
kafka日志存储
前言
kafka的主题(topic)可以对应多个分区(partition),而每个分区(partition)可以有多个副本(replica),我们提生产工单创建topic的时候也是要预设这些参数的。但是它究竟是如何存储的呢?
我们在使用kafka发送消息时,实际表现是提交日志,日志记录会一个接一个地追加到日志的末尾,同时为了避免单一日志文件过大无线膨胀,kafka采用了日志分段(LogSegment)的形式进行存储。所谓日志分段,就是当一个日志文件大小到达一定条件之后,就新建一个新的日志分段,然后在新的日志分段写入数据。每个日志段对象会在磁盘上创建一组文件,包括消息日志文件(.log)、位移索引文件(.index)、时间戳索引文件 (.timeindex),也就是说日志段才是kafka真正的日志文件存储基础单元。
整个主题、分区、副本、日志关系如下:
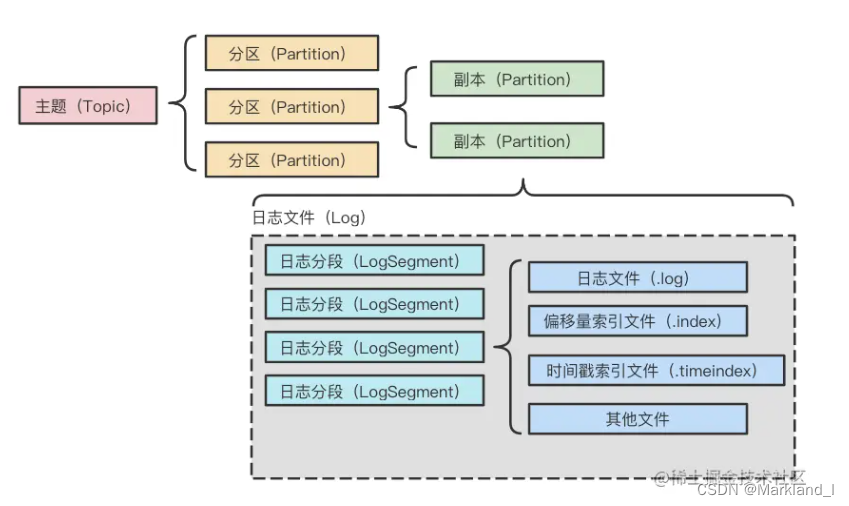
以__consumer_offsets这个topic为例,每一个目录对应一个分区,说明dev环境下这个topic有50个分区,每个子目录下存在多组日志段,也就是多组.log、.index、.timeindex 文件组合。
进入/tmp/kafka-logs/__consumer_offset-49目录,下图中文件名的一串数字0是该日志段的起始位移值(Base Offset),也就是该日志段中所存的第一条消息的位移值,由此也可以推测出0000000000000000000.log中共有20条日志记录
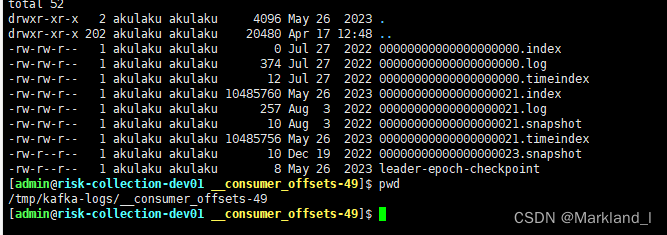
配置
前面是从生产配置和kafka目录的文件直观看到消息相关的内容,下面引入几个kafka消息相关的配置。
日志清理策略
kafka log的清理策略有两种:delete,compact,默认是delete
- delete:一般是使用按照时间保留的策略,当不活跃的segment的时间戳是大于设置的时间的时候,当前segment就会被删除
- compact: 日志不会被删除,会被去重清理,这种模式要求每个record都必须有key,然后kafka会按照一定的时机清理segment中的key,对于同一个key只保留最新的那个key。同样的,compact也只针对不活跃的segment
对应的配置是log.cleanup.policy: delete,对应topic级别的配置是cleanup.policy
消息保存时长
Kafka 支持服务器级保留策略,我们可以通过配置三个基于时间的配置属性之一来调整该策略:
-
log.retention.hours
-
log.retention.minutes
-
log.retention.ms
其默认配置是log.retention.hours=168,即默认保留7天, Kafka自身会用较高精度值覆盖较低精度值。因此,如果在配置中新增log.retention.minutes=10,消息的保留时间将会变更位10分钟
上面这个配置是服务器级别的,配置在server.properties中,每次新增创建topic时,如果不指定topic的日志保留时间,以上述配置为例,消息的保留时长就是7天,如果配置retention.ms=600000,这是从log.retention.minutes派生而来的,这个参数是topic级别的,配置了这个值,就会以这个值为准,创建topic之后,仍然可以单独调整retention.ms,来调整topic的保留时间
segment相关配置
segment有两个很重要的配置
-
log.segment.bytes
-
log.roll.hours
目前风控kafka上述两个配置都是默认值,见下图,log.segment.bytes是1G,log.roll.hours是7d,这两个配置在后续分析segment相关原理时还会再详细介绍

segment扫描频率的配置,日志片段文件检查的周期时间,目前生产配置为5min
-
log.retention.check.interval.ms

原理
为什么要看源码?因为检索了kafka的官方文档,关于segment的单独说明极少,网上检索到的资料又没有足够的说服力,所以最终决定还是从源码中寻找相关问题的答案
kafka源码搭建
当前风控系统使用的kafka是1.1版本,随机下载了相关源码,由于kafka是用scala编写的,并用gradle进行打包处理,也进行了相关程序的下载,对应的版本见下述列出,感兴趣的同事可以按如下版本下载,解压编译kafka源码,然后就可以在idea中查看了
- kafka源码版本:1.1
- scala版本:2.12.7
- gradle版本:4.7
LogConfig
该scala定义了Defaults object,scala中的Object可以看成java中的util类,存放了很多常量
- log.segment.bytes: 1GB
- log.roll.ms: 168hour
- log.retention.bytes: -1
- log.retention.ms: 168hour
