
【基于 PyTorch 的 Python 深度学习】9 目标检测与语义分割(2)
前言
文章性质:学习笔记 📖
学习资料:吴茂贵《 Python 深度学习基于 PyTorch ( 第 2 版 ) 》【ISBN】978-7-111-71880-2
主要内容:根据学习资料撰写的学习笔记,该篇主要介绍了优化候选框的几种方法。
一、优化候选框的几种方法
在进行目标检测时,往往会产生很多候选框,其中大部分是我们需要的,也有部分是我们不需要的。
因此 有效过滤 这些不必要的框就非常重要。这节我们介绍几种常用的优化候选框的算法。
1、交并比
使用 选择性搜索(SS)或 区域候选网络(RPN)等方法,最后每类选出的候选框会比较多,在这些候选框中如何选出质量较好?
可使用 交并比 这个度量值进行过滤。交并比(Intersection Over Union, IOU)用于计算候选框和目标实际标注边界框的重合度。
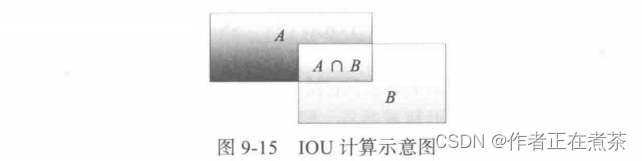
假设我们要计算两个矩形框 A 和 B 的 IOU ,即它们的交集与并集之比,如图 9-15 所示。且 A 、B 的重合度 IOU 的计算公式:
2、非极大值抑制
通过 选择性搜索(SS)或 区域候选网络(RPN)等方法生成的大量的候选框中有很多指向同一目标,故存在大量冗余的候选框。
如何减少这些冗余框?可使用 非极大值抑制(Non-Maximum Suppression, NMS)算法。
非极大值抑制算法的思想:搜索局部极大值,抑制非极大值元素。
如图 9-16 所示,要定位一辆车,SS 或 RPN 会对每个目标生成一堆矩形框,而 NMS 会过滤掉多余的矩形框,找到最佳的矩形框。

非极大值抑制的基本思路分析如下:先假设有 6 个候选框,每个候选框选定的目标属于汽车的概率如图 9-17 所示。

将这些候选框选定的目标按其属于车辆的概率从小到大排列,标记为 A 、B 、C 、D 、E 、F 。
(1)从概率最大的矩形框(即面积最大的框)F 开始,分别判断 A ~ E 与 F 的重叠度是否大于某个设定的阈值。
(2)假设 B 、D 与 F 的重叠度超过阈值,就将 B 、D 丢弃,并标记 F 是我们保留下来的第一个矩形框。
(3)从剩余的 A 、C 、E 中,选择概率最大的 E ,然后判断 A 、C 与 E 的重叠度是否大于某个设定的阈值。
(4)假设 A 、C 与 E 的重叠度超过阈值,就将 A 、C 丢弃,并标记 E 是我们保留下来的第二个矩形框。
(5)重复这个过程,直到找到所有被保留下来的矩形框。
【说明】因为超过阈值,说明两个矩形框有很大部分是重叠的,那么保留面积大的矩形框即可,那些小面积的矩形框是多余的。
3、边框回归
通过 选择性搜索(SS)或 区域候选网络(RPN)等方法生成的大量候选框,虽然有一部分可以通过 非极大值抑制(NMS)等方法过滤一些多余框,但仍然会存在很多质量不高的框图,如图 9-18 所示。

