
基于神经网络的文本分类方法研究
温馨提示:这篇文章已超过604天没有更新,请注意相关的内容是否还可用!
和预训练模型等主流方法在文本分类中应用的发展历史,基于常用数据集比较不同模型的分类效果,表明利用人工神经网络结构自动获取文本特征可以避免复杂的人工特征工程,使得文本分类的效果得到了提高。在此基础上,对文本分类的未来研究方向进行了展望。基于神经网络的文本分类方法研究:J). 计算机工程,2020,46:11-17。
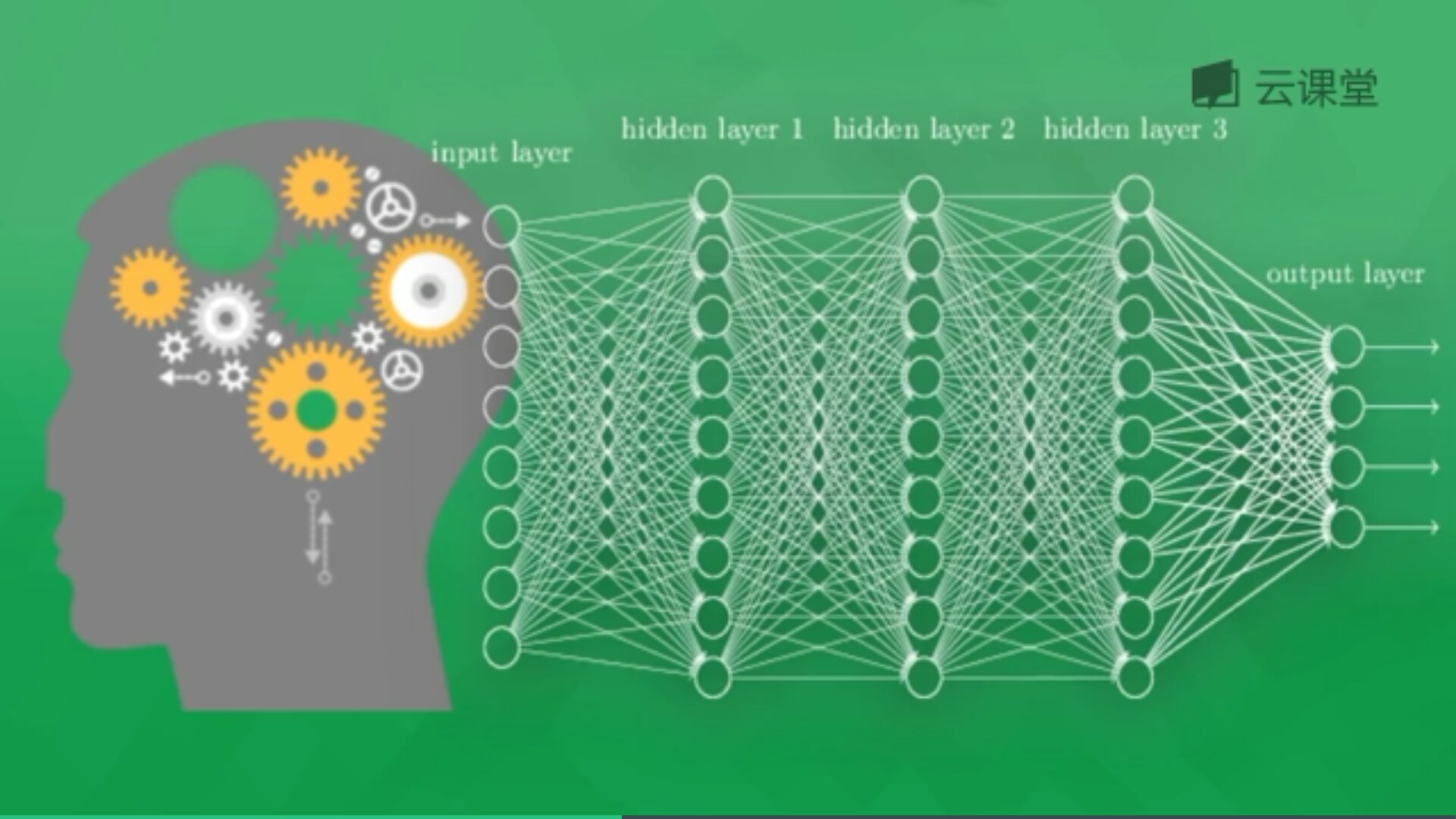
2020 年 3 月 CTL 分类号:TP391 Volume 46 Issue 3 Vol. 46期第3期-热点与综述-计算机工程计算机工程文章编号:1000-3428(2020)03-0011-07文档识别码:基于神经网络的文本分类方法研究王志辉、王晓东(工学院)国防科学技术大学计算机学院,长沙410072) 摘要:海量文本分析是实现大数据理解和价值发现的重要手段,其中文本分类是自然语言处理的经典之作。 该问题引起了研究人员的广泛关注,人工神经网络在文本分析中的优异表现使其成为目前的主要研究方向。 # 在此背景下,介绍了卷积神经网络、时间循环神经网络、结构循环神经网络。 和预训练模型等主流方法在文本分类中应用的发展历史,基于常用数据集比较不同模型的分类效果,表明利用人工神经网络结构自动获取文本特征可以避免复杂的人工特征工程,使得文本分类的效果得到了提高。 在此基础上,对文本分类的未来研究方向进行了展望。 关键词:大数据; 自然语言处理; 文本分类; 神经网络; 文本分析开放科学(资源服务) 识别码(OSID): : |||||中文引文格式:王智慧、王晓东。 基于神经网络的文本分类方法研究:J). 计算机工程,2020,46(3):11-17。 英文引文格式:王志辉,王晓东。 基于神经网络的文本分类方法研究[J]. 计算机工程, 2020, 46 (3): 11-17. 基于神经网络的文本分类方法研究王志辉,王晓东 (国防科学技术大学计算科学与技术学院, 长沙 410072) +摘要] 大规模文本分析是理解和发现大数据价值的重要手段。 Hencc文本分类作为一个经典的自然语言处理问题,受到了研究者的广泛关注,其中人工神经网络因其在文本分析方面的优异表现而成为其主要研究方向。 该论文介绍了卷积神经网络(CNN)、递归神经网络(RNN)的原理、递归神经网络结构以及应用于文本分类的预训练模型。 然后本文基于公共数据集比较了不同模型的分类性能,证明人工神经网络结构可以通过自动获取文本特征来减少人工表征工作,从而提高文本分类效果。 在此基础上,本文展望了文本分类未来的研究方向。+ 关键词] 大数据; 自然语言处理; txt; 神经网络; 分类文本分析DOI::10 . 19678/j。 刊号。 1000-3428.00537480 概述 大数据时代背景下,网络中积累的历史数据,以及数亿网民每天产生的新数据,造成了互联网数据规模的爆发式增长。 这包括多种数据形式,例如文本数据、声音数据、图像数据等。

在各类数据中,文本数据所占比例最大,数量也最多。 如何处理和利用海量文本数据显得尤为重要。 虽然此类数据量巨大,但如果简单存储并不能产生实际价值。 同时,并非所有文本都具有实际价值或对特定用户有意义。 因此,海量文本分析是实现大数据理解的重要一步和价值发现的重要手段。 。 人工神经网络技术是从信息处理的角度对人脑神经元进行抽象,建立简单的模型,根据不同的连接方式形成不同的网络的技术。 