。 pimg src="https://img-blog.csdnimg.cn/img_convert/2318c02d8179a26b31ad8d4f3f1b0c96.png" //p h4堆的操作/h4 p堆提供了很有限的几个操作:/p ulli插入新的值。插入比较麻烦的就是需要维持堆的特性。需要 sift-up 操作,具体会在视频和代码里解释,文字描述起来比较麻烦。/lili获取并移除根节点的值。每次我们都可以获取最大值或者最小值。这个时候需要把底层最右边的节点值替换到 root 节点之后 执行 sift-down 操作。 pimg src="https://img-blog.csdnimg.cn/img_convert/ca43b3dd37d2b6479ebd253824b6a28f.png" //p pimg src="https://img-blog.csdnimg.cn/img_convert/d1abaf52a5cbcdbbd18e84e492a4919e.png" //p p/p h4堆的表示/h4 p之前我们用一个节点类和二叉树类表示树,这里其实用数组就能实现堆。/p pimg src="https://img-blog.csdnimg.cn/img_convert/5141721b35b5462caedb6089177a8ec4.png" //p p仔细观察下,因为完全二叉树的特性,树不会有间隙。对于数组里的一个下标 i,我们可以得到它的父亲和孩子的节点对应的下标:/p pre class="brush:python;toolbar:false"parent = int((i-1) / 2) # 取整 left = 2 * i + 1 right = 2 * i + 2 /pre p超出下标表示没有对应的孩子节点。/p h4实现一个最大堆/h4 pre class="brush:python;toolbar:false"class Heap: def __init__(self): self.items = Array(8) self.count = 0 def add(self, value): # 根据count来决定将值暂时赋值到哪块空间 self.items[self.count] = value # 为了保证下一个数据添加时,不替换上一个添加所在的索引的值 self.count += 1 # 将本次添加的数据的索引传到 提权函数中 self.sift_up(self.count - 1) def sift_up(self, index): if index = 0: return else: parent = (index - 1) / 2 if self.items[parent] = self.items[index]: self.items[parent], self.items[index] = self.items[index], self.items[parent] self.sift_up(parent) def remove(self): value = self.items[0] self.count -= 1 self.items[0] = self.items[self.count] self.items[self.count] = None self.sift_down(0) return value def sift_down(self, index): left = index * 2 + 1 right = index * 2 + 2 largest = index if right self.item[largest]: largest = left elif left self.item[largest]: largest = left if largest != index: self.item[index],self.item[largest] = self.item[largest],self.item[index] self.siftdown(largest) def __iter__(self): for i in self.items: if i is not None: yield i实现堆排序
上边我们实现了最大堆,每次我们都能 extract 一个最大的元素了,于是一个倒序排序函数就能很容易写出来了:
def heapsort_reverse(array): length = len(array) maxheap = MaxHeap(length) for i in array: maxheap.add(i) res = [] for i in range(length): res.append(maxheap.extract()) return res def test_heapsort_reverse(): import random l = list(range(10)) random.shuffle(l) assert heapsort_reverse(l) == sorted(l, reverse=True)Python 里的 heapq 模块
