
Scrapy 爬取m3u8视频
Scrapy 爬取m3u8视频
【一】效果展示
- 爬取ts文件样式
- 合成的MP4文件

【二】分析m3u8文件路径
- 视频地址:[在线播放我独自升级 第03集 - 高清资源](https://www.physkan.com/ph/175552-8-3.html)
【1】找到m3u8文件
- 这里任务目标很明确
- 就是找m3u8文件
- 打开浏览器
- 进入开发者模式F12
- 搜索m3u8文件
- 查看响应内容含有ts文件的m3u8文件
- 再次查看标头地址即可
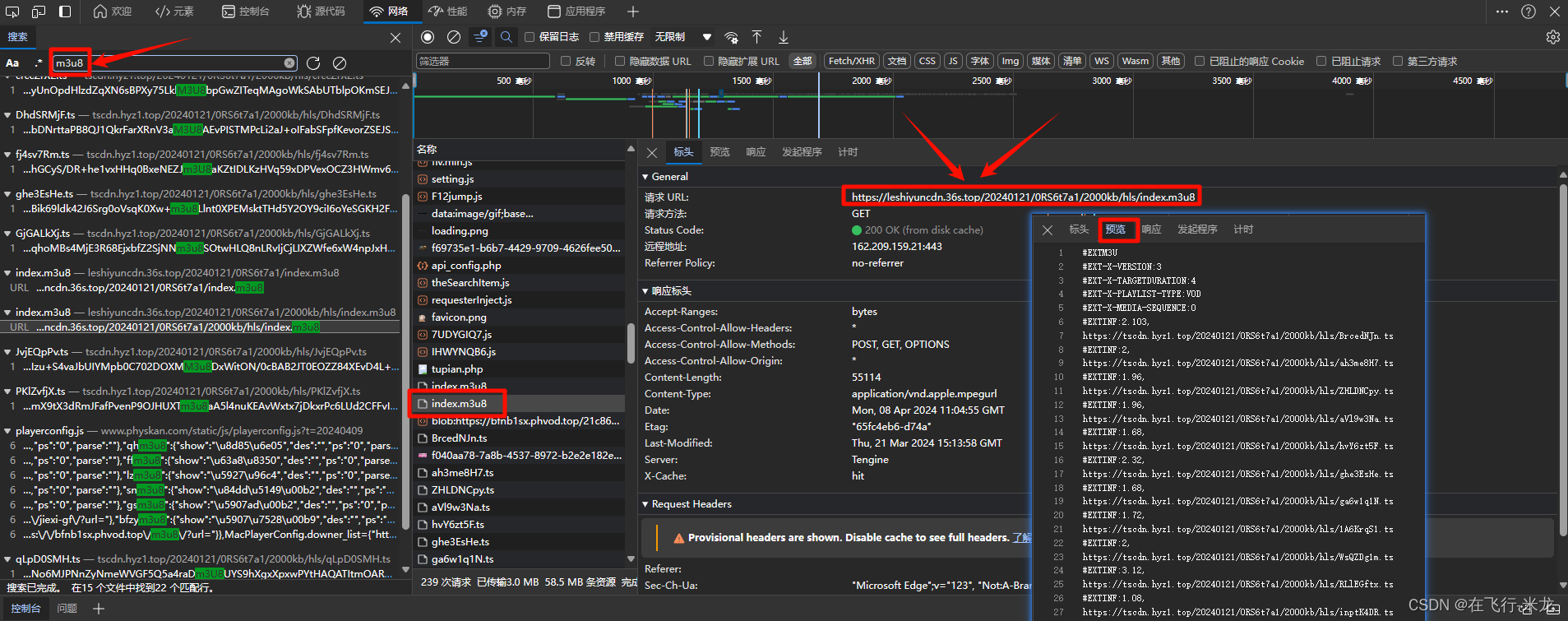
【2】分析m3u8路径
- https://leshiyuncdn.36s.top/20240121/0RS6t7a1/2000kb/hls/index.m3u8
- 按照/拆分:leshiyuncdn.36s.top----20240121----0RS6t7a1----2000kb----hls
- 笨办法:一个个的进行搜索
- 查看哪个找到m3u8的路径
- 其中搜索leshiyuncdn.36s.top这个的时候
- 查看响应中含有m3u8地址
- 那么就继续分析这个地址
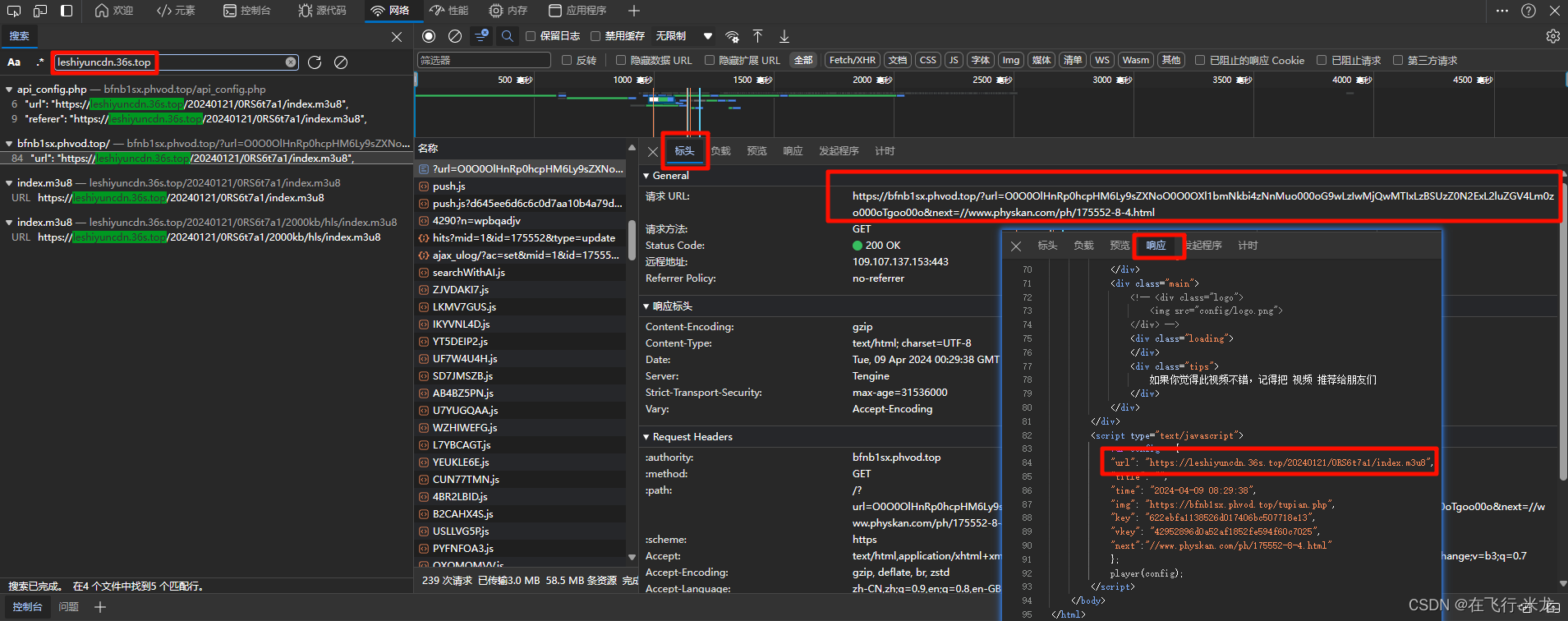
- https://bfnb1sx.phvod.top/?url=O0O0OlHnRp0hcpHM6Ly9sZXNoO0O0OXl1bmNkbi4zNnMuo000oG9wLzIwMjQwMTIxLzBSUzZ0N2ExL2luZGV4Lm0zo000oTgoo00o&next=//www.physkan.com/ph/175552-8-4.html
- 同样的采用笨方法:拆分一个一个的找
- 在搜索O0O0OlHnRp0hcpHM6Ly9sZXNoO0O0OXl1bmNkbi4zNnMuo000oG9wLzIwMjQwMTIxLzBSUzZ0N2ExL2luZGV4Lm0zo000oTgoo00o的时候
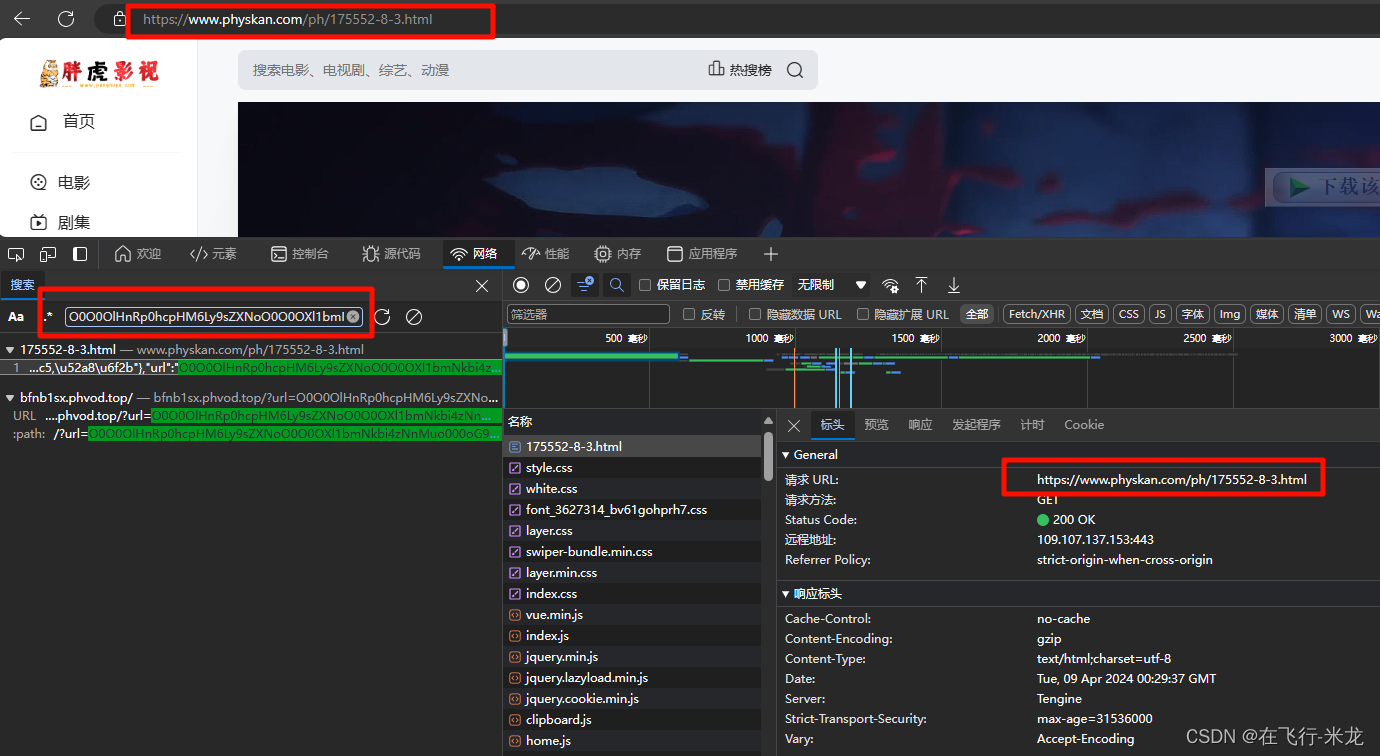