研究人员在 20 世纪 40 年代建立了神经网络及其数学模型,随后提出了感知器等更完整的神经网络模型# # 随着研究的进一步深入,研究人员后来提出了性能更好的 Hopfield 网络模型,以及多神经网络的学习算法层前馈神经网络,推动了人工神经网络的发展,并使其在众多领域得到成功应用##面对海量文本数据分析的需求以及人工神经网络技术快速发展和广泛应用的现状,基于人工神经基金项目:国防科技重点实验室基金“目标引导的社交网络多模态数据分析”(6142110180405)。 作者简介:王志辉(1994-),男,硕士研究生,研究方向为自然语言处理; 王晓东,研究员,博士生导师 收稿日期:2019-01-21 修改日期:2019-04-03 E-mail:
纱线概述
Yarn是一个资源调度平台,负责为计算程序提供服务器计算资源。 它相当于一个分布式操作系统平台,而mapreduce等计算程序相当于运行在操作系统上的应用程序。
重要概念:
1)Yarn不知道用户提交的程序的运行机制;
2)Yarn只提供计算资源的调度(用户程序向Yarn申请资源,Yarn负责分配资源);
3)Yarn中的supervisor角色称为ResourceManager;
4)Yarn中专门提供计算资源的角色称为NodeManager;
5)这样,Yarn实际上与运行的用户程序完全解耦,这意味着Yarn上可以运行各种类型的分布式计算程序(mapreduce只是其中之一),例如mapreduce、storm程序、spark程序。 ...;
6)因此,spark、storm等计算框架都可以集成并运行在Yarn上,只要各自的框架具有符合Yarn规范的资源请求机制;
7)Yarn成为通用资源调度平台。 从此,企业原有的各种计算集群都可以集成在一个物理集群上,提高资源利用率,方便数据共享。
纱线基础设施

Hadoop--Yarn 基础设施.png
从YARN的架构图来看,它主要由ResourceManager、NodeManager、ApplicationMaster和Container等以下组件组成。
1)资源管理器(RM)
YARN层次结构的本质是ResourceManager。 该实体控制整个集群并管理应用程序到底层计算资源的分配。 ResourceManager 将各种资源部分(计算、内存、带宽等)编排到底层 NodeManager(YARN 的每节点代理)。 ResourceManager 还与 ApplicationMaster 一起分配资源,并与 NodeManager 一起启动和监控其底层应用程序。 在这种情况下,ApplicationMaster 承担了之前 TaskTracker 的一些角色,ResourceManager 承担了 JobTracker 的角色。
总的来说,RM有以下功能
(1) 处理客户端请求
(2)启动或监控ApplicationMaster
(3)监控节点管理器
(4)资源分配与调度
2) 应用大师(AM)
ApplicationMaster 管理 YARN 中运行的每个应用程序实例。 ApplicationMaster负责协调来自ResourceManager的资源,并通过NodeManager监控容器的执行和资源使用情况(CPU、内存等资源分配)。 请注意,虽然当前的资源较为传统(CPU 内核、内存),但未来将根据手头的任务带来新的资源类型(例如图形处理单元或专用处理设备)。 从YARN的角度来看,ApplicationMaster是用户代码,因此存在潜在的安全问题。 YARN 假定 ApplicationMaster 有错误甚至是恶意的,因此将它们视为非特权代码。
一般来说,AM有以下作用
(1)负责数据分割
(2)为应用程序申请资源并分配给内部任务
(3)任务监控与容错