如图 9-18 所示,其中内部框的质量不高,定位不准,IOU<0.5 ,说明它没有正确检测出飞机,需要通过 边框回归 进行修改。
除此之外,训练时,我们也需要通过 边框回归 使预测框不断迭代,不断向真实框(又称目标框)靠近。
(1)边框回归的主要原理
如图 9-19 所示,最下面的框 A 代表生成的候选框,最上面的框 G 代表目标框。
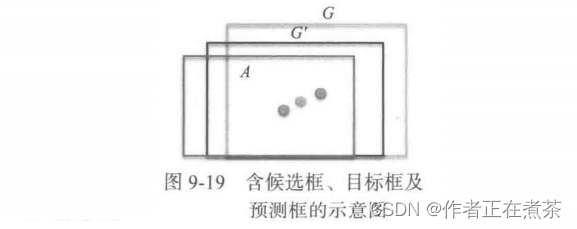
接下来我们需要基于 A 和 G 找到一种映射关系,得到一个预测框 G' ,并通过迭代使 G' 不断接近目标框 G 。
这个过程用数学符号可表示为如下形式:
锚框 A 的四维坐标为 ,其中 4 个值分别表示锚框 A 的中心坐标及宽和高。
锚框 G 的四维坐标为 ,其中 4 个值分别表示锚框 G 的中心坐标及宽和高。
基于 A 和 G ,找到一个对应关系 F 使 F(A) = G' ,其中 ,且 G' ≈ G 。
(2)如何找到对应关系 F
如果通过变换 F 实现从矩形框 A 变为矩形框 G' 呢?比较简单的思路就是 平移 + 放缩 ,具体实现步骤如下:
① 先平移:
② 后缩放:
这里要学习的变换是 ,当输入的锚框 A 与 G 相差较小时,可以认为这四个变换是一种线性变换,这样就可以用线性回归来建模对矩形框进行微调。线性回归是指给定输入的特征向量 X ,学习一组参数 W ,使得经过线性回归后的值与真实值 G 非常接近,即 G ≈ WX 。那么锚框中的输入以及输出分别是什么呢?
输入:
这些坐标实际上对应 CNN 网络的特征图,训练阶段还包括目标框的坐标值,即 。
输出:4 个变换, ,
,
,
输入与输出之间的关系:
由此可知训练的目标就是使预测值 与真实值
的差最小化,用 L1 来表示:
为了更好地收敛,我们实际使用 smooth-L1 作为其目标函数:
(3)边框回归为何只能微调?
要使用线性回归,就要求锚框 A 与 G 相乘较小,否则这些变换可能会变成复杂的非线性变换。
(4)边框回归的主要应用
在 RPN 生成候选框的过程中,最后输出时也使用边框回归使预测框不断向目标框逼近。
(5)改进空间
YOLO v2 提出了一种 直接预测位置坐标 的方法。之前的坐标回归实际上回归的不是坐标点,而是需要对预测结果做一个变换才能得到坐标点,这种方法使其在充分利用目标对象的位置信息方面的效率大打折扣。
为了更好地利用目标对象的位置信息,YOLO v2 采用 目标对象的中心坐标 及 左上角 的方法,具体可参考图 9-20 。

其中, 和
为锚框的宽和高,
、
、
、
为预测边界框的坐标值,
是 sigmoid 函数。
、
是当前网格左上角到图像左上角的距离,需要将网格 大小归一化 ,即令一个网格的 宽 = 1 ,高 = 1 。
4、SPP-Net
候选区域通过处理最后由全连接层进行分类或回归,而全连接层一般是固定大小的输入。为此,我们需要把候选区域的输出结果设置为固定大小,有两种固定方法:
1. 第一种方法是直接对候选区域进行缩放,不过这种方法容易导致对象变形,进而影响识别效果;
3. 第二种方法是使用 空间金字塔池化网络(Spatial Pyramid Pooling Net, SPP-Net)方法或在此基础上延伸的 RoI 池化 方法。
空间金字塔池化网络 SPP-Net 对每个候选框使用了不同大小的金字塔映射,如 4×4 ,2×2 ,1×1 等。
空间金字塔池化网络 SPP-Net 由何恺明、孙健等人提出,其主要创新点就是 空间金字塔池化(Spatial Pyramid Pooling, SPP)。
空间金字塔池化网络 SPP-Net 成功解决了 R-CNN 中每个候选区域都要过一次 CNN 的问题,提升了效率,并避免了为适应 CNN 的输入尺寸而缩放图像导致目标形状失真的问题。
SPP-Net 是自适应的池化方法,分别对 输入特征图 进行 多个尺度 的池化,得到特征,进行向量化后拼接起来,如图 9-21 所示。
- 输入特征图:可以由不定尺寸的输入图像输入 CNN 得到,也可以由候选区域框定后输入 CNN 得到。
- 多个尺度:实际上就是改变池化的大小和步幅。

与普通池化的固定大小不同( 普通池化的大小和步幅相等,即每一步都不重叠 ),SPP-Net 固定的是池化后的尺寸 ,而大小则是根据尺寸计算得到的自适应数值来确定。这样可以保证不论输入是什么尺寸,输出的尺寸都是一致的,从而得到定长的特征向量。
图 9-22 是使用 SPP-Net 把一个 4×4 RoI 用 2×2 ,1×1 的大小池化到固定长度的示意图。

SPP-Net 对特征图中的候选框进行了多尺寸( 如 5×5 ,2×2 ,1×1 等 )池化,然后展平、拼接成固定长度的向量。
RoI 对特征图中的候选框只需要下采样到一个尺寸,然后对各网格采用最大池化方法,得到固定长度的向量。
Fast R-CNN 及 Faster R-CNN 都采用了 RoI 池化方法。以 VGG-16 的主干网络为例,RoI 将候选框下采样到 7×7 的尺寸。



