
数据挖掘|关联分析与Apriori算法详解


.png)


数据挖掘|关联分析与Apriori算法
- 1. 关联分析
- 2. 关联规则相关概念
- 2.1 项目
- 2.2 事务
- 2.3 项目集
- 2.4 频繁项目集
- 2.5 支持度
- 2.6 置信度
- 2.7 提升度
- 2.8 强关联规则
- 2.9 关联规则的分类
- 3. Apriori算法
- 3.1 Apriori算法的Python实现
- 3.2 基于mlxtend库的Apriori算法的Python实现
1. 关联分析
关联规则分析(Association-rules Analysis)是数据挖掘领域的一个重要方法,它是以某种方式分析数据源,从数据样本集中发现一些潜在有用的信息和不同数据样本之间关系的过程。
关联是指在两个或多个变量之间存在某种规律性,但关联并不一定意味着因果关系。
关联规则是寻找在同一事件中出现的不同项目的相关性,关联分析是挖掘关联规则的过程。
比如在一次购买活动中所买不同商品的相关性。
关联分析即利用关联规则进行数据挖掘。
关联规则是形式如下的一种规则,“在购买计算机的顾客中,有30%的人也同时购买了打印机”。
从大量的商务事务记录中发现潜在的关联关系,可以帮助人们作出正确的商务决策。
关联规则分析于1993年由美国IBM Almaden Research Center 的 Rakesh Agrawal 等人在进行市场购物篮分析时首先提出的,用以发现超市销售数据库中的顾客购买模式,现在已经广泛应用于许多领域。
早期关联分析用于分析零售企业顾客的购物行为模式,所以关联分析又被称为购物篮分析。
关联规则也可用于商品货架布置、销售配置、存货安排、购物路线设计、商品陈列设计、交叉销售以及根据购买模式对用户进行分类等方面。
比较经典的关联规则是啤酒和尿布的故事。
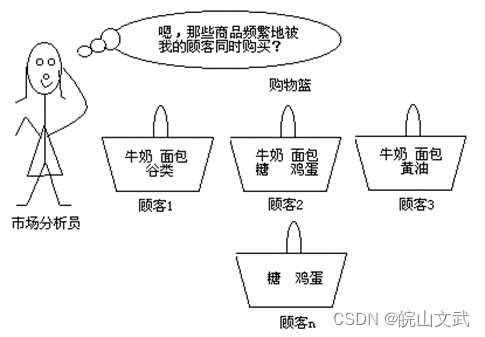
2. 关联规则相关概念
2.1 项目
集合 I = i 1 , i 2 , . . . , i m I={i_1,i_2,...,i_m} I=i1,i2,...,im称为项集合,其中 m m m为正整数, i k ( k = 1 , 2 , … , m ) i_k(k=1,2,…,m) ik(k=1,2,…,m)称为项目。
项目是一个从具体问题中抽象出的一个概念。在超市的关联规则挖掘问题中,项目表示各种商品,如旅游鞋等。
2.2 事务
由于在超市的关联规则挖掘中并不关心顾客购买的商品数量和价格等,因此顾客的一次购物可以用该顾客所购买的所有商品的名称来表示,称为事务,所有事务的集合构成关联规则挖掘的数据集,称为事务数据库。
关联规则挖掘的数据库记为 D D D,事务数据库 D D D中的每个元组称为事务。一条事务 T T T是 I I I中项目的集合。一条事务仅包含其涉及到的项目,而不包含项目的具体信息。在超级市场的关联规则挖掘问题中事务是顾客一次购物所购买的商品,但事务中并不包含这些商品的具体信息,如商品的数量、价格等。
2.3 项目集
项目集是由 I I I中项目构成的集合。若项目集包含的项目数为 k k k,则称此项目集为 k − k- k−项目集。任意的项目集 X X X和事务 T T T若满足 T ⊇ X T\supseteq X T⊇X,则称事务 T T T包含项目集 X X X。在超市的关联规则挖掘问题中项目集可以看成一个或多个商品的集合。若某顾客一次购买所对应的事务T包含项目集 X X X,就说该顾客在这次购物中购买了项目集 X X X中的所有商品。
2.4 频繁项目集
对任意的项目集 X X X,若事务数据库 D D D中的事务包含项目集 X X X的比例为 ε \varepsilon ε,则项目集的支持率为 ε \varepsilon ε,记为 s u p p o r t ( X ) = ε support(X)= \varepsilon support(X)=ε,其中包含项目集 X X X的事务数称为项目集 X X X的频度,记为 c o u n t ( X ) count(X) count(X)。若项目集 X X X的支持率大于或等于用户指定的最小支持率(minsupport),则项目集 X X X称为频繁项目集(或大项目集),否则项目集 X X X为非频繁项目集(或小项目集)。如果数据库 D D D中的事务数记为 ∣ D ∣ |D| ∣D∣,频繁项目集是至少被 ε ∣ D ∣ \varepsilon |D| ε∣D∣条事务包含的项目集.
