
labelme标注的json文件转yolo格式
labelme标注的json文件是在数据标注时产生,不能直接应用于模型训练。各大目标检测训练平台或项目框架均有自己的数据格式要求,通常为voc、coco或yolo格式。由于yolov8项目比较火热,故此本博文详细介绍将json格式标注转化为yolo格式的过程及其代码。
1、数据结构
1.1 labelme(json) 数据格式
Labelme (json)数据存储结构如下图所示:
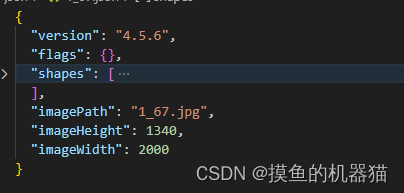
Shape:是一个数组,存储了所有的标签及对应的框;
imagePath: 图片路径,json文件和jpg图片 存储在同一路径下
imageHeight:图片的高
imageWidth:图片的宽
Shape 是一个数组,里面存储的是字典,具体存储内容如下所示:
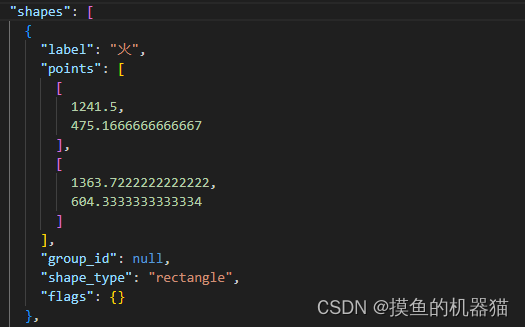
Label: 标签类别
Points: 标签标注的起点和终点
Shape_type: rectangle表示矩形
1.2 yolo数据格式
数据格式及数据示意
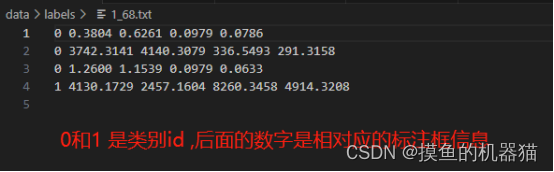
其文件格式没有固定的要求(通常情况下images存放原图;labels存放txt标签位置),基本数据格式如下图所示:

Txt文件结构信息描述
Txt标签的格式为,{目标类别id} {归一化后的目标中心点x坐标} {归一化后的目标中心点y坐标} {归一化后的目标框宽度w} {归一化后的目标框高度h}。与其他数据不同的是,yolo标签只有类别id,并无具体类别名称。此外,其以相对尺寸描述标注框的xywh信息,不受图像尺寸改变的影响。
2、转换代码
2.1代码逻辑说明
json2yolo实现了将json格式的标注转化为yolo格式。Json格式的特点是以str形式的name描述标注框的类别,而yolo格式直接以类别id描述标注框的类别。在json标注中,每个标注框都是绝对坐标格式,具体为x1,y1,x2,y2(x1,y1为标注框的起点,x2,y2为标注框的终点),而在yolo格式中,以相对坐标(x相对于w, y相对于h)描述标注框,具体格式为cx,cy,w,h(其中cx,cy为标注框的中心点)
2.2 全部代码
import json
import cv2
import numpy as np
import os
def json2yolo(path):
dic={'火':'0',"烟雾":'1'}#类别字典
data = json.load(open(path,encoding="utf-8"))#读取带有中文的文件
w=data["imageWidth"]#获取jaon文件里图片的宽高
h=data["imageHeight"]
all_line=''
for i in data["shapes"]:
#归一化坐标点。并得到cx,cy,w,h
[[x1,y1],[x2,y2]]=i['points']
x1,x2=x1/w,x2/w
y1,y2=y1/h,y2/h
cx=(x1+x2)/2
cy=(y1+y2)/2
wi=abs(x2-x1)
hi=abs(y2-y1)
#将数据组装成yolo格式
line="%s %.4f %.4f %.4f %.4f\n"%(dic[i['label']],cx,cy,wi,hi)#生成txt文件里每行的内容
all_line+=line
#print(all_line)
filename=path.replace('json','txt')#将path里的json替换成txt,生成txt里相对应的文件路径
fh=open(filename,'w',encoding='utf-8')
fh.write(all_line)
fh.close()
path="D:/yolo_seq/fire_smoke/data/data/"
path_list=os.listdir(path)
path_list2=[x for x in path_list if ".json" in x]#获取所有json文件的路径
for p in path_list2:
json2yolo(path+p)



