
python爬取腾讯在线文档存excel+mysql
温馨提示:这篇文章已超过378天没有更新,请注意相关的内容是否还可用!
一、网页分析
进入到腾讯文档首页,按F12调出开发者工具,选择要爬取的在线文档。
过滤掉一些静态文件加载的请求,我们只看ajax请求。

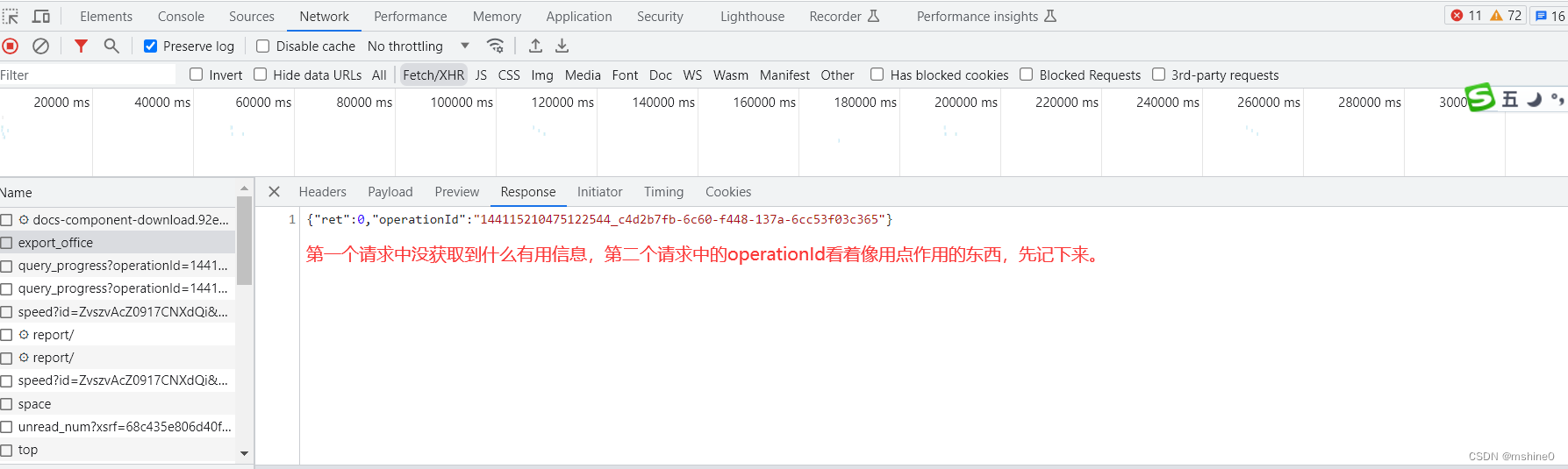

将file_url粘贴到浏览器地址栏中访问,发现直接将要爬取的url下载到了本地,所以这个file_url很有用。

这个file_url是我们通过对https://docs.qq.com/v1/export/query_progress?operationId=144115210475122544_c4d2b7fb-6c60-f448-137a-6cc53f03c365这个url发送get请求得到的。

在这个请求中有一个operationId,这个参数应该是动态的,有前面网页分析时,我们发现是第二个请求中获取的。
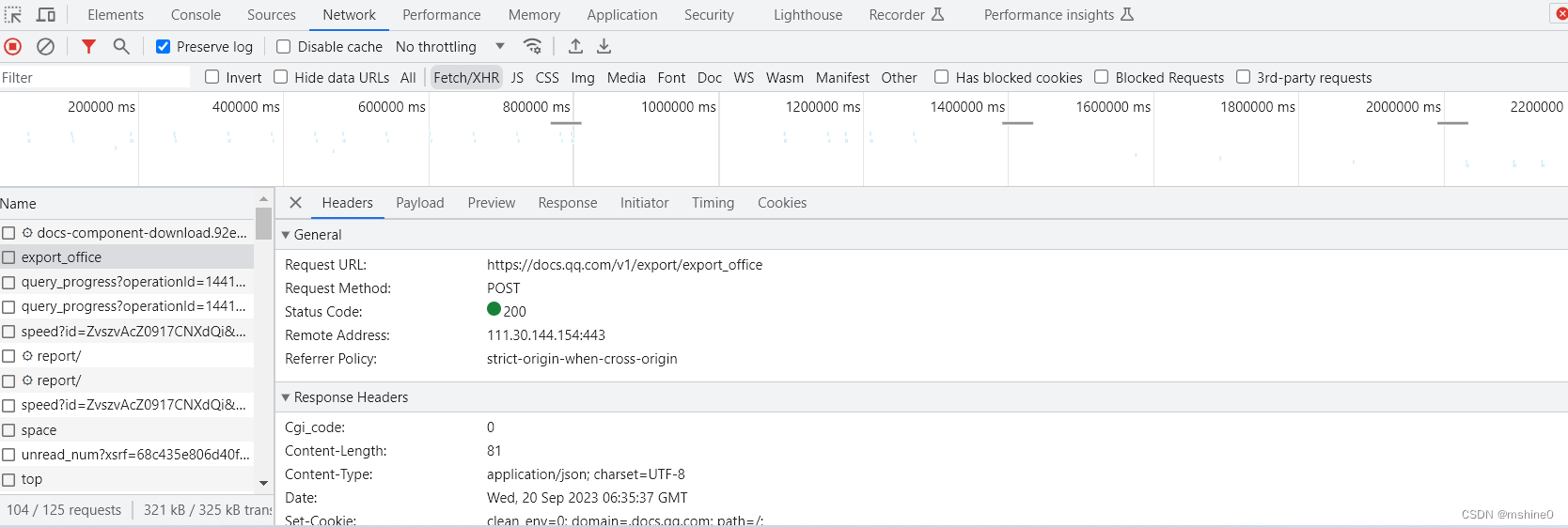
第二个请求是一个post请求,既然是Post请求,那它有携带哪些参数发请求呢?携带的参数是固定的?还是不固定的?
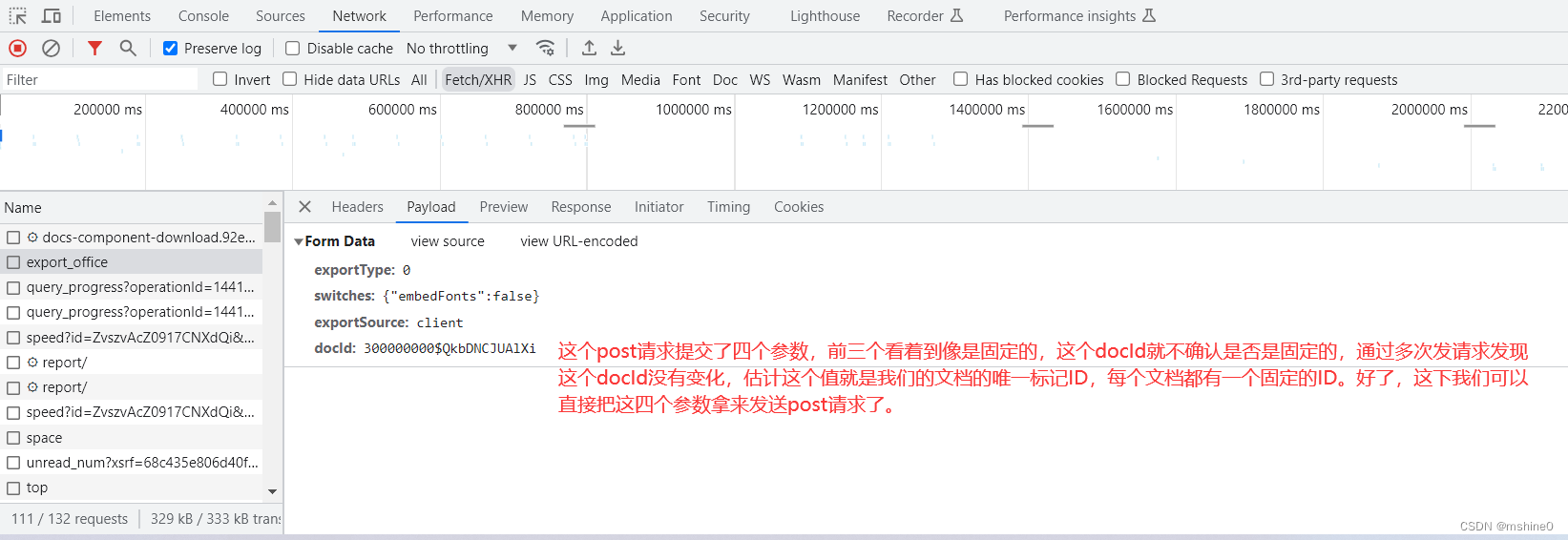
# 获取operationId
post_url = 'https://docs.qq.com/v1/export/export_office'
data = {
'exportType': 0,
'switches': '{"embedFonts":false}',
'exportSource': 'client',
'docId': '300000000$QkbDNCJUAlXi'
}
headers = {
'Cookie':
"pgv_pvid=8279808375; pac_uid=0_32c3497a7aa97; RK=uUc0DUIYc8; ptcz=fdc6d3b004fdd15dabc411388ac50c334dbac28deb693be65f7a525a99aff98e; traceid=e40c05660b; TOK=e40c05660bc3776b; hashkey=e40c0566; fingerprint=031c4e89321e464da97f3659b3a5941577; ES2=e6307a4ae907d2f8; optimal_cdn_domain=docs2.gtimg.com; low_login_enable=1; _qpsvr_localtk=0.37909772157735455; CheckKey=508fcd189e4733c72b49a4aaiqhgq1; uin=o0158279932; skey=@fQXEue8tH; luin=o0158279932; lskey=000100004ce1b9708c1e9ac475925f87b4ee385ac20f3018ff31f50cb7132c5a72ebf1f87daa9e99c86c06d6; p_uin=o0158279932; pt4_token=697uXPv70EY33d-4XakKaNq6cpiD0Ng*RbgbzCkpbwM_; p_skey=DmvA6AxQ-BhzY6*Wr1ozXBHnhwWypqNydzd0NOE6cXo_; p_luin=o0158279932; p_lskey=00040000cfde8b8c7dbb368520fbf713d02aa63ca0f526d53e1634e53ab4e6663a0e6dc655b169648a6afddd; uid=144115210475122544; utype=qq; vfwebqq=9b29ba465055b7be0537c62679248820df18df2344f949a654627e88209d713e30aaf82beba14be2; DOC_QQ_APPID=101458937; DOC_QQ_OPENID=44AA76ADE7427B2B852DAEF431FCE071; env_id=gray-pct50; gray_user=true; DOC_SID=793d63ffbcbd4af3876844ab8b78efc29f6ae71cf4ac402d8bbfb6b0a2643113; SID=793d63ffbcbd4af3876844ab8b78efc29f6ae71cf4ac402d8bbfb6b0a2643113; uid_key=EOP1mMQHGixwYWhodmpHMWdLNkExcDZMVE9YVzVhaUlJa2N3ZTNQZFF4UWFPREpabVg4PSJIggQMM5lU1fDUENHaoNvkPnk0cF2npZURPEmVDPvDMN3VPb6WrruC3fWbG9DgnDQ0nZ00ubsGgn1S8vK%2FxCEEN76HnUtqTyZqKIGmqakG; loginTime=1694680595505"
}
export_office_res = requests.post(url=post_url, data=data, headers=headers).json()
operationId = export_office_res['operationId']
通过以上代码我们动态获取到了operationId,带着这个参数我们接下来去获取文档的下载地址file_url这个参数。前面有说过对https://docs.qq.com/v1/export/query_progress?operationId=144115210475122544_c4d2b7fb-6c60-f448-137a-6cc53f03c365这个url发送了两次get请求才获取到了包含有file_url这个参数的结果,在实际测试中我发现有时要发送第三次请求才能获得。多次实验最多需要三次获取,如果你三次还没获取到,可以自己写循环多获取几次试试。