python 其实自带了 heapq 模块,用来实现堆的相关操作,原理是类似的。请你阅读相关文档并使用内置的 heapq 模块完成堆排序。 一般我们刷题或者写业务代码的时候,使用这个内置的 heapq 模块就够用了,内置的实现了是最小堆。
Top K 问题(扩展)
面试题中有这样一类问题,让求出大量数据中的top k 个元素,比如一亿个数字中最大的100个数字。 对于这种问题有很多种解法,比如直接排序、mapreduce、trie 树、分治法等,当然如果内存够用直接排序是最简单的。 如果内存不够用呢? 这里我们提一下使用固定大小的堆来解决这个问题的方式。
一开始的思路可能是,既然求最大的 k 个数,是不是应该维护一个包含 k 个元素的最大堆呢? 稍微尝试下你会发现走不通。我们先用数组的前面 k 个元素建立最大堆,然后对剩下的元素进行比对,但是最大堆只能每次获取堆顶 最大的一个元素,如果我们取下一个大于堆顶的值和堆顶替换,你会发现堆底部的小数一直不会被换掉。如果下一个元素小于堆顶 就替换也不对,这样可能最大的元素就被我们丢掉了。
相反我们用最小堆呢? 先迭代前 k 个元素建立一个最小堆,之后的元素如果小于堆顶最小值,跳过,否则替换堆顶元素并重新调整堆。你会发现最小堆里 慢慢就被替换成了最大的那些值,并且最后堆顶是最大的 topk 个值中的最小值。 (比如1000个数找10个,最后堆里剩余的是 [990, 991, 992, 996, 994, 993, 997, 998, 999, 995],第一个 990 最小)
按照这个思路很容易写出来代码:
import heapq class TopK: """获取大量元素 topk 大个元素,固定内存 思路: 1. 先放入元素前 k 个建立一个最小堆 2. 迭代剩余元素: 如果当前元素小于堆顶元素,跳过该元素(肯定不是前 k 大) 否则替换堆顶元素为当前元素,并重新调整堆 """ def __init__(self, iterable, k): self.minheap = [] self.capacity = k self.iterable = iterable def push(self, val): if len(self.minheap) >= self.capacity: min_val = self.minheap[0] if val min_val操作,这里我只是显示指出跳过这个元素 pass else: heapq.heapreplace(self.minheap, val) # 返回并且pop堆顶最小值,推入新的 val 值并调整堆 else: heapq.heappush(self.minheap, val) # 前面 k 个元素直接放入minheap def get_topk(self): for val in self.iterable: self.push(val) return self.minheap def test(): import random i = list(range(1000)) # 这里可以是一个可迭代元素,节省内存 random.shuffle(i) _ = TopK(i, 10) print(_.get_topk()) # [990, 991, 992, 996, 994, 993, 997, 998, 999, 995] if __name__ == '__main__': test()二叉查找树(BST)
二叉树的一种应用就是来实现堆,我们再看看用二叉查找树(Binary Search Tree, BST)。 前面有章节说到了查找操作,包括线性查找、二分查找、哈希查找等,线性查找效率比较低,二分又要求必须是有序的序列, 为了维持有序插入的代价比较高、哈希查找效率很高但是浪费空间。能不能有一种插入和查找都比较快的数据结构呢?二叉查找树就是这样一种结构,可以高效地插入和查询节点。
BST 定义
二叉查找树是这样一种二叉树结构,它的每个节点的左子节点小于该节点,每个节点的右子节点小于该节点
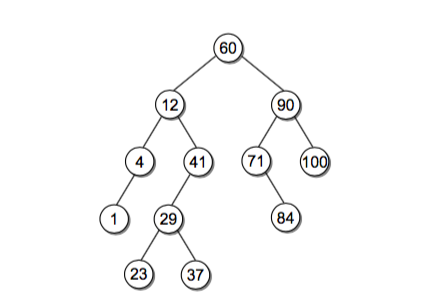
我们先来定义一下 BST 的节点结构:
class BSTNode(object): def __init__(self, data, left=None, right=None): self.data, self.left, self.right = data, left, right构造一个 BST
我们还像之前构造二叉树一样,按照上图构造一个 BST 用来演示:
class BST(object): def __init__(self, root=None): self.root = root @classmethod def build_from(cls, node_list): cls.size = 0 key_to_node_dict = {} for node_dict in node_list: key = node_dict['key'] key_to_node_dict[key] = BSTNode(key) for node_dict in node_list: key = node_dict['key'] node = key_to_node_dict[key] if node_dict['is_root']: root = node node.left = key_to_node_dict.get(node_dict['left']) node.right = key_to_node_dict.get(node_dict['right']) cls.size += 1 return cls(root) NODE_LIST = [ {'key': 60, 'left': 12, 'right': 90, 'is_root': True}, {'key': 12, 'left': 4, 'right': 41, 'is_root': False}, {'key': 4, 'left': 1, 'right': None, 'is_root': False}, {'key': 1, 'left': None, 'right': None, 'is_root': False}, {'key': 41, 'left': 29, 'right': None, 'is_root': False}, {'key': 29, 'left': 23, 'right': 37, 'is_root': False}, {'key': 23, 'left': None, 'right': None, 'is_root': False}, {'key': 37, 'left': None, 'right': None, 'is_root': False}, {'key': 90, 'left': 71, 'right': 100, 'is_root': False}, {'key': 71, 'left': None, 'right': 84, 'is_root': False}, {'key': 100, 'left': None, 'right': None, 'is_root': False}, {'key': 84, 'left': None, 'right': None, 'is_root': False}, ] bst = BST.build_from(NODE_LIST)BST 操作
查找
如何查找一个指定的节点呢,根据定义我们知道每个内部节点左子树的 key 都比它小,右子树的 key 都比它大,所以 对于带查找的节点 search_key,从根节点开始,如果 search_key 大于当前 key,就去右子树查找,否则去左子树查找。 一直到当前节点是 None 了说明没找到对应 key。

好,撸代码:
def _bst_search(self, subtree, key): if subtree is None: # 没找到 return None elif key subtree.data: return self._bst_search(subtree.right, key) else: return subtree def get(self, key, default=None): node = self._bst_search(self.root, key) if node is None: return default else: return node.value获取最大和最小 key 的节点
其实还按照其定义,最小值就一直向着左子树找,最大值一直向右子树找,递归查找就行。
def _bst_min_node(self, subtree): if subtree is None: return None elif subtree.left is None: # 找到左子树的头 return subtree else: return self._bst_min_node(subtree.left) def bst_min(self): node = self._bst_min_node(self.root) return node.value if node else None插入
插入节点的时候我们需要一直保持 BST 的性质,每次插入一个节点,我们都通过递归比较把它放到正确的位置。 你会发现新节点总是被作为叶子结点插入。(请你思考这是为什么)

def _bst_insert(self, subtree, data): """ 插入并且返回根节点 :param subtree: :param key: :param value: """ if subtree is None: # 插入的节点一定是根节点,包括 root 为空的情况 subtree = BSTNode(data) elif data subtree.data: subtree.right = self._bst_insert(subtree.right,data) return subtree def add(self, data): node = self._bst_search(self.root, data) if node is not None: # 更新已经存在的 key return False else: self.root = self._bst_insert(self.root, data) self.size += 1 return True删除节点
