
can‘t find model ‘zh
温馨提示:这篇文章已超过370天没有更新,请注意相关的内容是否还可用!
成功解决[E050] Can’t find model ‘en_core_web_sm’. It doesn’t seem to be a Python package or a valid path to a data directory.
直接上解决方案
步骤一:
豆瓣源安装spacy包
pip install spacy -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
步骤二:下载en_core_web_sm或者zh_core_web_sm包,缺哪个下载哪个
zh_core_web_sm
en_core_web_sm
spacy中文模型官网
spacy官网
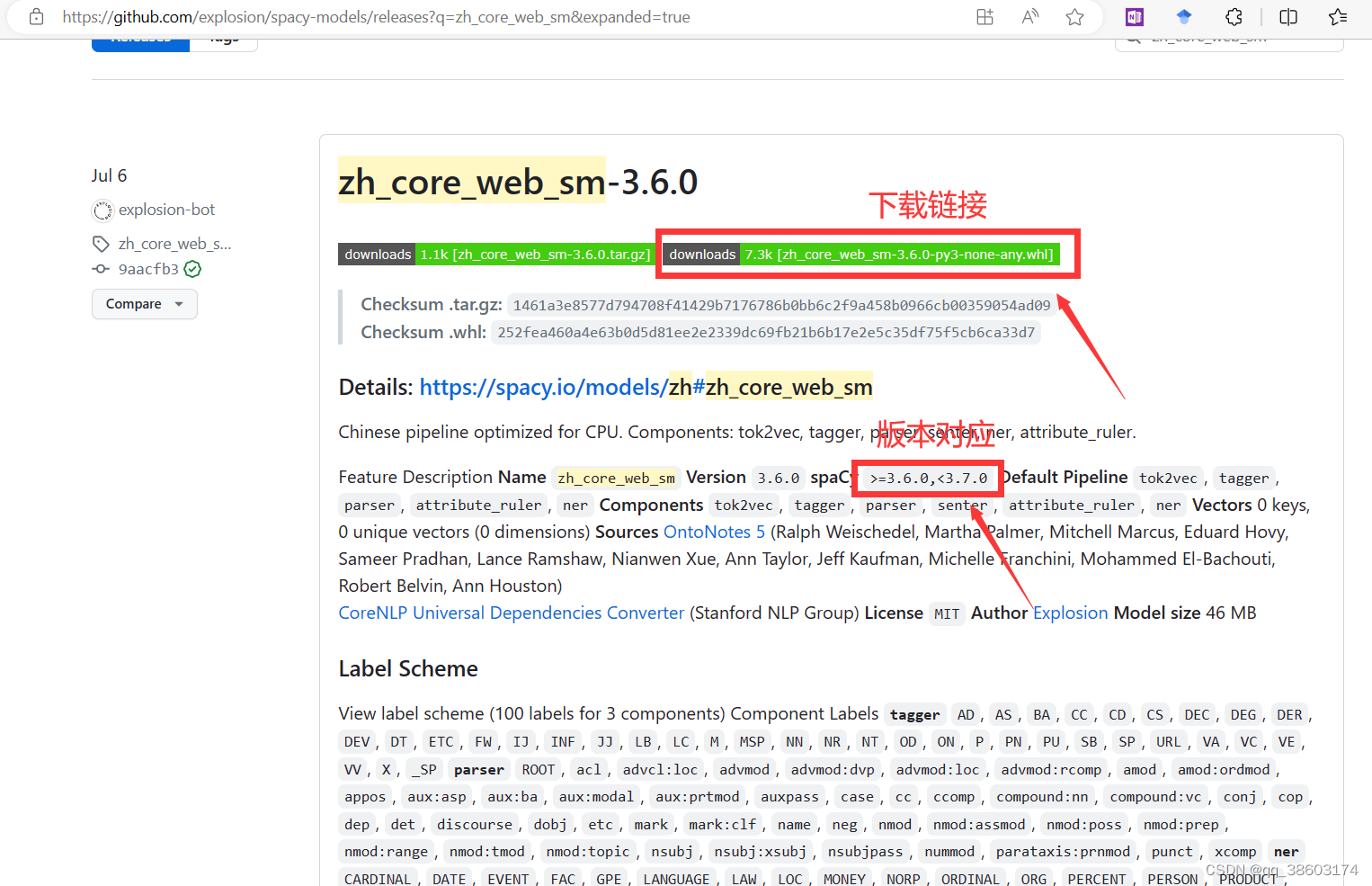
注意根据对应版本下载
步骤三:终端pip安装whl
pip install + whl文件地址
pip install C:\Users\Zz\zh_core_web_sm-3.6.0-py3-none-any.whl
接下来就可以使用啦,给出两个小栗子
import spacy
# 加载英文模型
nlp = spacy.load("en_core_web_sm")
# 示例文本
text = "Apple is planning to build a new factory in China."
# 定义句式
pattern = [{"POS": "PROPN"}, {"LEMMA": "be"}, {"POS": "VERB"}]
# 处理文本
doc = nlp(text)
# 匹配句式
matcher = spacy.matcher.Matcher(nlp.vocab)
matcher.add("CustomPattern", None, pattern)
matches = matcher(doc)
# 提取匹配的数据并进行标注
for match_id, start, end in matches:
span = doc[start:end]
print("Matched:", span.text)
span.merge()
# 打印标注后的文本
print("Tagged Text:", doc.text)
import spacy
# 加载中文模型
nlp = spacy.load("zh_core_web_sm")
text = "写入历史了:苹果是美国第一家市值超过一万亿美元的上市公司。"
# 处理文本
doc = nlp(text)
for token in doc:
# 获取词符文本、词性标注及依存关系标签
token_text = token.text
token_pos = token.pos_
token_dep = token.dep_
# 规范化打印的格式
print(f"{token_text:token_pos:token_dep:
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们,邮箱:ciyunidc@ciyunshuju.com。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!



