
Time-LLM:为时间序列预测重新编程LLM 探索Time-LLM的架构,并在Python中将其应用于预测项目



参考资料:Time-LLM/ Reprogram an LLM for Time Series Forecasting.md
文章目录
- 探索Time-LLM
- 输入补丁化
- 重新编程层
- 使用提示前缀增强输入
- 输出投影
- 使用Time-LLM进行预测
- 在 neuralforecast 中扩展 Time-LLM
- 使用 Time-LLM 进行预测
- 使用 N-BEATS 和 MLP 进行预测
- 我对 Time-LLM 的看法
- 结论
- 参考文献

研究人员尝试将自然语言处理(NLP)技术应用于时间序列领域并非首次。
例如,Transformer架构在NLP领域是一个重要的里程碑,但其在时间序列预测方面的表现一直平平,直到PatchTST的提出。
正如您所知,大型语言模型(LLMs)正在积极开发,并在NLP领域展示出令人印象深刻的泛化和推理能力。
因此,值得探索将LLM重新用于时间序列预测的想法,以便我们可以从这些大型预训练模型的能力中受益。
为此,Time-LLM被提出。在原始论文中,研究人员提出了一个框架,重新编程现有的LLM以执行时间序列预测。
在本文中,我们将探讨Time-LLM的架构以及它如何有效地使LLM能够预测时间序列数据。然后,我们将实现该模型并将其应用于一个小型预测项目。
要了解更多详情,请务必阅读原始论文。
让我们开始吧!
探索Time-LLM
Time-LLM更应被视为一个框架,而不是一个具有特定架构的实际模型。
Time-LLM的一般结构如下所示。
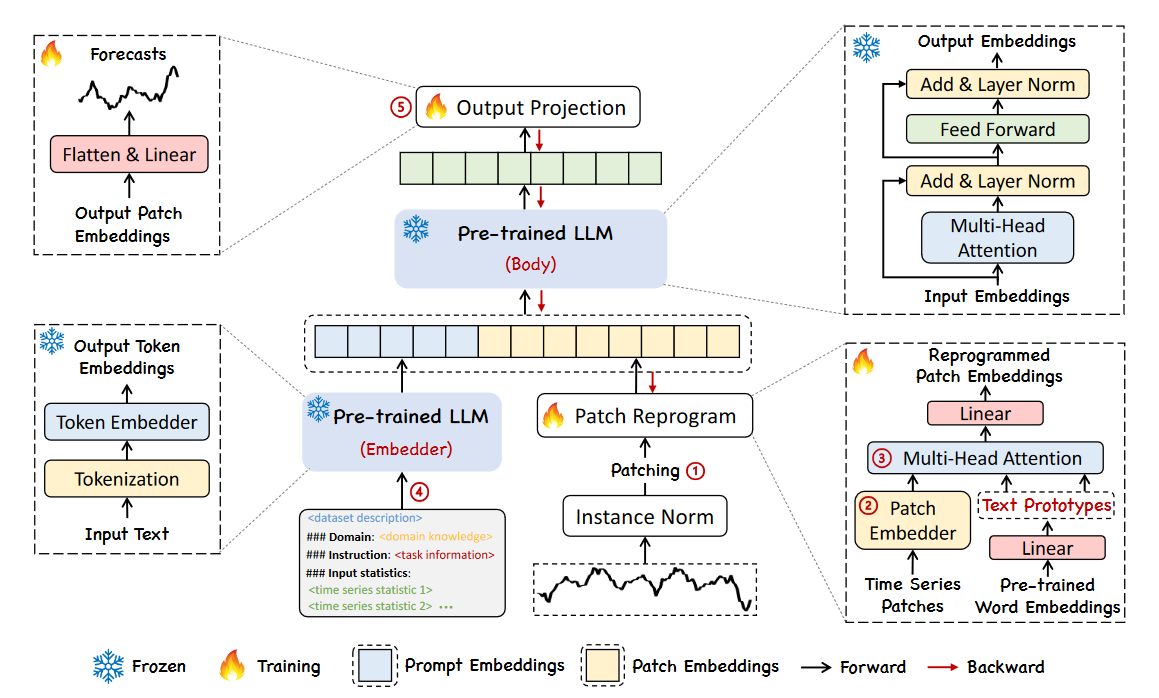
Time-LLM的一般结构。图片由M. Jin, S. Wang, L. Ma, Z. Chu, J. Zhang, X. Shi, P. Chen, Y. Liang, Y. Li, S. Pan, Q. Wen提供,来源为Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
Time-LLM的整个理念是重新编程一个嵌入可见的语言基础模型,如LLaMA或GPT-2。
请注意,这与微调LLM是不同的。相反,我们教导LLM接受一系列时间步的输入,并在一定的时间范围内输出预测。这意味着LLM本身保持不变。
在高层次上,Time-LLM首先通过自定义的补丁嵌入层对输入时间序列序列进行标记化。然后,这些补丁通过一个重新编程层,将预测任务本质上转化为语言任务。请注意,我们还可以传递一个提示前缀以增强模型的推理能力。最后,输出的补丁通过投影层,最终得到预测。
这里有很多内容需要深入探讨,让我们更详细地探讨每个步骤。
输入补丁化
第一步是对输入序列进行补丁化,就像在PatchTST中一样。

补丁化的可视化。这里,我们有一个包含15个时间步的序列,补丁长度为5,步长也为5,因此得到三个补丁。图片由作者提供。
通过补丁化,我们的目标是通过查看一组时间步而不是单个时间步来保留局部语义信息。
这样做的附加好处是大大减少了要馈送到重新编程层的标记数量。在这里,每个补丁都变成一个输入标记,因此将标记数量从L减少到大约L/S,其中L是输入序列的长度,S是步长。
补丁化完成后,输入序列被发送到重新编程层。
重新编程层
在Time-LLM中,语言模型保持不变。
现在,语言模型可以执行许多NLP任务,如情感分析、摘要和文本生成,但不能进行时间序列预测。
这就是重新编程层的作用。它本质上将输入时间序列映射到一个语言任务,使我们能够利用语言模型的能力。
