
亮数据代理IP助力高效数据采集
文章目录
- 📑前言
- 一、爬虫数据采集痛点
- 二、代理IP解决爬虫痛点
- 2.1 为什么可以
- 2.2 本篇采用的代理IP
- 四、零代码获取数据
- 4.1 前置背景
- 4.2 亮数据浏览器自动抓取数据
- 4.3 使用步骤:
- 五、数据集
- 5.1 免费样本
- 5.2 定制数据集
- 🌤️个人小结
📑前言
在进行爬虫数据采集时,开发者往往会遇到各种挑战和痛点。这些包括但不限于:爬虫代码的维护困难、数据量庞大、爬虫难度大以及频率限制等问题。爬虫代码需要不断更新和调整以应对网站结构和内容的变化,而处理大量数据也需要耗费大量时间和资源。同时,许多网站设置了各种防爬机制,增加了爬虫的复杂性,导致访问频率受限,甚至可能导致IP被封禁。
在这种情况下,代理IP技术可以成为解决这些问题的有效手段。通过代理IP,使用代理服务器来访问目标网站,可以隐藏真实IP地址,绕过频率限制和IP封禁,从而更高效地进行数据采集。代理IP的使用不仅可以实现匿名保护,保护用户隐私和安全,还能分散访问压力,提高爬取效率和稳定性。因此,代理IP对于解决爬虫数据采集过程中的各种问题具有重要意义。

一、爬虫数据采集痛点
在进行爬虫数据采集时,开发者通常会遇到一些常见的挑战和痛点,包括但不限于以下几方面:
- 爬虫代码维护难:网站的结构和内容可能经常变化,导致先前编写的爬虫代码无法正常工作,需要不断更新和调整代码。
- 数据量大:有些网站的数据量非常庞大,采集这些数据需要花费大量时间和资源。同时,如何高效存储和处理这些大量数据也是一个重要问题。
- 爬虫难度大:许多网站会设置各种防爬机制,如验证码、User-Agent检测、IP检测等,这些机制增加了爬虫的难度和复杂性。
- 频率限制:目标网站通常会对访问频率进行限制,过于频繁的访问可能会导致IP被封禁,从而无法高效采集公开数据。
二、代理IP解决爬虫痛点
