
【图解大数据技术】Flume、Kafka、Sqoop
【图解大数据技术】Flume、Kafka、Sqoop
- Flume
- Flume简介
- Flume的应用场景
- Kafka
- Kafka简介
- Kafka架构
- Flume与Kafka集成
- Sqoop
- Sqoop简介
- Sqoop原理
- sqoop搭配任务调度器实现定时数据同步
Flume
Flume简介
Flume是一个数据采集工具,多用于大数据技术架构下的日志采集。
Flume的特点是高可靠,高可用,分布式,海里数据采集传输。
Flume的基础架构如下:
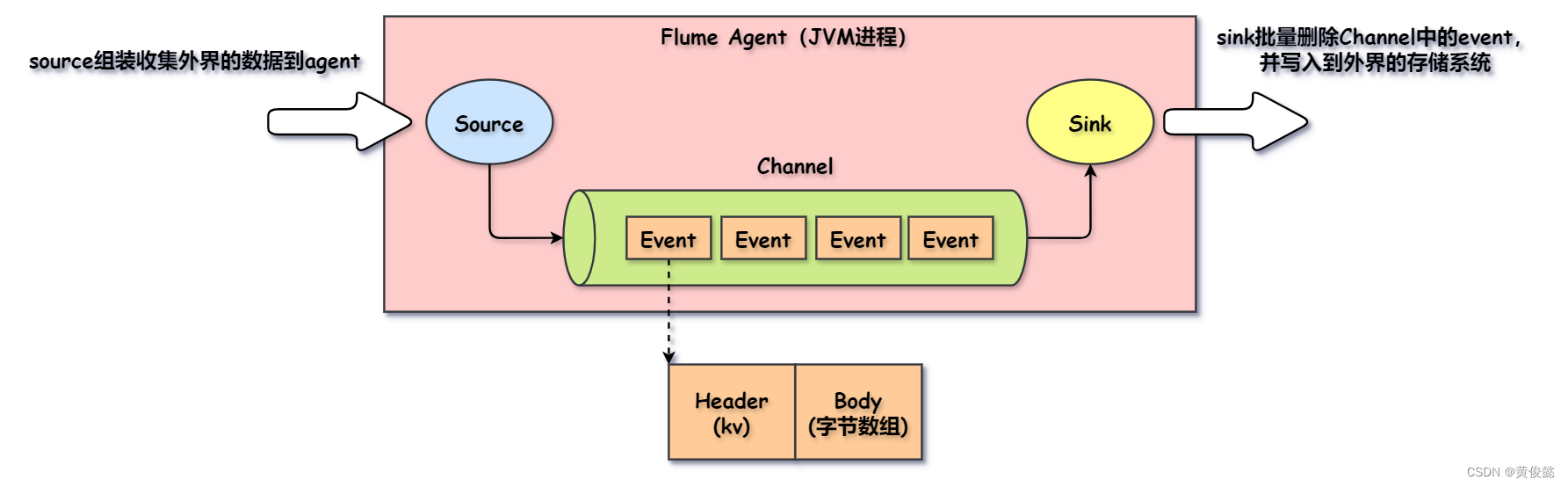
- Agent:一个Agent就是一个JVM进行,Agent中主要由Source、Channel、Sink三部分组成。
- Source:Source主要负责收集外部的数据到Agent中,以Event的形式存入Channel。
- Sink:Sink负责从Channel中批量删除Event并把它们写入指定的外部存储。
- Channel:Source与Sink之间的一个缓冲区,有MemoryChannel和FileChannel两种类型,分别存储数据在内存和文件中。Channel以Event的形式存储数据。
- Event:Flume以Event的形式将数据从源头传输到目的地。Event分Header和Body两部分,Header是KV格式,Body是字节数组。
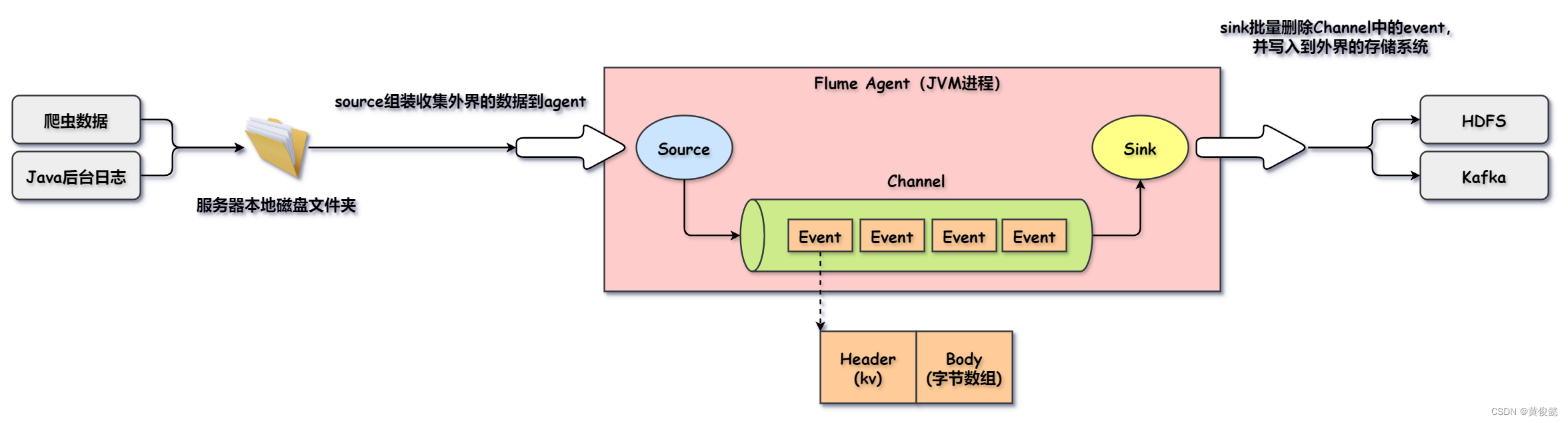
Flume的应用场景
我们使用Flume,一般是在大数据环境下做日志采集,或者收集爬虫数据,然后导入到HDFS或Kafka中。
Kafka
Kafka简介
Kafka是一个消息队列,一般应用在大数据环境下日志信息的传输。当然Kafka也可以应用在业务系统,但是业务系统一般用的RabbitMQ或RocketMQ较多。
Kafka架构
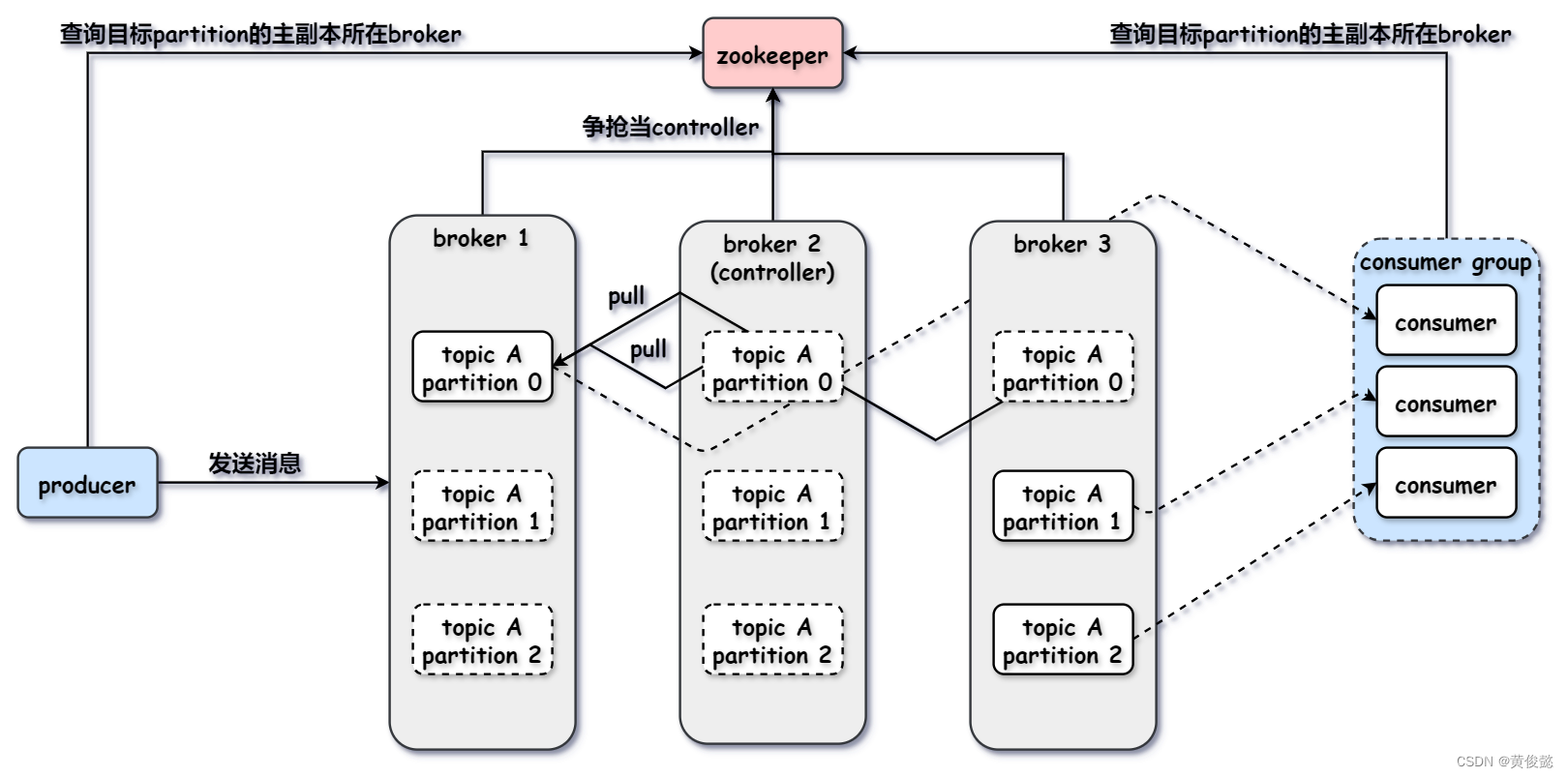
- Zookeeper:Kafka通过Zookeeper记录broker信息,某个topic的partition所在的broker等。
- Producer:消息生产者。
- Concumer Group:消费者组,每个消费者都从属于一个消费者组,同一组内的不同消费者消费同一个topic下的不同partition。
- Consumer:消息消费者。
- Topic:消息主题,每个主题都有多个消息分区(Partition),消息生产者发消息是发到某个Partition上,消费者也是消费某个Partition的消息。
- Partition:消息分区,真正存储消息,每个Partition对应broker上的一个目录,存储消息数据文件。
由于后续打算开一个消息中间件专题去详细解析Kafka,这里就不详细论述。
Flume与Kafka集成
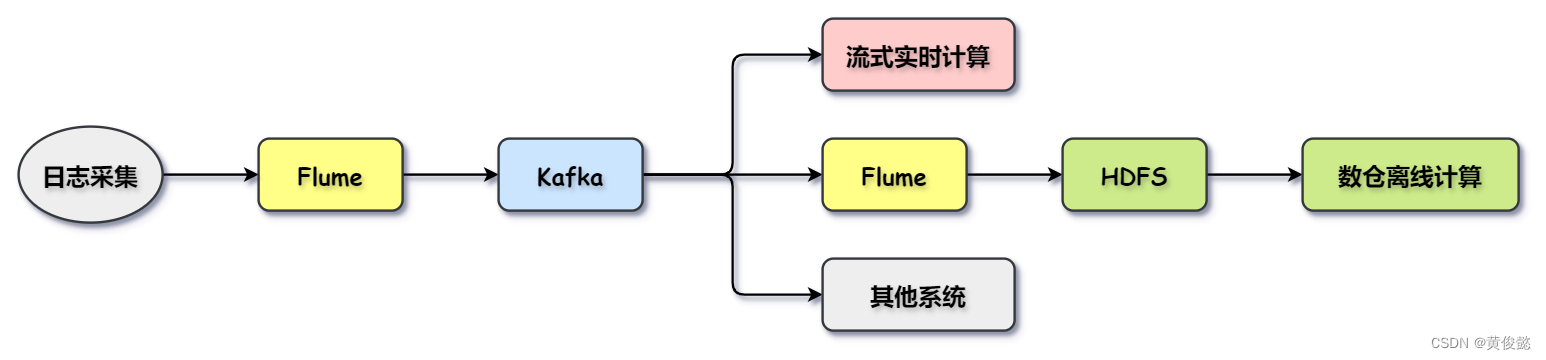
Kafka搭配Flume是一对很常见的组合。通过Flume进行日志收集,然后发送到Kafka,Kafka起到了日志数据缓冲的作用,其他系统如果有需要都可以通过Kafka监听日志信息。
比如我们可以使用Spark Streaming监听Kafka进行实时计算;也可以通过Flume接收Kafka上的日志数据,再导入到HDFS,给后续的数仓做离线计算;或者其他的一些需要监听日志消息的系统。
Sqoop
Sqoop简介
Sqoop是一款用于关系型数据库与Hadoop之间进行数据导入导出的工具。我们可以利用Sqoop将关系型数据库(如Mysql、Oracle、DB2)中的数据导入到Hadoop的HDFS、Hive、HBase中(最终都是落入HDFS);也可以从HDFS中导出数据到关系型数据库中。

Sqoop原理
Sqoop的原理很简单,就是把接收到的命令翻译成MapReduce程序来执行,在MapReduce程序中进行数据导入导出操作。

sqoop搭配任务调度器实现定时数据同步
sqoop可以搭配像oozie或者Azkaban等任务调度器实现定时的数据同步。

可以通过定时调度器定时执行一个shell脚本,shell脚本中是sqoop命令,这样就可以达到定时数据同步的作用。

免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们,邮箱:ciyunidc@ciyunshuju.com。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!