为此,它使用受限词汇来描述每个输入补丁,如下所示。
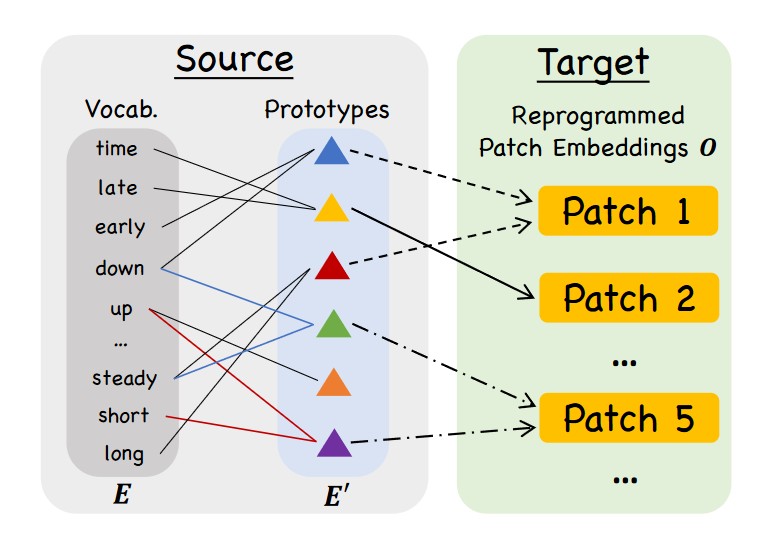
将输入补丁转换为语言任务。图片由M. Jin, S. Wang, L. Ma, Z. Chu, J. Zhang, X. Shi, P. Chen, Y. Liang, Y. Li, S. Pan, Q. Wen提供,来源为Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
在上图中,我们可以看到每个时间序列补丁是如何描述的。例如,一个补丁可以被翻译为“短期上涨然后稳步下降”。通过这种方式,我们有效地将时间序列的行为编码为自然语言输入,这正是LLM所期望的。
完成此操作后,翻译后的补丁被发送到多头注意力机制,然后进行线性投影,以将重新编程的补丁的维度与LLM骨干的维度对齐。
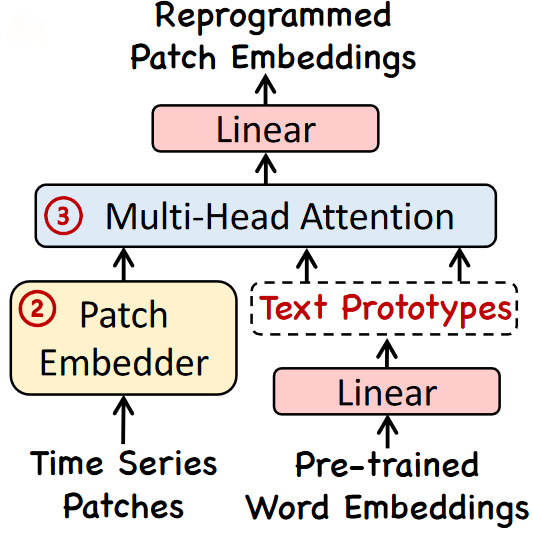
重新编程层的整体架构。图片由M. Jin, S. Wang, L. Ma, Z. Chu, J. Zhang, X. Shi, P. Chen, Y. Liang, Y. Li, S. Pan, Q. Wen提供,来源为Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
请注意,重新编程层是一个经过训练的层。我们可以决定为特定数据集对其进行训练,或者预先训练它并将Time-LLM用作零-shot预测器。
现在,在翻译后的补丁实际发送到LLM之前,可以使用提示前缀来增强输入。
使用提示前缀增强输入
为了激活LLM的能力,我们使用一个提示,即指定LLM任务的自然语言输入。
现在,即使我们传递了被翻译为自然语言的时间序列补丁,对LLM来说仍然是一个挑战进行预测。
因此,研究人员建议使用提示前缀来补充补丁重新编程。

提示前缀的示例。图片由M. Jin, S. Wang, L. Ma, Z. Chu, J. Zhang, X. Shi, P. Chen, Y. Liang, Y. Li, S. Pan, Q. Wen提供,来源为Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
在上图中,我们看到了一个在基准数据集ETT上的提示前缀示例。
提示包含三个不同部分:
- 数据集的一般背景
- 任务说明
- 输入统计信息
第一个组件完全由用户定义。在这里,我们可以指定关于数据集的信息,解释其背景并写出观察结果。
然后,任务说明根据预测的时间范围和系列的输入大小进行程序化设置。
最后,输入统计信息也是根据输入系列自动计算的。请注意,使用快速傅里叶变换计算出了前五个滞后。简而言之,它将输入系列转换为幅度和频率的函数,并认为具有最高幅度的频率更重要。
因此,在这一点上,我们有一个包含LLM上下文和说明的提示前缀,以及被发送到LLM的重新编程补丁序列,如下所示。

提示前缀和重新编程补丁被发送到LLM。最后一步是线性投影以获得最终预测。图片由M. Jin, S. Wang, L. Ma, Z. Chu, J. Zhang, X. Shi, P. Chen, Y. Liang, Y. Li, S. Pan, Q. Wen提供,来源为Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
该框架的最后一步是将输出补丁嵌入通过线性投影层以获得最终预测。
输出投影
一旦提示前缀和重新编程补丁被发送到LLM,它将输出补丁嵌入。