2.1 为什么可以
使用代理IP就是通过一个中间服务器来访问网站,隐藏你的真实IP地址,这样可以解决爬虫时可能遇到的问题,比如频率限制或IP封禁。
好处包括:
- 匿名保护:可以隐藏真实IP,保护隐私安全。
- 安全采集数据:分散访问压力,提高效率和稳定性。
- 分散压力:使用多个代理IP模拟多用户访问,避免被封禁。
- 多地区收集数据:方便进行数据分析和对比。
但是也需要注意:
- IP安全性需保证。
- 可能增加请求延迟和复杂性,需要合理配置。
- 必须遵守法律法规和网站规定,不得进行非法活动。
2.2 本篇采用的代理IP
本篇采用亮数据代理IP进行展示,选择的原因很简单:它的服务优势包括IP种类丰富、全球覆盖、以及超级代理服务器加速网络。动态住宅、静态住宅、机房和移动代理IP都有各自优点,可以根据需求选择合适的代理类型。
四、零代码获取数据
4.1 前置背景
在如今的数据驱动时代,获取竞争对手的网站数据对商业决策至关重要,
如果一家新兴的电商公司,计划进入二手电子产品市场。那么为了制定竞争策略,就就需要从一些垂直网站获取数据分析,比如获取Ebay上某些热门二手电子产品的销售数据。这些数据包括产品名称、价格、卖家评级、销售数量等。
通过分析这些数据,我们可以:
- 了解市场趋势,判断哪些产品最受欢迎。
- 分析价格区间,制定有竞争力的定价策略。
- 评估卖家信誉,学习优秀卖家的运营策略。
4.2 亮数据浏览器自动抓取数据
亮数据浏览器是一款强大的自动化爬虫工具,可以帮助不会写代码的用户轻松采集数据。
本次呢我的目的是想要获取:Ebay的数据,这个网站就是淘宝初期参照的目标。
因此这次抓取到的数据内容是较为重要的:拿到这些数据可以进行:市场研究、客户洞察、竞争情报…
4.3 使用步骤:
- 点击免费试用:
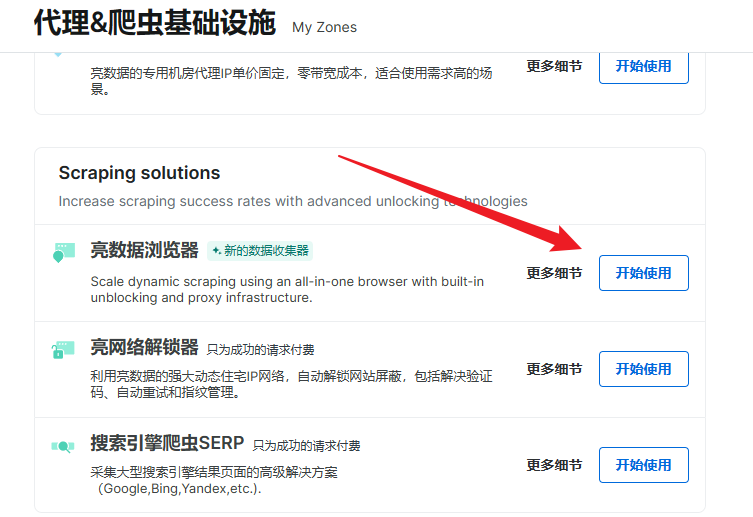
- 点击开始使用:
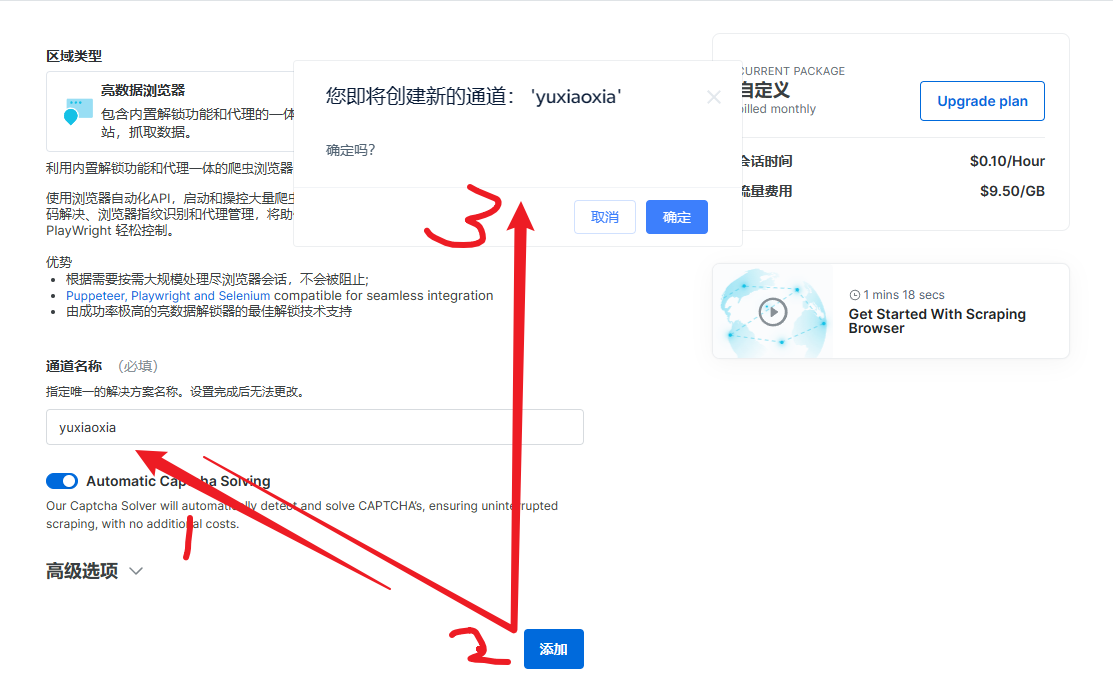
- 自定义通道:
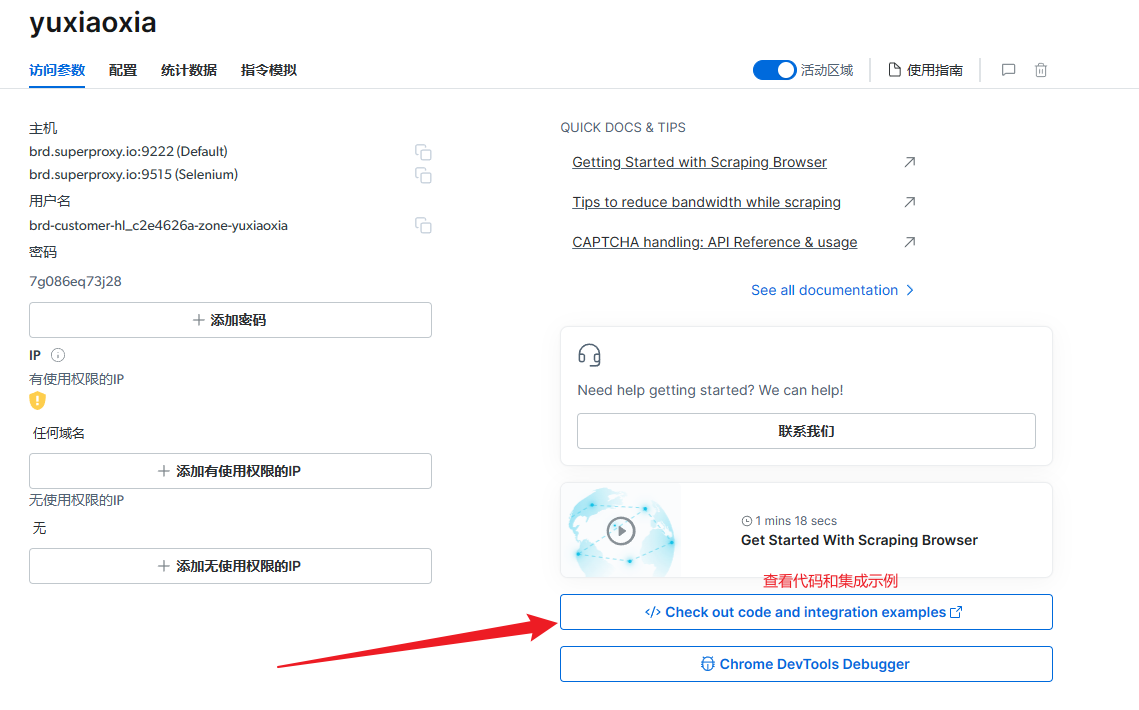
- 点击查看代码集成示例:
- 输入目标网站和选择国家:
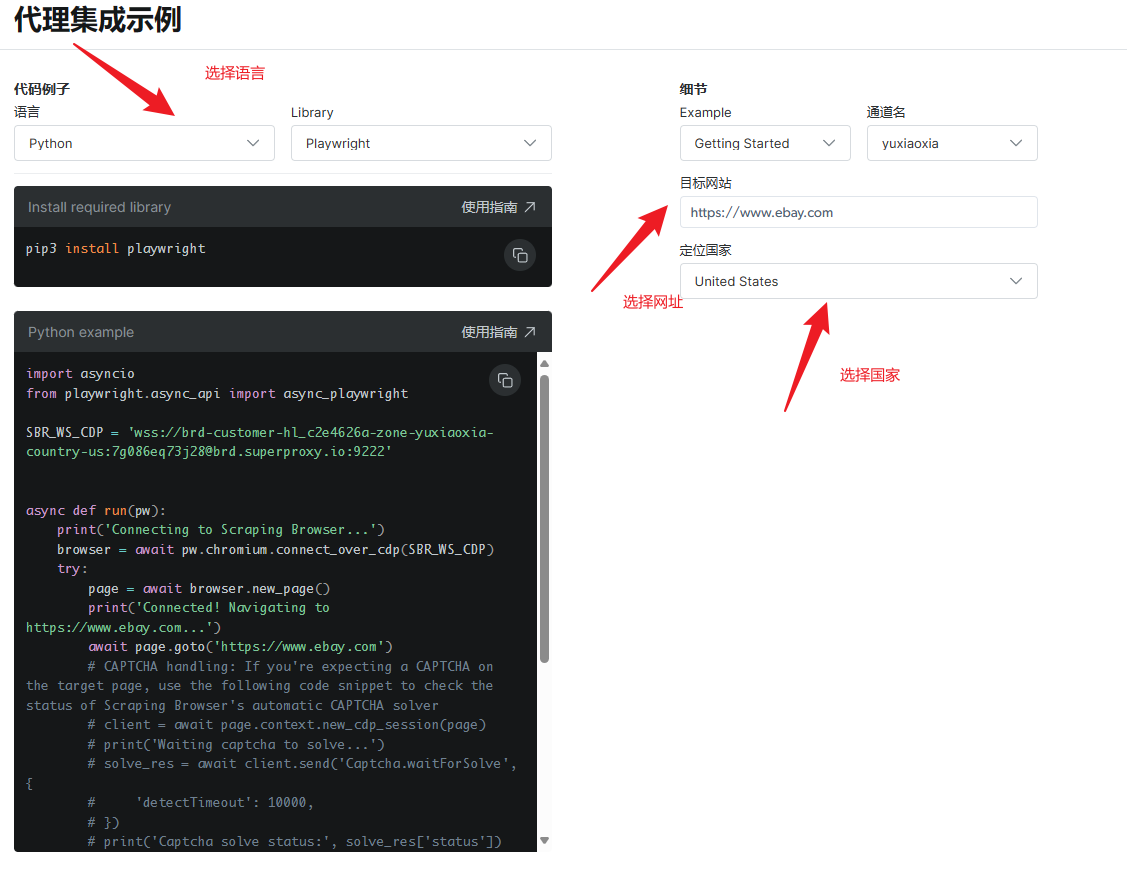
这里输入你想要采集数据的网址,本次我是想要采集Ebay的数据,因此填写的是它们的网址,自行按需填写就好。
- 安装亮数据的第三方Python模块:
pip3 install playwright
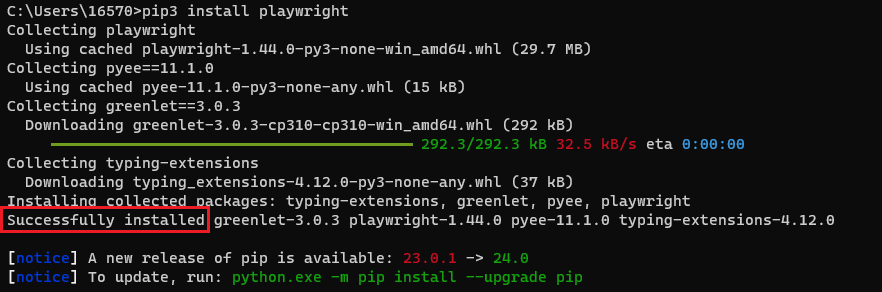
看到:successfully installed就是成功了,图片中的报红是显示有新的版本,我们的当前版本是:23.0.1忽略即可。
- 复制案例代码到Python编辑器中运行:
import asyncio from playwright.async_api import async_playwright SBR_WS_CDP = 'wss://brd-customer-hl_c2e4626a-zone-yuxiaoxia-country-us:7g086eq73j28@brd.superproxy.io:9222' async def run(pw): print('Connecting to Scraping Browser...') browser = await pw.chromium.connect_over_cdp(SBR_WS_CDP) try: page = await browser.new_page() print('Connected! Navigating to https://example.com...') await page.goto('https://example.com') # CAPTCHA handling: If you're expecting a CAPTCHA on the target page, use the following code snippet to check the status of Scraping Browser's automatic CAPTCHA solver # client = await page.context.new_cdp_session(page) # print('Waiting captcha to solve...') # solve_res = await client.send('Captcha.waitForSolve', { # 'detectTimeout': 10000, # }) # print('Captcha solve status:', solve_res['status']) print('Navigated! Scraping page content...') html = await page.content() print(html) finally: await browser.close() async def main(): async with async_playwright() as playwright: await run(playwright) if __name__ == '__main__': asyncio.run(main())
- 拿到指定数据
Product: Apple iPhone 11, Price: $500, Rating: 4.5 Product: Samsung Galaxy S10, Price: $400, Rating: 4.7 Product: Sony WH-1000XM4, Price: $250, Rating: 4.8 ......
