
爬取CSDN博文到本地(包含图片,标签等信息)
文章目录
- csdnToMD
- 改进
- 将CSDN文章转化为Markdown文档
- 那有什么办法快速得到md文档?
- 例如:
- 获取单个文章markdown
- 获取所有的文章markdown
- 项目中待解决的问题
csdnToMD
项目原作者:https://gitee.com/liushili888/csdn-is—mark-down
改进后仓库地址:https://github.com/Xiamu-ssr/csdnToMD
改进
这里进行一定的改进,可以更准确获取时间,也可以选择图片的存放方式是否集中或分离到每篇文章的同名文件夹,以适应部分md扩展语法,比如{% asset_img 1.png %}
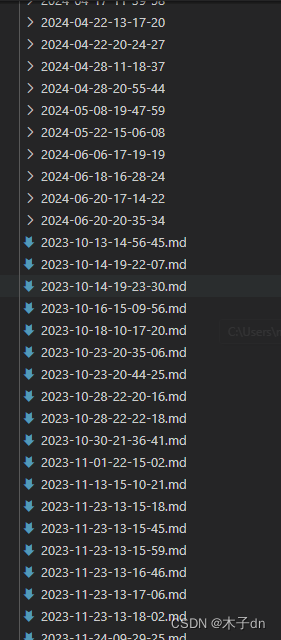
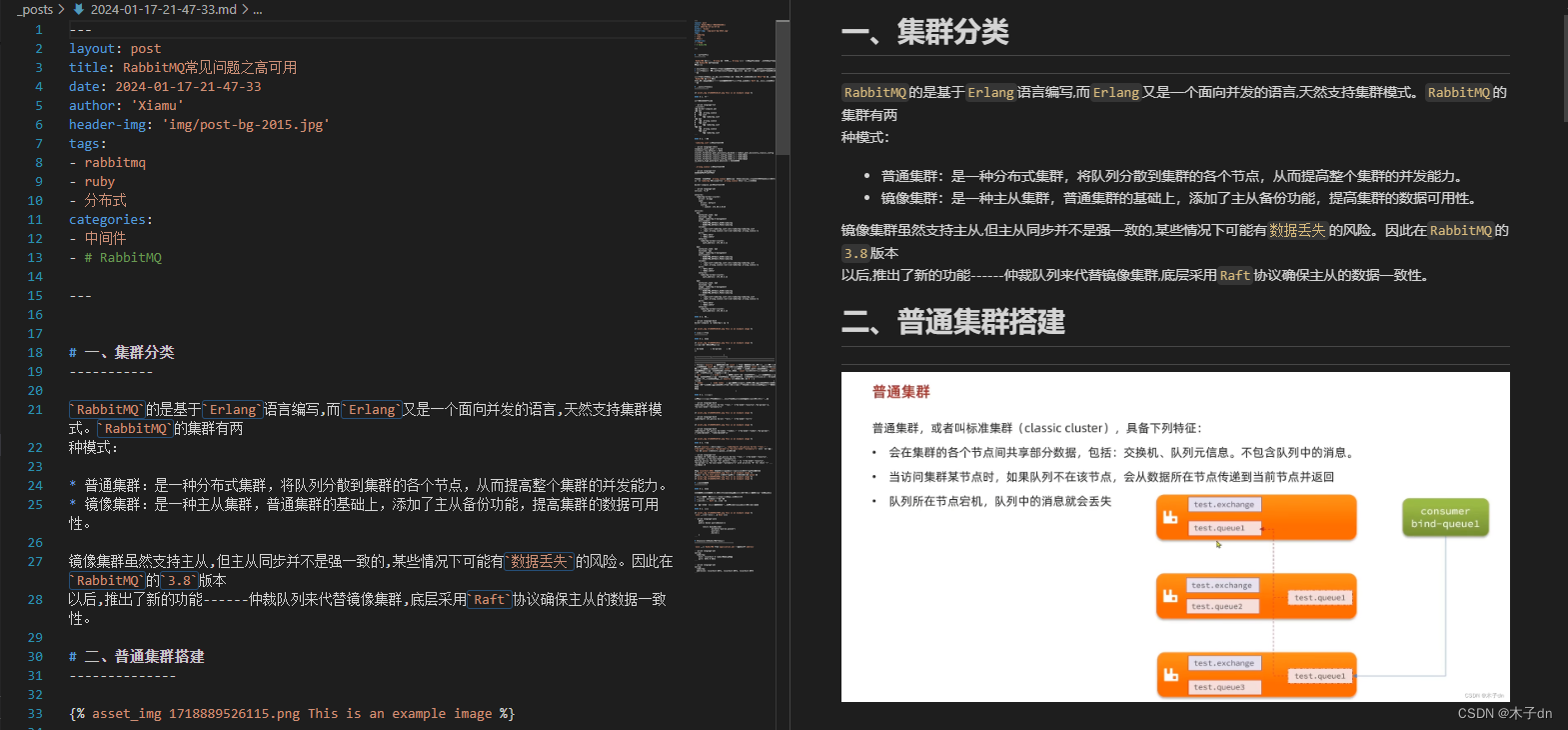
爬取结果截图
将CSDN文章转化为Markdown文档
很多情况下,我们需要将CSDN中的文章转化为markdown文档,直接复制全文是不可以的,CSDN不支持。
那有什么办法快速得到md文档?
原理:
- 由于CSDN不是获取数据不是前后端分离的,所以无法根据接口获取文章的所有数据,它的数据是和页面元素组合在一起的,需要根据页面中的元素标签转化为markdown中的元素标签。
- 使用jsoup解析csdn文档
- 利用jericho-html、flexmark-all、jsoup、selenium等工具将html文档转化为markdown文档
使用:
- 去https://googlechromelabs.github.io/chrome-for-testing/下载chromedriver,解压后修改DynamicScraperTime函数的驱动地址。如果不下载驱动也可以,把String time = DynamicScraperTime(startUrl);的获取换成下一行被注释的就行,但是因为页面动态加载的原因,会无法获取准确的时间。
- 然后直接将CSDN文章的url放入crawler类即可
例如:
获取单个文章markdown
public class Main { private static final String CSDN_URL = "https://blog.csdn.net/m0_51390969/"; public static void main(String[] args) { AbstractCrawler crawler = new CsdnCrawler(); crawler.crawlOne("https://blog.csdn.net/m0_51390969", "131172667"); } }获取所有的文章markdown
public class Main { private static final String CSDN_URL = "https://blog.csdn.net/m0_51390969/"; public static void main(String[] args) { AbstractCrawler crawler = new CsdnCrawler(); crawler.crawl(CSDN_URL); } }项目中待解决的问题
TODO ‘> ’标签中包含代码块,需要处理
TODO 代码中格式待处理
TODO 增加GUI页面
TODO 公式、表格标签的处理
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们,邮箱:ciyunidc@ciyunshuju.com。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!