LogSegment
正如前文中介绍的,segment才是kafka存储单元的基础部分,随之找到了相关类LogSegment.scala
变量声明
它的参数定义如下,可以查看它的注释,明确的支出了segment是由log和index组成的,这也与我们前面查看kafka目录中对应的日志文件呼应了
/** * A segment of the log. Each segment has two components: a log and an index. The log is a FileMessageSet containing * the actual messages. The index is an OffsetIndex that maps from logical offsets to physical file positions. Each * segment has a base offset which is an offset any offset in * any previous segment. * * A segment with a base offset of [base_offset] would be stored in two files, a [base_offset].index and a [base_offset].log file. * * @param log The message set containing log entries * @param offsetIndex The offset index * @param timeIndex The timestamp index * @param baseOffset A lower bound on the offsets in this segment * @param indexIntervalBytes The approximate number of bytes between entries in the index * @param time The time instance */ @nonthreadsafe @nonthreadsafe class LogSegment private[log] (val log: FileRecords, val offsetIndex: OffsetIndex, val timeIndex: TimeIndex, val txnIndex: TransactionIndex, val baseOffset: Long, val indexIntervalBytes: Int, val rollJitterMs: Long, val maxSegmentMs: Long, val maxSegmentBytes: Int, val time: Time) extends Logging { ....... }针对segment的成员变量,重点看以下几个
- baseOffset:消息偏移量,即文件名,对于一组sgement,它都是固定的,它就是该日志段中第一条消息的位移值,一共20位,不足的话前面补0,每个日志段对象保存自己的起始位移 baseOffset,这是非常重要的属性,在源码中经常看到它的使用!事实上,你在磁盘上看到的文件名就是 baseOffset 的值。每个 LogSegment 对象实例一旦被创建,它的起始位移就是固定的了,不能再被更改。
- maxSegmentBytes:每段最大字节数,该参数越大,日志被切成的segment就越少,控制粒度也就变小了,通过代码debug发现这个参数取决于配置【log.segment.bytes】,目前风控系统中配置为1G
- maxSegmentMs:每段保留有效毫秒数,每个segment在写入一段时间的日志后,即使log还没有达到maxSegmentBytes最大值,kafka也会强制日志滚动,以确保可以删除或者压缩旧数据,该参数取决于【log.roll.ms】或【log.roll.hours】,当前者不存在时,取后者,后者目前在生产环境中配置为168h
- rollJitterMs:是日志段对象新增倒计时的“扰动值”。因为目前 Broker 端日志段新增倒计时是全局设置,这就是说,在未来的某个时刻可能同时创建多个日志段对象,这将极大地增加物理磁盘 I/O 压力。有了 rollJitterMs 值的干扰,每个新增日志段在创建时会彼此岔开一小段时间,这样可以缓解物理磁盘的 I/O 负载瓶颈。这个变量给我的感觉有点像设置缓存时间加的随机值,避免缓存同时过期。
shouldRoll方法
segment是否应该进行切分(roll)