这些数据可以帮助我们:
- 市场分析:通过分析不同产品的价格和销量,判断市场需求和趋势。
- 定价策略:了解市场上同类产品的定价,制定有竞争力的价格策略。
- 卖家研究:通过分析高评分卖家的产品和服务,学习其运营策略,提升自己的业务水平。
- 问题集
- CAPTCHA:某些网站为了防止爬虫,会使用CAPTCHA进行验证。
- 解决方案:使用Scraping Browser的自动CAPTCHA解决功能,可以在代码中加入以下片段进行处理:
client = await page.context.new_cdp_session(page) print('Waiting captcha to solve...') solve_res = await client.send('Captcha.waitForSolve', {'detectTimeout': 10000}) print('Captcha solve status:', solve_res['status'])- IP封禁:频繁访问同一网站可能导致IP被封禁。
- 解决方案:使用代理服务,亮数据提供的代理服务,通过更换IP避免被封禁。
- 页面动态加载:某些数据在页面加载完成后通过JavaScript动态加载。
- 解决方案:使用Playwright的等待功能,确保页面完全加载后再进行数据提取。
await page.wait_for_selector('.s-item')五、数据集
5.1 免费样本

进入亮数据官网后–>数据集–>获取免费样本–>填写信息–>等待样本推送
5.2 定制数据集
亮数据可以根据您的需求提供多种数据格式,包括CSV、JSON、XML等等,并将数据按照您指定的方式直接交付到您需要的平台上,比如数据库、云存储、API等。我们也可以根据您的要求定期更新数据集,并将所有增量更新数据按时交付给您,确保您的数据始终保持最新和完整。我们的目标是通过定制化的数据服务,帮助您最大化数据的可用性和质量,以满足您的具体业务需求。
🌤️个人小结
在爬虫数据采集过程中,开发者常常面临着诸如代码维护难、数据量大、爬虫难度高以及频率限制等挑战。然而,使用高质量的代理IP服务如亮数据的多种类型代理IP,能有效解决这些问题。亮数据提供的代理IP种类丰富、全球覆盖,并具有高匿性、稳定性和高效性的特点,能在匿名保护、分散访问压力、提高爬取效率和稳定性方面表现优异。
同时,亮数据提供的强大自动化爬虫工具和定制化数据服务,帮助用户轻松实现数据采集和分析,应对各种防爬机制和频率限制问题。总的来说,亮数据代理IP及相关服务是解决爬虫数据采集难题的理想选择。通过亮数据网站了解更多信息,体验其优质服务,助力数据采集和分析工作更顺利高效。
- 解决方案:使用Playwright的等待功能,确保页面完全加载后再进行数据提取。
- IP封禁:频繁访问同一网站可能导致IP被封禁。
- 解决方案:使用Scraping Browser的自动CAPTCHA解决功能,可以在代码中加入以下片段进行处理:



