
Python 网络爬虫的常用库汇总(建议收藏)
Python 在编写网络爬虫常常用到的一些库。
Python爬虫网络库主要包括:urllib、requests、lxml、fake-useragent、bs4(BeautifulSoup)、grab、pycurl、urllib3、httplib2、RoboBrowser 、MechanicalSoup、mechanize、socket、Unirest for Python、hyper、PySocks、treq、aiohttp等。
请求库:实现 HTTP 请求操作
- urllib:一系列用于操作URL的功能。
- requests:基于 urllib 编写的,阻塞式 HTTP 请求库,发出一个请求,一直等待服务器响应后,程序才能进行下一步处理。
- selenium:自动化测试工具。一个调用浏览器的 driver,通过这个库你可以直接调用浏览器完成某些操作,比如输入验证码。
- aiohttp:基于 asyncio 实现的 HTTP 框架。异步操作借助于 async/await 关键字,使用异步库进行数据抓取,可以大大提高效率。
解析库:从网页中提取信息
- beautifulsoup:html 和 XML 的解析,从网页中提取信息,同时拥有强大的API和多样解析方式。
- pyquery:jQuery 的 Python 实现,能够以 jQuery 的语法来操作解析 HTML 文档,易用性和解析速度都很好。
- lxml:支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高。
- tesserocr:一个 OCR 库,在遇到验证码(图形验证码为主)的时候,可直接用 OCR 进行识别。
存储库:Python 与数据库交互
爬虫框架
- Scrapy:很强大的爬虫框架,可以满足简单的页面爬取(比如可以明确获知url pattern的情况)。用这个框架可以轻松爬下来如亚马逊商品信息之类的数据。但是对于稍微复杂一点的页面,如 weibo 的页面信息,这个框架就满足不了需求了。
- Crawley:高速爬取对应网站的内容,支持关系和非关系数据库,数据可以导出为 JSON、XML 等。
- Portia:可视化爬取网页内容。
- newspaper:提取新闻、文章以及内容分析。
- python-goose:java 写的文章提取工具。
- cola:一个分布式爬虫框架。项目整体设计有点糟,模块间耦合度较高。
Web 框架库
- flask:轻量级的 web 服务程序,简单,易用,灵活,主要来做一些 API 服务。做代理时可能会用到。
- django:一个 web 服务器框架,提供了一个完整的后台管理,引擎、接口等,使用它可做一个完整网站。
Re库的基本使用
Re库介绍:
- Re库是Python的标准库,主要用于字符串匹配。
- 调用方式:import re
正则表达式的表示类型:
raw string类型(原生字符串类型):
- re库采用raw string类型表示正则表达式,表示为:r’text’
- 例如:r’[1-9]\d{5}’
- raw string是指不包含转义符的字符串
- string类型,更繁琐。
- 例如:‘[1-9]\d{5}’;‘\d{3}-\d{8}|\d{4}-\d{7}’
当正则表达式包含转义符时,建议使用raw string类型来表示正则表达式。
Re库主要功能函数:
函数
- 说明 re.search()
- 在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象 re.match()
- 从一个字符串的开始位置起匹配正则表达式,返回match对象 re.findall()
- 搜索字符串,以列表类型返回全部能匹配的字符串 re.split()
- 将一个字符串按照正则表达式匹配结果进行分割,返回列表类型 re.finditer()
- 搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是match对象 re.sub()
- 在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串
re.compile() 返回的是一个匹配对象,它单独使用就没有任何意义,需要和findall(), search(), match()搭配使用。
re.search(pattern,string,flags=0) 在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象。 pattern:正则表达式的字符串或原生字符串表示 string:待匹配字符串 flags:正则表达式使用时的控制标记 re.I(re.IGNORECASE):忽略正则表达式的大小写,[A-Z]能够匹配小写字符 re.M(re.MULTILINE):正则表达式中的^操作符能够将给定字符串的每行当作匹配开始 re.S(re.DOTALL):正则表达式中的.操作符能够匹配所有字符,默认匹配除换行外的所有字符****!!!!**** re.match(pattern, string, flags = 0) 从一个字符串的开始位置起匹配正则表达式,返回match对象。 pattern:正则表达式的字符串或原生字符串表示 string:待匹配字符串 flags:正则表达式使用时的控制标记 re.findall(pattern, string, flags = 0) 搜索字符串,以列表类型返回全部能匹配的子串。 pattern:正则表达式的字符串或原生字符串表示 string:待匹配字符串 flags:正则表达式使用时的控制标记 re.split(pattern, string, maxsplit = 0, flags = 0) 搜索字符串,以列表类型返回全部能匹配的子串。 pattern:正则表达式的字符串或原生字符串表示 string:待匹配字符串 maxsplit:最大分割数,剩余部分作为最后一个元素输出 flags:正则表达式使用时的控制标记 re.finditer(pattern, string, flags = 0) 搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是match对象。 pattern:正则表达式的字符串或原生字符串表示 string:待匹配字符串 flags:正则表达式使用时的控制标记 re.compile() compile()的定义: compile(pattern, flags=0) Compile a regular expression pattern, returning a pattern object. 从compile()函数的定义中,可以看出返回的是一个匹配对象,它单独使用就没有任何意义,需要和findall(), search(), match()搭配使用。 compile()与findall()一起使用,返回一个列表。 import re def main(): content = 'Hello, I am Jerry, from Chongqing, a montain city, nice to meet you……' regex = re.compile('\w*o\w*') x = regex.findall(content) print(x) if __name__ == '__main__': main() # ['Hello', 'from', 'Chongqing', 'montain', 'to', 'you'] compile()与match()一起使用,可返回一个class、str、tuple。但是一定需要注意match(),从位置0开始匹配,匹配不到会返回None,返回None的时候就没有span/group属性了,并且与group使用,返回一个单词‘Hello’后匹配就会结束。 import re def main(): content = 'Hello, I am Jerry, from Chongqing, a montain city, nice to meet you……' regex = re.compile('\w*o\w*') y = regex.match(content) print(y) print(type(y)) print(y.group()) print(y.span()) if __name__ == '__main__': main() # # # Hello # (0, 5) compile()与search()搭配使用, 返回的类型与match()差不多, 但是不同的是search(), 可以不从位置0开始匹配。但是匹配一个单词之后,匹配和match()一样,匹配就会结束。 re.sub(pattern, repl, string, count = 0, flags = 0) 在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串。 pattern:正则表达式的字符串或原生字符串表示 repl:替换匹配字符串的字符串 string:待匹配字符串 count:匹配的最大替换次数 flags:正则表达式使用时的控制标记此外我这里准备了详细的Python资料,除了为你提供一条清晰的学习路径,我甄选了最实用的学习资源以及庞大的实例库。短时间的学习,你就能够很好地掌握爬虫这个技能,获取你想得到的数据。
01 专为0基础设置,小白也能轻松学会
我们把Python的所有知识点,都穿插在了漫画里面。
在Python小课中,你可以通过漫画的方式学到知识点,难懂的专业知识瞬间变得有趣易懂。


你就像漫画的主人公一样,穿越在剧情中,通关过坎,不知不觉完成知识的学习。
02 无需自己下载安装包,提供详细安装教程
03 规划详细学习路线,提供学习视频
04 提供实战资料,更好巩固知识
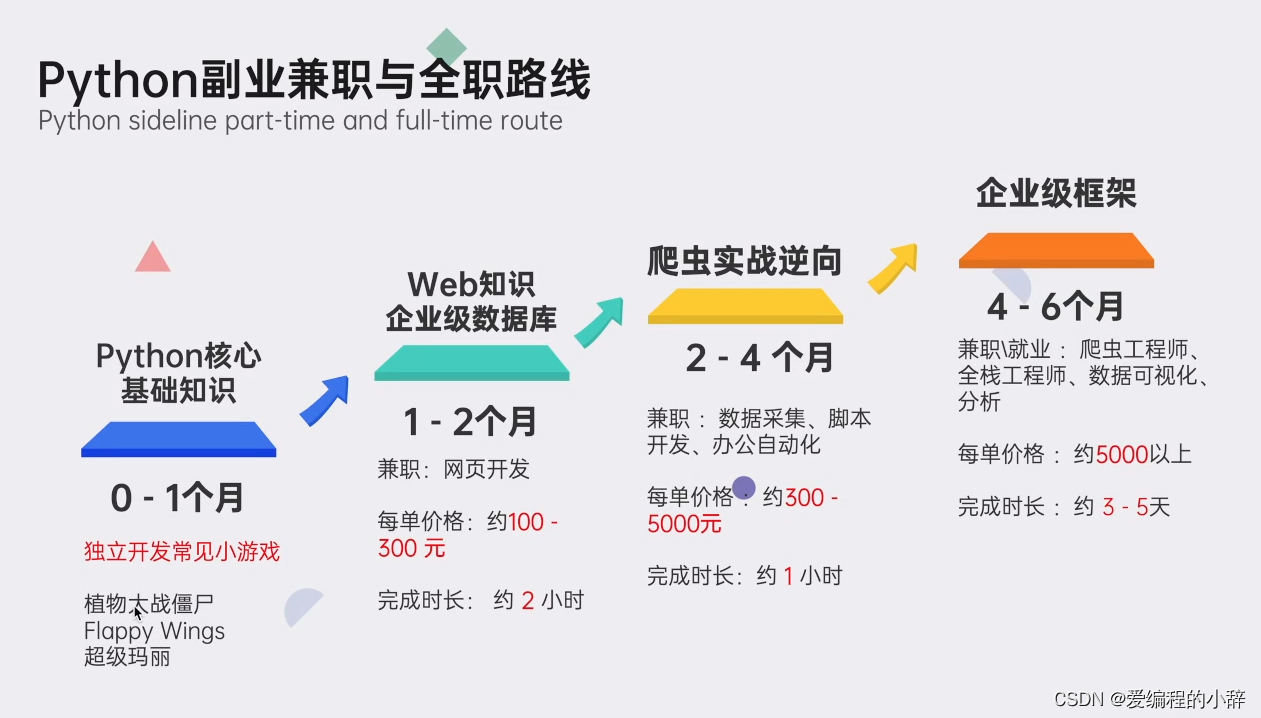
05 提供面试资料以及副业资料,便于更好就业
这份完整版的Python全套学习资料已经上传CSDN,朋友们如果需要也可以扫描下方csdn官方二维码或者点击主页和文章下方的微信卡片获取领取方式,【保证100%免费】

免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们,邮箱:ciyunidc@ciyunshuju.com。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!