- 找到https://www.physkan.com/ph/175552-8-3.html里面含有我们搜索的内容
- 并且这个地址就是浏览器的访问视频的地址
- 好了,就是它了
【三】scrapy代码
【1】基础内容
class M3U8Spider(scrapy.Spider): # 爬虫文件名 name = "m3u8" # 可访问的域名列表 allowed_domains = ["www.physkan.com", 'bfnb1sx.phvod.top', 'leshiyuncdn.36s.top', 'tscdn.hyz1.top'] # 起始地址 start_urls = [ "https://www.physkan.com/ph/175552-8-3.html"] # 视频存储路径 video_path = os.path.join(os.path.dirname(os.path.dirname(os.path.dirname(__file__))), 'video') # 确保文件创建好 os.makedirs(video_path, exist_ok=True) # m3u8文件路径 m3u8_path = os.path.join(video_path, 'index.m3u8') # ts文件路径 ts_info_path = os.path.join(video_path, 'ts.txt')【2】分析获取m3u8路径
- 我们需要的数据发现在script的player_aaaa中
- 正则匹配,json格式转换为字典格式,方便读取数据
- 其中url含有我们需要的路径参数,但是不全
- 所以补全路径发起请求
def parse(self, response): # 获取网页源码 page_source = response.text # 分析源码可以发现需要的地址在script的player_aaaa中 # 通过正则匹配获取 pattern = r'var player_aaaa=({.*?