2.5 支持度
关联规则是形如 U → V U\rightarrow V U→V的规则,其中 U 、 V U、V U、V为项集,且 U ∩ V = ∅ U\cap V = \emptyset U∩V=∅。项集 U 、 V U、V U、V不一定包含于同一个项集合 I I I。
关联规则的支持度 s ( U → V ) s(U\rightarrow V) s(U→V)和置信度 c ( U → V ) c(U\rightarrow V) c(U→V)是度量项目关联的重要指标,它们分别描述了一个关联规则的有用性和确定性。
在事务数据库 D D D中,关联规则 U → V U\rightarrow V U→V的支持度为:
s ( U → V ) = s u p p o r t c o u n t ( U ∪ V ) ∣ D ∣ s(U\rightarrow V)= \frac{support_{count}(U\cup V)}{|D|} s(U→V)=∣D∣supportcount(U∪V)
支持度描述了 X 、 Y X、Y X、Y这两个事务在事务集 D D D中同时出现(记为 X ∪ Y X\cup Y X∪Y)的概率。
2.6 置信度
关联规则 U → V U\rightarrow V U→V的置信度是指同时包含 X 、 V X、V X、V的事务数与包含 V V V的事务数之比,它用来衡量关联规则的可信程度。记为:
c ( U → V ) = s u p p o r t c o u n t ( U ∪ V ) s u p p o r t c o u n t ( U ) c(U\rightarrow V)= \frac{support_{count}(U\cup V)}{support_{count}(U)} c(U→V)=supportcount(U)supportcount(U∪V)
其中, s u p p o r t c o u n t ( U ∪ V ) support_{count}(U\cup V) supportcount(U∪V)是包含项集 U ∪ V U\cup V U∪V的事务数; s u p p o r t c o u n t ( U ) support_{count}(U) supportcount(U)是包含项集 U U U的事务数;
一般情况下,只有关联规则的置信度大于或等于预设的阈值,就说明了它们之间具有某种程度的相关性,这才是一条有价值的规则。
如果关联规则置信度大于或等于用户给定的最小置信度阈值,则称关联规则是可信的。
2.7 提升度
提升度(Lift)是指当销售一个商品A时,另一个商品B销售率会增加多少。计算公式为:
L i f t ( A → B ) = C d e n c e ( A → B ) s u p p o r t c o u n t ( A ) Lift(A \rightarrow B)=\frac{C_dence(A \rightarrow B)}{support_{count}(A)} Lift(A→B)=supportcount(A)Cdence(A→B)
假设关联规则’牛奶’ → \rightarrow →’鸡蛋’的置信度为C_dence(’牛奶’=>’鸡蛋’)=2/4,牛奶的支持度S_port(’牛奶’)=3/5,则’牛奶’和’鸡蛋’的支持度Lift(’牛奶’=>’鸡蛋’)=0.83。
- 当关联规则A=>B的提升度值大于1的时候,说明商品A卖得越多,B也会卖得越多;
- 当提升度等于1则意味着商品A和B之间没有关联;
- 当提升度小于1则意味着购买商品A反而会减少B的销量。
2.8 强关联规则
若关联规则 X → Y X\rightarrow Y X→Y的支持度和置信度分别大于或等于用户指定的最小支持率 m i n s u p p o r t minsupport minsupport和最小置信度 m i n c o n f i d e n c e minconfidence minconfidence,则称关联规则 X → Y X\rightarrow Y X→Y为强关联规则,否则称关联规则 X → Y X\rightarrow Y X→Y为弱关联规则。
关联规则挖掘的核心就是要找出事务数据库 D D D中的所有强相关规则。
2.9 关联规则的分类
关联规则可以分为布尔型和数值型。
布尔型关联规则处理的项目都是离散的,显示了这些变量之间的关系。
例如,性别=“女”——>职业=“秘书”。
数值型关联规则可以和多维关联或多层关联规则结合起来。对数值型属性进行处理,参考连续属性离散化方法或统计方法对其进行分割,确定划分的区间个数和区间宽度。数值型关联规则中也可以包含可分类型变量。
例如,性别=“女”——>平均收入>2300, 这里的收入是数值类型,所以是一个数值型关联规则。
基于规则中项目的抽象层次,可以分为单层关联规则和多层关联规则。项目(概念)通常具有层次性。
例如:
- 牛奶——>面包[20%, 60%]
- 酸牛奶——>黄面包[6%, 50%]
基于规则包含的项目维数,关联规则可以分为单维和多维两种。
单维关联规则处理单个项目的关系,多维关联规则处理多个项目之间的某些关系。
例如:
- 单维关联规则:buys(x,“diapers”)——>buys(x,“beers”)[0.5%, 60%]