# 获取包含下载url的数据,要使用get访问两次这个接口才能得到包含下载url的数据包。 get_url = 'https://docs.qq.com/v1/export/query_progress?operationId=' + operationId res1 = requests.get(get_url, headers=headers) res2 = requests.get(get_url, headers=headers).json() file_url = res2['file_url']
二、数据存储
好了,现在拿到了文档下载地址file_url,我们可以把数据可视化放到excel中。
# 访问下载地址,将数据保存到excel
download = requests.get(url=file_url).content
f = open('F:\\aa\\test' + '.xlsx', 'wb')
f.write(download)
也可以将爬取的数据存入到mysql
import pymysql
import pandas as pd
import numpy as np # 导入numpy库用于处理 NaN 值
# 连接mysql数据库
db = pymysql.connect(host="127.0.0.1", port=3306, user="admin", password="123456", db="dxl", charset="utf8mb4")
cursor = db.cursor() # 创建一个游标对象
df = pd.read_excel(download)
excel_data = pd.read_excel(download)
# 数据存入mysql
for _, row in excel_data.iterrows():
row = row.replace({np.nan: None}) # 如果表中有空值一定要用numpy转一下,不然存数据库会报错
if row.empty:
print('excel表中没数据,请检查')
else:
query = "INSERT INTO s_bug_count (id, platform, product, module, problem, type, is_handle, operator, is_confirm) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s)"
values = tuple(row)
print(values)
cursor.execute(query, values)
db.commit()
cursor.close()
db.close()
以上几段代码拼一起就是完整代码了,如果有疑问,或者是指正的地方欢迎留言指正。
不吝赐教!