删除操作相比上边的操作要麻烦很多,首先需要定位一个节点,删除节点后,我们需要始终保持 BST 的性质。 删除一个节点涉及到三种情况:
- 节点是叶节点
- 节点有一个孩子
- 节点有两个孩子
我们分别来看看三种情况下如何删除一个节点:
删除叶节点
这是最简单的一种情况,只需要把它的父亲指向它的指针设置为 None 就好。
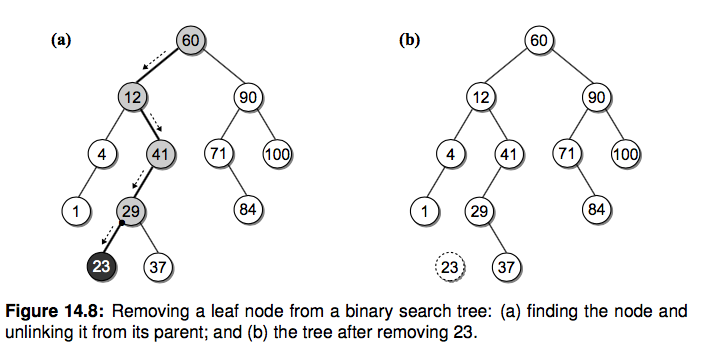
删除只有一个孩子的节点
删除有一个孩子的节点时,我们拿掉需要删除的节点,之后把它的父亲指向它的孩子就行,因为根据 BST 左子树都小于节点,右子树都大于节点的特性,删除它之后这个条件依旧满足。

删除有两个孩子的内部节点
假如我们想删除 12 这个节点改怎么做呢?你的第一反应可能是按照下图的方式:

但是这种方式可能会影响树的高度,降低查找的效率。这里我们用另一种非常巧妙的方式。 还记得上边提到的吗,如果你中序遍历 BST 并且输出每个节点的 key,你会发现就是一个有序的数组。 [1 4 12 23 29 37 41 60 71 84 90 100]。这里我们定义两个概念,逻辑前任(predecessor)和后继(successor),请看下图:
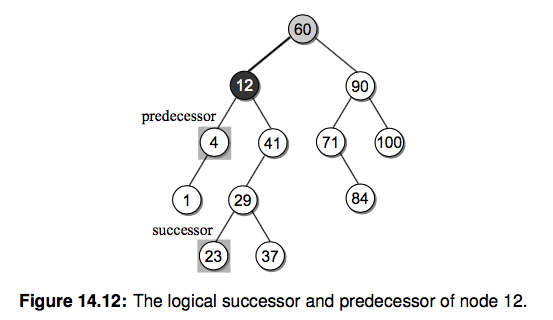
12 在中序遍历中的逻辑前任和后继分别是 4 和 23 节点。于是我们还有一种方法来删除 12 这个节点:
- 找到待删除节点 N(12) 的后继节点 S(23)
- 复制节点 S 到节点 N
- 从 N 的右子树中删除节点 S,并更新其删除后继节点后的右子树
说白了就是找到后继并且替换,这里之所以能保证这种方法是正确的,你会发现替换后依旧是保持了 BST 的性质。 有个问题是如何找到后继节点呢?待删除节点的右子树的最小的节点不就是后继嘛,上边我们已经实现了找到最小 key 的方法了。
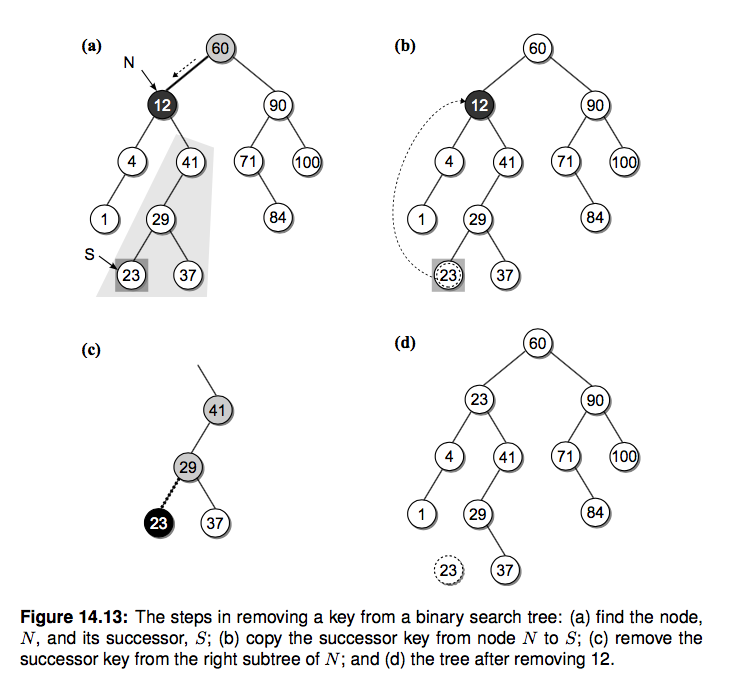
我们开始编写代码实现,和之前的操作类似,我们还是通过辅助函数的形式来实现,这个递归函数会比较复杂,请你仔细理解:
def _bst_remove(self, subtree, key): """删除节点并返回根节点""" if subtree is None: return None elif key subtree.key: subtree.right = self._bst_remove(subtree.right, key) return subtree else: # 找到了需要删除的节点 if subtree.left is None and subtree.right is None: # 叶节点,返回 None 把其父亲指向它的指针置为 None return None elif subtree.left is None or subtree.right is None: # 只有一个孩子 if subtree.left is not None: return subtree.left # 返回它的孩子并让它的父亲指过去 else: return subtree.right else: # 俩孩子,寻找后继节点替换,并从待删节点的右子树中删除后继节点 successor_node = self._bst_min_node(subtree.right) subtree.key, subtree.value = successor_node.key, successor_node.value subtree.right = self._bst_remove(subtree.right, successor_node.key) return subtree def remove(self, key): assert key in self self.size -= 1 return self._bst_remove(self.root, key)延伸阅读
- 《Data Structures and Algorithms in Python》14 章,树的概念和算法还有很多,我们这里介绍最基本的帮你打个基础
- 了解红黑树。普通二叉查找树有个很大的问题就是难以保证树的平衡,极端情况下某些节点可能会非常深,导致查找复杂度大幅退化。而平衡二叉树就是为了解决这个问题。请搜索对应资料了解下。
- 了解 mysql 索引使用的 B-Tree 结构(多路平衡查找树),这个是后端面试数据库的常考点。想想为什么?当元素非常多的时候,二叉树的深度会很深,导致多次磁盘查找。从B树、B+树、B*树谈到R 树
Leetcode
验证是否是合法二叉搜索树 [validate-binary-search-tree](https://leetcode.com/problems/validate-binary-search-tree/
-