})' url_info_str = re.findall(pattern, page_source, re.DOTALL)[0] # json格式转换为字典,方便拿数据 url_info_dict = json.loads(url_info_str) # 拼接m3u8路径 m3u8_info_url = 'https://bfnb1sx.phvod.top/?url=' + url_info_dict['url'] yield scrapy.Request(url=m3u8_info_url, callback=self.get_m3u8_url)- 这个地址还并非是直接的m3u8路径
- 同样的获取m3u8路径参数
- 拼接完整路径参数,就可以得到m3u8的真正路径
def get_m3u8_url(self, response): page_source = response.text pattern = r'var config = ({.*?})' m3u8_info_str = re.findall(pattern, page_source, re.DOTALL)[0] m3u8_info_dict = json.loads(m3u8_info_str) m3u8_url = m3u8_info_dict['url'] m3u8_url = m3u8_url.rsplit('/', 1)[0] + '/2000kb/hls/index.m3u8' yield scrapy.Request(url=m3u8_url, callback=self.get_ts_list)【3】获取过滤ts
- 通过上面的地址获取到了index.m3u8文件
- 先保存在本地一份,方便查看
- 使用正则表达式过滤出ts视频
- 还要保存一份ts文件路径在本地
- 因为接下来使用ffmpeg工具进行视频合成
- 格式要求:file '视频路径.ts'
- 最后异步发起ts视频文件请求
def get_ts_list(self, response): # 获取页面txt信息 page_source = response.text # 保存在index.m3u8文件在本地 with open(self.m3u8_path, mode='wt', encoding='utf8') as fp: fp.write(page_source) # 使用正则过滤拿出ts路径 ts_urls = re.findall(r'https://tscdn.hyz1.top/[^\s]+.ts', page_source) # 保存的ts视频文件需要按照合成视频ffmpeg的格式拼接 with open(self.ts_info_path, mode='wt', encoding='utf8') as fp: for ts in ts_urls: file_name = ts.rsplit('/', 1)[-1] file_path = os.path.join(self.video_path, file_name) # 保存ts文件,保存的为ts文件路径 fp.write(f"file '{file_path}'" + '\n') # 异步发起ts视频文件的请求 yield scrapy.Request(url=ts, callback=self.save_ts_file, meta={'file_path': file_path})(3.1)小插曲
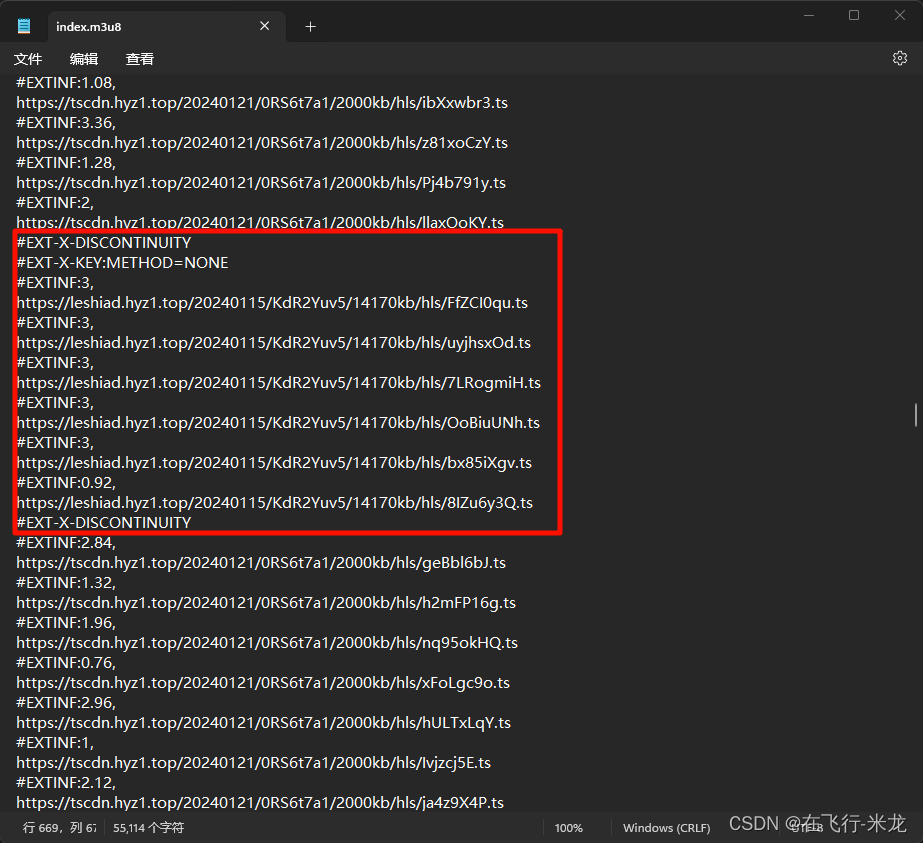
- 在m3u8文件中
- 你会发现这个不一样的地址
- 其实这部分是广告,可以过滤掉
【4】保存ts文件、合成MP4文件
- 首先进行ts文件保存
- 这个没有什么好说的
- 直接保存吧
def save_ts_file(self, response): # 保存ts文件本地 file_path = response.meta.get('file_path') with open(file_path, mode='wb') as fp: fp.write(response.body) # 输出日志写不写都行 self.log(f'保存成功:>>>{file_path.rsplit("/", 1)[-1]}')-
拼接ts文件为MP4视频文件
-
需要用的工具是ffmpeg
-
官网:Download FFmpeg
-
去安装配置好环境变量即可
-
合成MP4视频
- 首先使用os模块切换到保存的ts文件路径下
- 然后执行ffmpeg命令
- ffmpeg -f concat -safe 0 -i ts.txt -c copy output.mp4
- ts.txt是之前的保存的ts文件路径文件