- 多维关联规则:major(x,“CS”)^takes(x,“DB”)——>grade(x,“A”)[1%, 75%]
分离关联规则(dissociation rule),也称为负相关模式。
分离关联规则与一般的关联规则相似,知识在关联规则中出现项目的反转项,在购物篮分析中可发现不在一起购买的商品。
例如,购买牛奶的顾客一般不购买汽水。
3. Apriori算法
Apriori算法的基本思想是找出所有的频繁项集,然后由频繁项集产生强关联规则,这些规则必须满足最小支持度和最小置信度。
Apriori算法一般分为以下两个阶段:
- 第一阶段:找出所有超出最小支持度的项集,形成频繁项集。
- 首先通过扫描数据集,产生一个大的候选项集,并计算每个候选项集发生的次数,然后基于预先给定的最小支持度生成一维项集 L 1 L_1 L1。再基于 L 1 L_1 L1和数据集中的事务,产生二维项集 L 2 L_2 L2;依此类推,直到生成 N N N维项集 L N L_N LN,并且已经不可能再生成满足最小支持度的 N + 1 N+1 N+1维项集。这样就依此产生项集 L 1 , L 2 , … , L N {L_1,L_2,…,L_N} L1,L2,…,LN。
- 第二阶段:利用频繁项集产生所需的规则。
- 对给定的
L
L
L,如果
L
L
L包含其非空子集
A
A
A,假设用户给定的最小支持度和最小置信度阈值分别为
m
i
n
S
_
p
o
r
t
minS\_port
minS_port和
m
i
n
C
_
d
e
n
c
e
minC\_dence
minC_dence,并满足
m
i
n
S
_
p
o
r
t
(
L
)
/
m
i
n
S
_
p
o
r
t
(
A
)
≥
m
i
n
C
_
d
e
n
c
e
minS\_port(L)/ minS\_port(A) \geq minC\_dence
minS_port(L)/minS_port(A)≥minC_dence,则产生形式为
A
=
>
L
−
A
A=>L-A
A=>L−A的规则。
在这两个阶段中,第一阶段是算法的关键。一旦找到了项集,关联规则的导出是自然的。事实上,我们一般只对满足一定的支持度和可信度的关联规则感兴趣。挖掘关联规则的问题就是产生支持度和置信度分别大于用户给定的最小支持度和最小置信度的关联规则。
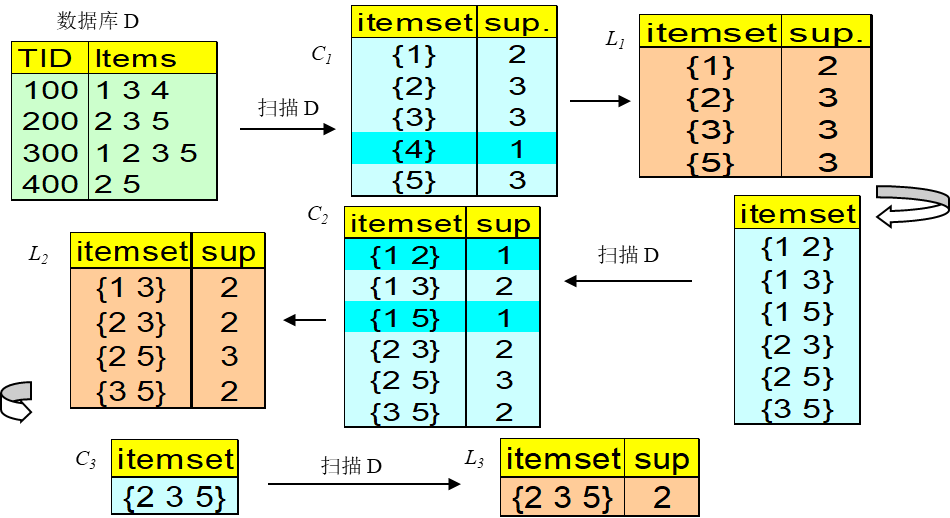
3.1 Apriori算法的Python实现
import numpy as np data_set = np.array([['鸡蛋','面包','西红柿','葱','蒜','牛奶'], ['面包','牛奶'],['鸡蛋','牛奶','豆角'], ['鸡蛋','牛奶','芹菜'],['鸡蛋','西红柿','豆角']],dtype=object) def get_C1(data_set): C1 = set() for item in data_set: for l in item: C1.add(frozenset([l])) return C1 #data_set -- 数据集;C-- 候选集;min_support -- 最小支持度 def getLByC(data_set, C, min_support): L = {} #频繁项集和支持数 for c in C: for data in data_set: if c.issubset(data): if c not in L: L[c] = 1 else: L[c] += 1 errorKeys=[] for key in L: support = L[key] / float(len(data_set)) if support = min_conf and big_rule not in big_rules: big_rules.append(big_rule) sub_sets.append(fset) return big_rules if __name__ == "__main__": min_support = 0.4 #最小支持度 min_conf = 0.6 #最小置信度 L,support_data = get_L(data_set, 3, min_support)#获取所有的频繁项集 big_rule = get_rule(L, support_data, min_support, min_conf) #获取强关联规则 print('==========所有的频繁项集如下===========') for l in L: for l_item in l: print(l_item, end=' ') print('支持度为:%f'%l[l_item]) print('===========================================') for rule in big_rule: print(rule[0],'==>',rule[1],'\t\tconf = ',rule[2])==========所有的频繁项集如下=========== frozenset({'面包'}) 支持度为:0.400000 frozenset({'豆角'}) 支持度为:0.400000 frozenset({'西红柿'}) 