
DALLE2-文本图像生成
文章目录
- 摘要
- 算法
- 解码器
- prior
- 图像处理
- 变体
- 插值
- 文本差异
- 限制
论文: 《Hierarchical Text-Conditional Image Generation with CLIP Latents》
github: https://github.com/lucidrains/DALLE2-pytorch
https://github.com/LAION-AI/dalle2-laion
摘要
CLIP已经被证明可以学习语义或风格表征,作者提出二阶段模型,给出文本描述,利用先验模型生成CLIP图像嵌入,解码器利用图像嵌入生成图像;解码器作者使用扩散模型;prior作者使用自回归及扩散模型,发现后者计算高效,生成样本质量高。
算法
( x , y ) (x,y) (x,y)表示图像及对应caption, z i 、 z t z_i、z_t zi、zt为CLIP提取图像特征及文本特征;
DALLE2生成过程使用两个组件:
1、prior P ( z i ∣ y ) P(z_i|y) P(zi∣y)基于caption y y y生成图像编码 z i z_i zi;
2、decoder P ( x ∣ z i , y ) P(x|z_i, y) P(x∣zi,y)基于CLIP提取图像编码 z i z_i zi生成图像x,可选择使用caption y;
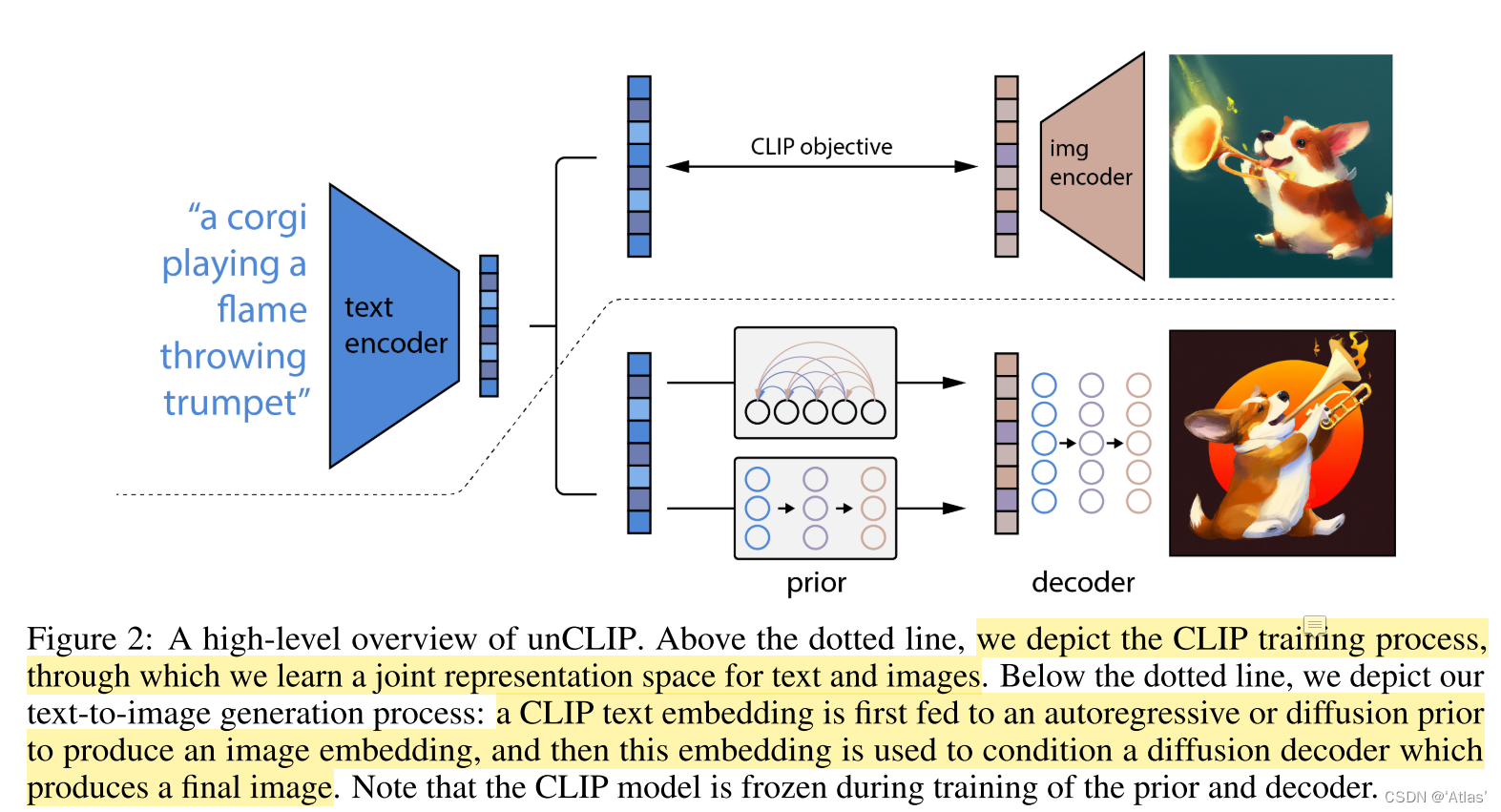
DALLE2文本图像生成过程如图2:
1、CLIP将文本进行编码,通过自回归或扩散模型(prior)生成图像编码先验,
2、图像编码通过扩散模型解码器(decoder)生成最终图像
解码器
作者使用扩散模型基于CLIP所生成的图像embedding生成图像,具体使用改进GLIDE,将CLIP embedding添加进timestep embedding中,映射CLIP embedding为4个额外token,与GLIDE文本编码器输出进行concat;
prior
解码器可将CLIP图像embedding z i z_i zi生成图像x,先验器将caption y生成图像embedding z i z_i zi;有两种方案:
1、AR(自回归先验):使用CLIP将图像embedding z i z_i zi转换为离散序列,基于caption y进行自回归预测;
2、扩散先验;基于caption y使用高斯扩散模型对连续向量 z i z_i zi进行直接建模;
DALLE2中扩散先验,作者训练仅包含解码器的Transformer,其使用包括因果关系的mask在序列上进行:文本编码、CLIP文本embedding、扩散模型timestep embedding、噪声CLIP image embedding、最终Transformer输出embedding.
图像处理
变体
对于表征$(z_i,x_T)通过超参控制采样,η=0,则为重构原图,η越大引入更大随机性,如图3;

插值
如图4,对于两张图片x1,x2,通过CLIP进行编码 z i 1 , z i 2 z_{i1},z_{i2} zi1,zi2,两者进行插值;

文本差异
对于两文本输入通过CLIP进行编码 z t , z t 0 z_t,z_{t0} zt,zt0,计算向量差异zd,对 z i 、 z d z_i、z_d zi、zd进行插值得到CLIP表征;

限制
1、DALLE2相对于GLIDE容易忽视两目标各自属性;

2、 解码器容易混合目标属性

3、难以生成连续文本