def shouldRoll(messagesSize: Int, maxTimestampInMessages: Long, maxOffsetInMessages: Long, now: Long): Boolean = { val reachedRollMs = timeWaitedForRoll(now, maxTimestampInMessages) > maxSegmentMs - rollJitterMs size > maxSegmentBytes - messagesSize || (size > 0 && reachedRollMs) || offsetIndex.isFull || timeIndex.isFull || !canConvertToRelativeOffset(maxOffsetInMessages) }- timeWaitedForRoll(now, maxTimestampInMessages):1. 如果此segment的第一个消息的时间戳存在,就用当前的新的batch的时间戳,减去此segment第一条消息的的时间戳判断是否已经超过segments.ms,2. 如果此segments的第一个消息的时间戳不存在,就用当前系统时间与此segment创建的时间差做判断。
- reachedRollMs就表示,是否超过上述日志写入事件差值是否超过【log.roll.hours】
- size > maxSegmentBytes - messagesSize:当前 activeSegment 在追加本次消息之后,长度超过 LogSegment 允许的最大值【log.segment.bytes】
- offsetIndex.isFull || timeIndex.isFull:索引文件是否满了
- !canConvertToRelativeOffset(maxOffsetInMessages):这个变量涉及到offset的相对位移概念,后面再介绍
append方法
// Update the in memory max timestamp and corresponding offset. if (largestTimestamp > maxTimestampSoFar) { maxTimestampSoFar = largestTimestamp offsetOfMaxTimestamp = shallowOffsetOfMaxTimestamp }我这次分享的重点都是跟segment的写入和删除相关的,所以只重点介绍与之相关的内容,下面的源码解析也是这个思路 在append方法中,即往segment写入消息时,也会同步更新segment的最大时间戳以及最大时间戳所属消息的位移值属性。每个日志段都要保存当前最大时间戳信息和所属消息的位移信息。在 Broker 端的提供定期删除日志功能中,比如我只想保留最近 7 天的日志,此处的当前最大时间戳这个值就是判断的依据;Log
Log 对象是 Kafka 源码(特别是 Broker 端)最核心的部分,没有之一。 日志是日志段的容器,里面定义了很多管理日志段的操作。object Log
“.deleted”
.deleted 是删除日志段操作创建的文件。目前删除日志段文件是异步操作,Broker 端把日志段文件从.log 后缀修改为.deleted 后缀。如果你看到一大堆.deleted 后缀的文件名,别慌,这是 Kafka 在执行日志段文件删除。
filenamePrefixFromOffset def filenamePrefixFromOffset(offset: Long): String = { val nf = NumberFormat.getInstance() nf.setMinimumIntegerDigits(20) nf.setMaximumFractionDigits(0) nf.setGroupingUsed(false) nf.format(offset) }这个方法的作用是通过给定的位移值计算出对应的日志段文件名。Kafka 日志文件固定是20 位的长度,filenamePrefixFromOffset 方法就是用前面补 0 的方式,把给定位移值扩充成一个固定 20 位长度的字符串。
Log Class
/* the actual segments of the log */ private val segments: ConcurrentNavigableMap[java.lang.Long, LogSegment] = new ConcurrentSkipListMap[java.lang.Long, LogSegment]
为什么说Log是管理segment的容器,从这个字段就可以看出来,这是 Log 类中最重要的属性之一。它保存了分区日志下所有的日志段信息,只不过是用 Map 的数据结构来保存的。Map 的 Key 值是日志段的起始位移值,Value 则是日志段对象本身。Kafka 源码使用 ConcurrentNavigableMap 数据结构来保存日志段对象,就可以很轻松地利用该类提供的线程安全和各种支持排序的方法,来管理所有日志段对象。 它是键值(Key)可排序的 Map。Kafka 将每个日志段的起始位移值作为 Key,这样一来,我们就能够很方便地根据所有日志段的起始位移值对它们进行排序和比较,同时还能快速地找到与给定位移值相近的前后两个日志段。Log中删除Segment操作
三个留存策略