然后,必须将此输出展平并进行线性投影以得出最终预测,如下所示。
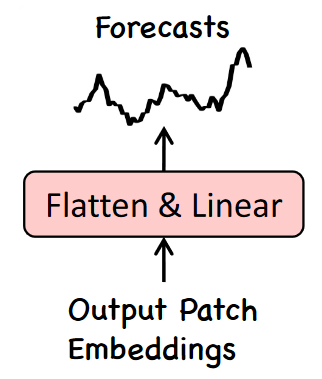
LLM的输出补丁嵌入被展平并线性投影以获得最终预测。图片由M. Jin, S. Wang, L. Ma, Z. Chu, J. Zhang, X. Shi, P. Chen, Y. Liang, Y. Li, S. Pan, Q. Wen提供,来源为Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
总结一下通过Time-LLM的流程:
- 首先对输入系列进行补丁化并重新编程为语言任务。
- 我们附加一个提示前缀,指定数据的上下文,LLM的说明以及输入统计信息。
- 将组合输入发送到LLM。
- 输出嵌入被展平并投影以生成预测。
现在我们了解了Time-LLM的内部工作原理,让我们在Python中进行一个小实验。
使用Time-LLM进行预测
在这个小实验中,我们将使用Time-LLM进行时间序列预测,并将其性能与其他模型(如N-HiTS和简单的多层感知器(MLP))进行比较。
在开始之前,我必须提到以下几点:
- 我将使用neuralforecast库扩展Time-LLM,因为我认为Time-LLM的原始代码库很难使用。
- 我不是最好的提示工程师,由于Time-LLM依赖于LLM,您可能会通过更好的上下文提示获得比我更好的结果。
- 我的时间和计算资源有限。我在单个 GPU 上对 Time-LLM 进行了 100 个 epochs 的训练。如果你有更多时间和更好的 GPU,你可以训练模型更长时间,可能会获得更好的结果。
这个实验的代码可以在 GitHub 上找到。
让我们开始吧!
在 neuralforecast 中扩展 Time-LLM
在这个实验中,我将在 neuralforecast 库中实现 Time-LLM,使其比论文中的实现更易于使用和更灵活。
遵循 neuralforecast 的贡献指南,我们首先创建一个继承自 BaseWindows 的 TimeLLM 类,该类负责解析输入时间序列的批次。
然后,在 __init__ 函数中,我们指定与 Time-LLM 相关的参数,然后是继承自 BaseWindows 的参数。
class TimeLLM(BaseWindows): def __init__(self, h, input_size, patch_len: int = 16, stride: int = 8, d_ff: int = 128, top_k: int = 5, d_llm: int = 768, d_model: int = 32, n_heads: int = 8, enc_in: int = 7, dec_in: int = 7, llm = None, llm_config = None, llm_tokenizer = None, llm_num_hidden_layers = 32, llm_output_attention: bool = True, llm_output_hidden_states: bool = True, prompt_prefix: str = None, dropout: float = 0.1, # 继承自 BaseWindows 的参数在上面的代码块中,我们看到了用于分块的参数,以及我们希望使用的 LLM 的参数。
与原始实现使用 LLaMA 不同,这个实现允许用户使用 transformers 库选择任何他们喜欢的 LLM。
