
kafka集成flink api编写教程
1.引入依赖(pox.xml)
org.apache.flink
flink-java
1.13.6
org.apache.flink
flink-streaming-java_2.12
1.13.6
org.apache.flink
flink-clients_2.12
1.13.6
org.apache.flink
flink-connector-kafka_2.12
1.13.6
2.创建日志配置文件
把$FLINK_HOME/conf/log4j.properties 内容复制粘贴过来
# This affects logging for both user code and Flink
rootLogger.level = INFO
rootLogger.appenderRef.file.ref = MainAppender
# Uncomment this if you want to _only_ change Flink's logging
#logger.flink.name = org.apache.flink
#logger.flink.level = INFO
# The following lines keep the log level of common libraries/connectors on
# log level INFO. The root logger does not override this. You have to manually
# change the log levels here.
logger.akka.name = akka
logger.akka.level = INFO
logger.kafka.name= org.apache.kafka
logger.kafka.level = INFO
logger.hadoop.name = org.apache.hadoop
logger.hadoop.level = INFO
logger.zookeeper.name = org.apache.zookeeper
logger.zookeeper.level = INFO
logger.shaded_zookeeper.name = org.apache.flink.shaded.zookeeper3
logger.shaded_zookeeper.level = INFO
# Log all infos in the given file
appender.main.name = MainAppender
appender.main.type = RollingFile
appender.main.append = true
appender.main.fileName = ${sys:log.file}
appender.main.filePattern = ${sys:log.file}.%i
appender.main.layout.type = PatternLayout
appender.main.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
appender.main.policies.type = Policies
appender.main.policies.size.type = SizeBasedTriggeringPolicy
appender.main.policies.size.size = 100MB
appender.main.policies.startup.type = OnStartupTriggeringPolicy
appender.main.strategy.type = DefaultRolloverStrategy
appender.main.strategy.max = ${env:MAX_LOG_FILE_NUMBER:-10}
# Suppress the irrelevant (wrong) warnings from the Netty channel handler
logger.netty.name = org.apache.flink.shaded.akka.org.jboss.netty.channel.DefaultChannelPipeline
logger.netty.level = OFF
3.flink生产者api
package com.ljr.flink;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import java.util.ArrayList;
import java.util.Properties;
public class MyFlinkKafkaProducer {
//输入main tab 键 即创建入main 方法
public static void main(String[] args) throws Exception {
//1.获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置的槽数与分区相等
env.setParallelism(3);
//2.准备数据源
ArrayList wordlist = new ArrayList();
wordlist.add("zhangsan");
wordlist.add("lisi");
DataStreamSource stream = env.fromCollection(wordlist);
//创建kafka生产者
Properties pros = new Properties();
pros.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"node1:9092,node2:9092");
FlinkKafkaProducer kafkaProducer = new FlinkKafkaProducer("customers", new SimpleStringSchema(), pros);
//3.添加数据源
stream.addSink(kafkaProducer);
//4.执行代码
env.execute();
}
}
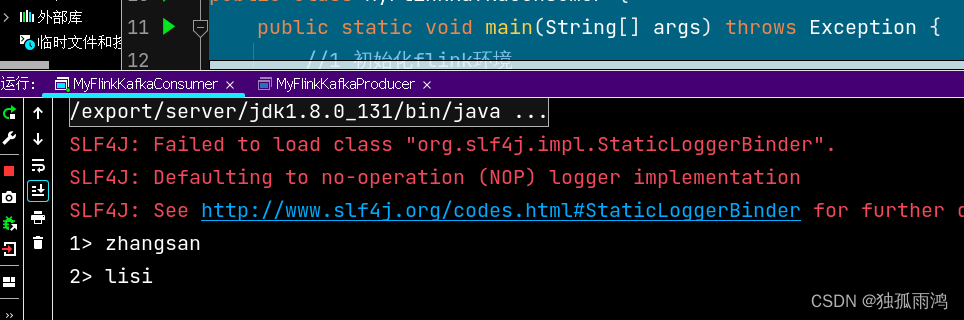
运行;kafka消费者消费结果

4.flink消费者api
package com.ljr.flink;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import java.util.Properties;
public class MyFlinkKafkaConsumer {
public static void main(String[] args) throws Exception {
//1 初始化flink环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(3);
//2 创建消费者
Properties pros = new Properties();
pros.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"node1:9092,node2:9092");
//pros.put(ConsumerConfig.GROUP_ID_CONFIG,"hh")
FlinkKafkaConsumer flinkKafkaConsumer = new FlinkKafkaConsumer("customers", new SimpleStringSchema(), pros);
//3 关联消费者和flink流
env.addSource(flinkKafkaConsumer).print();
//4 执行
env.execute();
}
}
运行,用3中的生产者生产数据,消费结果
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们,邮箱:ciyunidc@ciyunshuju.com。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!