/** * Delete any log segments that have either expired due to time based retention * or because the log size is > retentionSize */ def deleteOldSegments(): Int = { if (!config.delete) return 0 deleteRetentionMsBreachedSegments() + deleteRetentionSizeBreachedSegments() + deleteLogStartOffsetBreachedSegments() }config.delete:配置的删除策略,要配置delete才会进行真实的删除操作 deleteRetentionMsBreachedSegments:其中的核心条件是(segment, _) => startMs - segment.largestTimestamp > config.retentionMs,这是一个匿名函数,startMs是当前时间,largestTimestamp 正是上文提到的LogSegment在每次写入日志时都会修改的最大时间戳,config.retentionMs也是上文中提到过的配置【retention.ms】,即topic的保留时间 deleteRetentionSizeBreachedSegments:这个删除是受segment驱使,但是有个条件retention.bytes>0,但是目前生产环境这个配置是-1,所以生产环境的kafka实际是不会触发超过指定大小后的删除策略的 deleteLogStartOffsetBreachedSegments:下一个日志分段的起始偏移量 baseOffset 是否小于等于 logStartOffset,若是,则可以删除此日志分段消息量很少的情况
知道了上述删除策略后,重点分析一下当某个topic的消息数量很少的情况,即在segment在7天内,都没有因为超过segment的文件上线1G时,该segment则一直是active segment,该topic也只有这唯一一个segment 假设这个topic的过期时间是15天,第1天产生了1条消息,第7天产生了1条消息,此时不满足shouldRoll条件,不会切分segment,第13天又产生了一条消息,此时还是不满足shouldRoll条件,那什么时候会进行日志切分呢,当下一条消息产生的时间跟上一条消息产生的时间相差超过了7天,此时才会进行日志切分,所以存在一种可能性,对于这种消息产生量很少的日志可能永远不会过期,有点像缓存的续时,一直给续上了。asyncDeleteSegment
private def asyncDeleteSegment(segment: LogSegment) { segment.changeFileSuffixes("", Log.DeletedFileSuffix) def deleteSeg() { info(s"Deleting segment ${segment.baseOffset}") maybeHandleIOException(s"Error while deleting segments for $topicPartition in dir ${dir.getParent}") { segment.deleteIfExists() } } scheduler.schedule("delete-file", deleteSeg _, delay = config.fileDeleteDelayMs) }执行segment删除上一个异步操作,首先是同步在.log文件后面加上.deleted的后缀,然后通过定时器scheduler,1分钟延迟后异步删除
.log文件和.index文件
查看文件详情
查看log文件,以__consumer_offset topic为例
/data/app/kafka_2.12-2.6.0/bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files /tmp/kafka-logs/__consumer_offsets-49/00000000000000000000.log --print-data-log
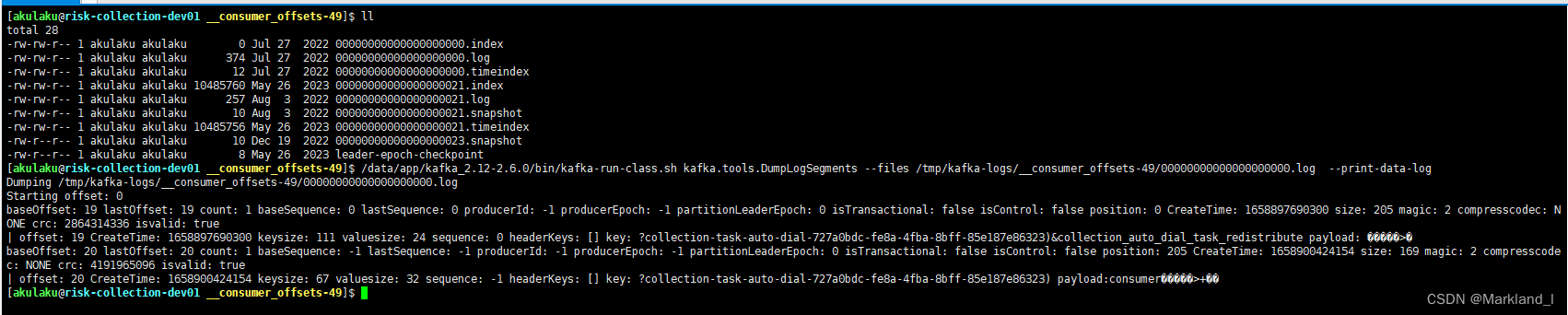
可以看到00000000000000000000.log的起始offset是19,最后一条offset是20,然后他的创建时间是1658900424154

又获取了00000000000000000021.log的文件详情,起始offset是21,创建时间是1659505428096,它与上一个segment的最后一条消息的时间差值是605003942,是大于7天的,所以是符合上述源码分析的,即超过了segment切分时间配置【log.roll.hours】
-
-
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们,邮箱:ciyunidc@ciyunshuju.com。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!