然后,我们重用了原始实现的相同逻辑,但修改了 forward 方法以遵循 neuralforecast 的指导原则。
def forward(self, windows_batch): insample_y = windows_batch['insample_y'] x = insample_y.unsqueeze(-1) y_pred = self.forecast(x) y_pred = y_pred[:, -self.h:, :] y_pred = self.loss.domain_map(y_pred) return y_pred在上面的代码块中,我们使用 windows_batch 访问输入批次并通过 Time-LLM 运行它。然后,我们使用 self.loss.domain_map(y_pred) 将输出映射到所选损失函数的域和形状。这对于模型实际训练是必要的。
要查看详细的实现,可以在这里查看(该实现仍在积极开发中,因此在您阅读此内容时可能会发生变化)。
然后,我们只需将模型添加到适当的 init 文件中,然后运行 pip install . 即可访问新模型。
就这样,我们现在可以在 neuralforecast 中使用 Time-LLM 了。
使用 Time-LLM 进行预测
现在我们准备使用 Time-LLM 进行预测。在这里,我们使用简单的航空乘客数据集。
首先,让我们导入所需的库。
import time import numpy as np import pandas as pd import pytorch_lightning as pl import matplotlib.pyplot as plt from neuralforecast import NeuralForecast from neuralforecast.models import TimeLLM from neuralforecast.losses.pytorch import MAE from neuralforecast.tsdataset import TimeSeriesDataset from neuralforecast.utils import AirPassengers, AirPassengersPanel, AirPassengersStatic, augment_calendar_df from transformers import GPT2Config, GPT2Model, GPT2Tokenizer
然后,我们加载数据集,这个数据集方便地包含在 neuralforecast 中。
AirPassengersPanel, calendar_cols = augment_calendar_df(df=AirPassengersPanel, freq='M') Y_train_df = AirPassengersPanel[AirPassengersPanel.ds=AirPassengersPanel['ds'].values[-12]].reset_index(drop=True)
接下来,我们需要选择一个 LLM。在这个实验中,让我们选择 GPT-2。我们可以从 transformers 加载模型、配置和分词器。
gpt2_config = GPT2Config.from_pretrained('openai-community/gpt2') gpt2 = GPT2Model.from_pretrained('openai-community/gpt2',config=gpt2_config) gpt2_tokenizer = GPT2Tokenizer.from_pretrained('openai-community/gpt2')然后,我们可以定义一个提示来解释数据的上下文。在这里,我使用了以下提示:
prompt_prefix = "The dataset contains data on monthly air passengers. There is a yearly seasonality"
然后,我们可以使用以下方式初始化模型:
timellm = TimeLLM(h=12, input_size=36, llm=gpt2, llm_config=gpt2_config, llm_tokenizer=gpt2_tokenizer, prompt_prefix=prompt_prefix, max_steps=100, batch_size=24, windows_batch_size=24)请注意,我只训练了重编程层 100 个 epochs,并且使用了相对较小的批量大小。如果你有更多的计算资源,增加 max_steps、batch_size 和 windows_batch_size 可能会更好。
然后,我们可以训练模型并进行预测。
nf = NeuralForecast( models=[timellm], freq='M' ) nf.fit(df=Y_train_df, val_size=12) forecasts = nf.predict(futr_df=Y_test_df)
使用 GPT-2 进行 Time-LLM 预测的可视化。图片由作者提供。
在上图中,我们可以看到我们成功地使用 GPT-2 模型获得了时间序列预测,我认为这是令人兴奋和惊人的!
然而,预测结果并不理想。高峰完全被忽略了,甚至趋势在这种情况下似乎也没有被考虑。
现在,有许多因素可以提高性能,比如:
- 将模型训练时间延长。我训练了 100 个 epochs,但论文使用了 1000 个 epochs。
- 更改 LLM。我使用了 GPT-2,但论文中使用的 LLaMA 要好得多。也许使用 Mistral 模型或 Gemma 会有所帮助。
- 更好的提示。我的提示非常简单,也许我们可以更好地设计它。
请记住,目标是向您展示如何在自己的用例中使用 Time-LLM,并不是为了获得最先进的结果。尽管我的资源有限,但我们仍然可以使用任何我们想要的 LLM 来预测任何时间序列数据集,这才是这个实现的真正优势。
尽管如此,为了完整起见,让我们将 Time-LLM 与其他模型进行比较。
使用 N-BEATS 和 MLP 进行预测
我的 Time-LLM 运行并没有产生最佳预测,但让我们仍然使用其他模型来看看它们的表现。
具体来说,我们使用 N-BEATS 和一个简单的 MLP 模型。在这里,我将仅训练 100 个 epochs,但请随时延长训练时间。
nbeats = NBEATS(h=12, input_size=36, max_steps=100) mlp = MLP(h=12, input_size=36, max_steps=100) nf = NeuralForecast(models=[nbeats, mlp], freq='M') nf.fit(df=Y_train_df, val_size=12) forecasts = nf.predict(futr_df=Y_test_df)

展示 Time-LLM、N-BEATS 和 MLP 的预测。图片由作者提供。
毫不奇怪,N-BEATS 和 MLP 的表现比 Time-LLM 要好得多,但再次,请记住,我的 Time-LLM 运行远未经过优化。