支持度为:0.400000 frozenset({'鸡蛋'}) 支持度为:0.800000 frozenset({'牛奶'}) 支持度为:0.800000 =========================================== frozenset({'西红柿', '鸡蛋'}) 支持度为:0.400000 frozenset({'鸡蛋', '牛奶'}) 支持度为:0.600000 frozenset({'牛奶', '面包'}) 支持度为:0.400000 frozenset({'豆角', '鸡蛋'}) 支持度为:0.400000 =========================================== =========================================== frozenset({'西红柿'}) ==> frozenset({'鸡蛋'}) conf = 1.0 frozenset({'牛奶'}) ==> frozenset({'鸡蛋'}) conf = 0.7499999999999999 frozenset({'鸡蛋'}) ==> frozenset({'牛奶'}) conf = 0.7499999999999999 frozenset({'面包'}) ==> frozenset({'牛奶'}) conf = 1.0 frozenset({'豆角'}) ==> frozenset({'鸡蛋'}) conf = 1.03.2 基于mlxtend库的Apriori算法的Python实现
Sklearn库中没有Apriori算法。但是可以采用Python的第三方库实现Aprior算法发掘关联规则。相关的库有mlxtend机器学习包等,首先需要导入包含Apriori算法的mlxtend包:pip install mlxtend。
Apriori()函数常用形式为:
L,suppData=apriori(df, min_support=0.5,use_colnames=False,max_len=None)
参数说明:
- (1) df:表示给定的数据集。
- (2) min_support:表示给定的最小支持度。
- (3) use_colnames:默认False,表示返回的项集,用编号显示。如果值为True则直接显示项名称。
- (4) max_len:默认是None,表示最大项组合数,不做限制。如果只需要计算两个项集,可将这个值设置为2。
返回值:
- (1)L:返回频繁项集。
- (2)suppData:返回频繁项集的相应支持度。
示例代码如下:
from mlxtend.preprocessing import TransactionEncoder from mlxtend.frequent_patterns import apriori from mlxtend.frequent_patterns import association_rules import pandas as pd df_arr = [['鸡蛋','面包','西红柿','葱','蒜','牛奶'], ['面包','牛奶'],['鸡蛋','牛奶','豆角'], ['鸡蛋','牛奶','芹菜'],['鸡蛋','西红柿','豆角']] #转换为算法可接受模型(布尔值) te = TransactionEncoder() df_tf = te.fit_transform(df_arr) df = pd.DataFrame(df_tf,columns=te.columns_) #设置支持度求频繁项集 frequent_itemsets = apriori(df,min_support=0.4,use_colnames= True) #求关联规则,设置最小置信度为0.15 rules = association_rules(frequent_itemsets,metric = 'confidence',min_threshold = 0.6) #设置最小提升度 rules = rules.drop(rules[rules.lift 'antecedents':'from','consequents':'to','support':'sup','confidence':'conf'},inplace = True) rules = rules[['from','to','sup','conf','lift']] print(rules)
- 对给定的
L
L
L,如果
L
L
L包含其非空子集
A
A
A,假设用户给定的最小支持度和最小置信度阈值分别为
m
i
n
S
_
p
o
r
t
minS\_port
minS_port和
m
i
n
C
_
d
e
n
c
e
minC\_dence
minC_dence,并满足
m
i
n
S
_
p
o
r
t
(
L
)
/
m
i
n
S
_
p
o
r
t
(
A
)
≥
m
i
n
C
_
d
e
n
c
e
minS\_port(L)/ minS\_port(A) \geq minC\_dence
minS_port(L)/minS_port(A)≥minC_dence,则产生形式为
A
=
>
L
−
A
A=>L-A
A=>L−A的规则。

(上)")

")
