
es文档操作命令
温馨提示:这篇文章已超过370天没有更新,请注意相关的内容是否还可用!
文档操作 documents
创建数据(put)
向 user 索引下创建3条数据
PUT /user/_doc/1
{
"name":"zhangsan",
"age":18,
"sex":"男",
"info":"一顿操作猛如虎,一看工资2500",
"tags":["计算机","运动","动漫"]
}
PUT /user/_doc/2
{
"name":"kunkun",
"age":3,
"sex":"男",
"info":"吉你实在实在太美",
"tags":["唱","跳","篮球"]
}
PUT /user/_doc/3
{
"name":"lisi",
"age":66,
"sex":"女",
"info":"清晨下的第一杯水",
"tags":["a","b","c"]
}

当执行命令时,如果数据不存在,则新增该条数据,如果数据存在则修改该条数据。
获取数据(get)
# get 索引名/类型名/id GET /user/_doc/1
结果:
{
"_index" : "user",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "zhangsan",
"age" : 18,
"sex" : "男",
"info" : "一顿操作猛如虎,一看工资2500",
"tags" : [
"计算机",
"运动",
"动漫"
]
}
}
更新数据(update)
覆盖更新(put)
PUT /user/_doc/1
{
# 更新的数据
"name":"wangwu"
}
结果:
{
"_index" : "user",
"_type" : "_doc",
"_id" : "1",
"_version" : 2, // 代表数据更改的次数
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 6,
"_primary_term" : 1
}
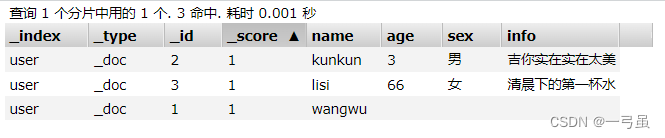
从结果中可以看到,我们更新的数据并不是更改了指定的字段,而是直接覆盖掉了原来的数据,这不符合我们的一般习惯,如果想要更新指定的字段,需要使用 post + _update 方式来更新
局部更新(post)
使用 post 命令,在 id 后面跟 _update,要修改的内容放到 doc 文档中即可。
POST /user/_doc/3/_update
{
"doc":{
"name":"zhangsan"
}
}
结果:
#! Deprecation: [types removal] Specifying types in document update requests is deprecated, use the endpoint /{index}/_update/{id} instead.
{
"_index" : "user",
"_type" : "_doc",
"_id" : "3",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 7,
"_primary_term" : 1
}
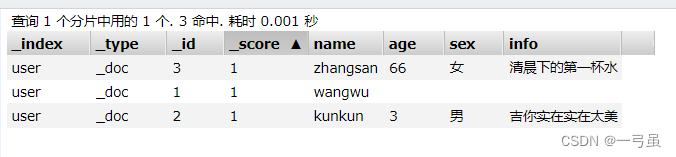
条件查询
使用 GET 命令,后加上_search?q=要查询的条件
# get /索引名/文档名/_search查询条件 GET /user/_doc/_search?q=name:zhangsan
结果:
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.9808291,
"hits" : [
{
"_index" : "user",
"_type" : "_doc",
"_id" : "3",
"_score" : 0.9808291,
"_source" : {
"name" : "zhangsan",
"age" : 66,
"sex" : "女",
"info" : "清晨下的第一杯水",
"tags" : [
"a",
"b",
"c"
]
}
}
]
}
}
我们看一下结果 返回并不是 数据本身,是给我们了一个 hits ,还有 _score 得分,就是根据算法算出和查询条件匹配度高得分就搞。
这里的查询是模糊查询,并会根据 ik 分词器进行匹配,但由于我们查询的字段name的类型是keyword(不可分词),故必须要精确匹配才能查询到
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们,邮箱:ciyunidc@ciyunshuju.com。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!