然后,让我们使用平均绝对误差(MAE)来评估性能。
from neuralforecast.losses.numpy import mae mae_timellm = mae(Y_test_df['y'], Y_test_df['TimeLLM']) mae_nbeats = mae(Y_test_df['y'], Y_test_df['NBEATS']) mae_mlp = mae(Y_test_df['y'], Y_test_df['MLP']) data = {'Time-LLM': [mae_timellm], 'N-BEATS': [mae_nbeats], 'MLP': [mae_mlp]} metrics_df = pd.DataFrame(data=data) metrics_df.index = ['mae'] metrics_df.style.highlight_min(color='lightgreen', axis=1)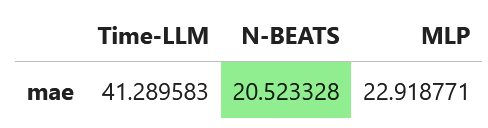
航空乘客数据集上所有模型的 MAE。N-BEATS 实现了最佳性能。图片由作者提供。
在这种情况下,N-BEATS 实现了最佳性能,因为它具有最低的 MAE。
再次强调,Time-LLM 的结果可能令人失望,但有许多方法可以改进我的实验,因为我之前提到过我的资源有限。
此外,这只是在一个简单的玩具数据集上进行的非常简单的实验。目标是展示如何在任何情况下使用 Time-LLM,而不是将模型与其他方法进行基准测试。
我对 Time-LLM 的看法
LLM 在自然语言处理领域代表了一大飞跃,随着它们在计算机视觉中的应用,看到它们被应用于时间序列预测是合情合理的。
但是,我会在预测项目中使用 Time-LLM 吗?
可能不会。
事实是,Time-LLM 需要大量的计算资源和内存。毕竟,我们正在使用一个 LLM。
事实上,当使用他们的脚本复现论文中的结果时,使用 GPU 在单个数据集上训练 1000 个 epochs 大约需要 19 小时!
此外,LLM 占用大量内存空间,对于非常大的模型,数十亿的参数通常会占用几个千兆字节。相比之下,我们可以在几分钟内训练轻量级深度学习模型,并获得非常好的预测结果。
出于这些原因,我认为在可能提高预测准确性与运行此类模型所需的计算资源和内存存储之间的权衡是不值得的。
尽管如此,看到时间序列预测现在可以从 LLM 的进步中受益,这是一个积极研究的领域,这令人兴奋。如果 LLM 变得更好、更轻,也许 Time-LLM 将成为一个有趣的选择。
结论
它首先对输入序列进行修补,将其标记化并重新编程为一项语言任务,通过训练一个重新编程层。
它还添加了提示前缀,为LLM提供数据集的上下文、预测任务和一些输入统计信息。
然后,通过保持LLM模型完整,我们可以将重新编程的修补程序和提示传递给LLM,并获得预测结果。
就像往常一样,我认为每个问题都需要其独特的解决方案。请确保将Time-LLM与其他方法进行测试。
参考文献
Time-LLM: Time Series Forecasting by Reprogramming Large Language Models by M. Jin, S. Wang, L. Ma, Z. Chu, J. Zhang, X. Shi, P. Chen, Y. Liang, Y. Li, S. Pan, Q. Wen
Time-LLM的原始代码库 — GitHub df_pattern