- 格式要求:file '视频路径.ts'
- output.mp4是合成后的mp4文件
- 可自定义文件名等
def close(spider, reason): # 爬虫执行完毕以后,拼接视频 工具:ffmpeg os.chdir(f'{spider.video_path}') os.system(f'ffmpeg -f concat -safe 0 -i ts.txt -c copy output.mp4')免责声明
-
本爬虫仅用于收集特定网站的信息,目的是进行数据分析,不得用于非法目的或侵犯他人隐私。对于因使用本爬虫造成的任何损失或法律责任,本人概不负责。
-
本爬虫的数据可能存在不准确、不完整或不可用的情况,对于用户或第三方可能因此造成的任何损失,本人概不负责。
-
- 可自定义文件名等
-
-
- 首先进行ts文件保存
- 在m3u8文件中
- 通过上面的地址获取到了index.m3u8文件
- 这个地址还并非是直接的m3u8路径
- 我们需要的数据发现在script的player_aaaa中
- https://bfnb1sx.phvod.top/?url=O0O0OlHnRp0hcpHM6Ly9sZXNoO0O0OXl1bmNkbi4zNnMuo000oG9wLzIwMjQwMTIxLzBSUzZ0N2ExL2luZGV4Lm0zo000oTgoo00o&next=//www.physkan.com/ph/175552-8-4.html
- https://leshiyuncdn.36s.top/20240121/0RS6t7a1/2000kb/hls/index.m3u8
- 这里任务目标很明确
- 视频地址:[在线播放我独自升级 第03集 - 高清资源](https://www.physkan.com/ph/175552-8-3.html)
- 合成的MP4文件
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们,邮箱:ciyunidc@ciyunshuju.com。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!