3)节点管理器(NM)
NodeManager管理YARN集群中的每个节点。 NodeManager 为集群中的每个节点提供服务,从监督容器的生命周期管理到监控资源和跟踪节点健康状况。 MRv1通过槽管理Map和Reduce任务的执行,而NodeManager管理代表特定应用程序可用的每节点资源的抽象容器。
总的来说,NM有以下作用
(1)管理单节点资源
(2) 处理来自ResourceManager的命令
(3) 处理来自ApplicationMaster的命令
4) 容器
Container是YARN中的资源抽象。 它封装了节点上的多维资源,如内存、CPU、磁盘、网络等。当AM向RM申请资源时,RM返回给AM的资源以Containers表示。 YARN为每个任务分配一个Container,任务只能使用Container中描述的资源。
一般来说,Container有以下功能
抽象任务运行环境,封装CPU、内存等多维资源以及环境变量、启动命令等任务运行相关信息。
要使用 YARN 集群,您首先需要发出包含您的应用程序的客户端请求。 ResourceManager 协商容器所需的资源,并启动一个 ApplicationMaster 来代表提交的应用程序。 使用资源请求协议,ApplicationMaster 协商每个节点上的资源容器以供应用程序使用。 当应用程序执行时,ApplicationMaster 会监视容器直至完成。 当应用程序完成时,ApplicationMaster从ResourceManager中取消注册其容器,并且执行周期完成。
通过上面的解释应该清楚了,旧的Hadoop架构受到JobTracker的高度约束,JobTracker负责整个集群的资源管理和作业调度。 新的 YARN 架构打破了这种模式,允许新的 ResourceManager 管理跨应用程序的资源使用情况,并允许 ApplicationMaster 管理作业执行。 这一变化消除了瓶颈,还提高了将 Hadoop 集群扩展到比以前更大的配置的能力。 此外,与传统的MapReduce不同,YARN允许在执行各种编程模型时使用MPI(消息传递接口)等标准通信模式,包括图形处理、迭代处理、机器学习和通用集群计算。

Yarn的工作机制
Hadoop--Yarn工作机制.png
纱线的详细工作机理
(0) Mr程序提交到客户端所在节点
(1)Yarnrunner向Resourcemanager申请Application。
(2) rm 返回应用程序的资源路径给yarnrunner
(3)程序向HDFS提交运行所需的资源
(4)程序资源提交后,申请运行mrAppMaster
(5) RM将用户的请求初始化为任务
(6)其中一台NodeManager接收任务任务。
(7)NodeManager创建容器Container并生成MRAppmaster
(8)容器将资源从HDFS复制到本地
(9)MRAppmaster申请RM运行maptask容器
(10)RM将运行maptask的任务分配给另外两个NodeManager,另外两个NodeManager分别接收任务并创建容器。
(11)MR将程序启动脚本发送给接收任务的两个NodeManager,两个NodeManager分别启动maptask,maptask对数据分区进行排序。
(12)MRAppmaster向RM申请2个容器,并运行reduce任务。
(13)reduce任务从maptask中获取对应分区的数据。
(14) 程序运行结束后,MR会将自身注销到RM。
请注意——本文根据网络资料整理。 如有雷同,纯属抄袭李小莉。 如有侵权,请联系删除 来自李小莉



