
Hadoop分布式计算框架(MapReduce)——案例实践:气象大数据离线分析
目录
(1)项目需求
(2)数据格式
(3)实现思路
(4)项目开发
(1)项目需求
现在有一份来自美国国家海洋和大气管理局的数据集,里面包含近30年每个气象站、每小时的天气预报数据,每个报告的文件大小大约15M。一共有263个气象站,每个报告文件的名字包含气象站ID,每条记录包含气温、风向、天气状况等多个字段信息。现在要求统计美国各气象站30年平均气温。
(2)数据格式
天气预报每行数据的每个字段都是定长的,完整数据格式如下。

数据格式由Year(年)、Month(月)、Day(日)、Hour(时)、Temperature(气温)、Dew(湿度)、Pressure(气压)、Wind dir.(风向)、Wind speed(风速)、Sky Cond.(天气状况)、Rain 1h(每小时降雨量)、Rain 6h(每6小时降雨量)组成。
(3)实现思路
我们的目标是统计近30年每个气象站的平均气温,由此可以设计一个MapReduce如下所示:
Map = {key = weather station id, value = temperature}
Reduce = {key = weather station id, value = mean(temperature)}
首先调用mapper的map()函数提取气象站id作为key,提取气温值作为value,然后调用reducer的reduce()函数对相同气象站的所有气温求平均值。
(4)项目开发
打开IDEA的bigdata项目,开发MapReduce分布式应用程序,统计美国各气象站近30年的平均气温。
(1)引入Hadoop依赖
由于开发MapReduce程序需要依赖Hadoop客户端,所以需要在项目的pom.xml文件中引入Hadoop的相关依赖,添加如下内容:
org.apache.hadoop> /home/hadoop/shell/logs/weather.log 2>&1
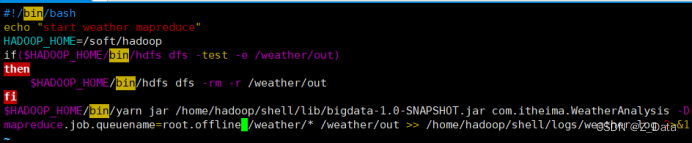
⑥为weatherMR.sh 脚本添加可执行权限:
chmod u+x weatherMR.sh

⑦提交MapReduce作业
到该脚本目录下,执行weatherMR.sh脚本提交MapReduce作业
./weatherMR.sh

⑧查看运行结果
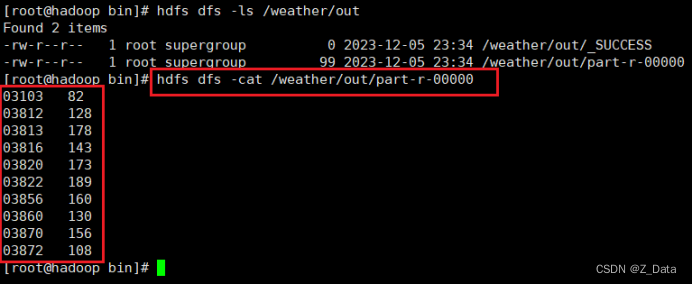
使用HDFS命令查看美国各气象站近30年的平均气温:
hdfs dfs -cat /weather/out/part-r-00000
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们,邮箱:ciyunidc@ciyunshuju.com。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!



