
大数据开发-Hadoop之深入MapReduce
温馨提示:这篇文章已超过377天没有更新,请注意相关的内容是否还可用!
文章目录
- MapReduce任务日志查看
- 停止Hadoop集群中的任务
- MapReduce程序扩展
- Shuffle过程详解
- Hadoop中的序列化机制
MapReduce任务日志查看
- 需要开启YARN的日志聚合功能,把散落在NodeManager节点上的日志统一收集管理,方便日志查看
[root@hadoop01 hadoop]# vim yarn-site.xml yarn.log-aggregation-enable true yarn.log.server.url http://192.168.52.100:19888/jobhistory/logs/ # 配置文件同步 [root@hadoop01 hadoop]# scp -rq yarn-site.xml hadoop02:/home/soft/hadoop-3.2.0/etc/hadoop/ [root@hadoop01 hadoop]# scp -rq yarn-site.xml hadoop03:/home/soft/hadoop-3.2.0/etc/hadoop/ # 重启服务 [root@hadoop01 hadoop-3.2.0]# sbin/stop-all.sh Stopping namenodes on [hadoop01] Last login: Wed Mar 6 09:30:03 CST 2024 from 192.168.52.1 on pts/1 Stopping datanodes Stopping secondary namenodes [hadoop01] Last login: Thu Mar 7 09:13:43 CST 2024 on pts/1 Stopping nodemanagers Last login: Thu Mar 7 09:13:47 CST 2024 on pts/1 Stopping resourcemanager Last login: Thu Mar 7 09:13:51 CST 2024 on pts/1 You have new mail in /var/spool/mail/root [root@hadoop01 hadoop-3.2.0]# jps 33464 Jps [root@hadoop01 hadoop-3.2.0]# sbin/start-all.sh Starting namenodes on [hadoop01] Last login: Thu Mar 7 09:13:54 CST 2024 on pts/1 Starting datanodes Last login: Thu Mar 7 09:14:16 CST 2024 on pts/1 Starting secondary namenodes [hadoop01] Last login: Thu Mar 7 09:14:18 CST 2024 on pts/1 Starting resourcemanager Last login: Thu Mar 7 09:14:24 CST 2024 on pts/1 Starting nodemanagers Last login: Thu Mar 7 09:14:31 CST 2024 on pts/1 [root@hadoop01 hadoop-3.2.0]# jps 33666 NameNode 34179 ResourceManager 34501 Jps 33935 SecondaryNameNode # 启动historyserver守护进程 [root@hadoop01 hadoop-3.2.0]# bin/mapred --daemon start historyserver You have new mail in /var/spool/mail/root [root@hadoop01 hadoop-3.2.0]# jps 33666 NameNode 34626 Jps 34179 ResourceManager 34569 JobHistoryServer 33935 SecondaryNameNode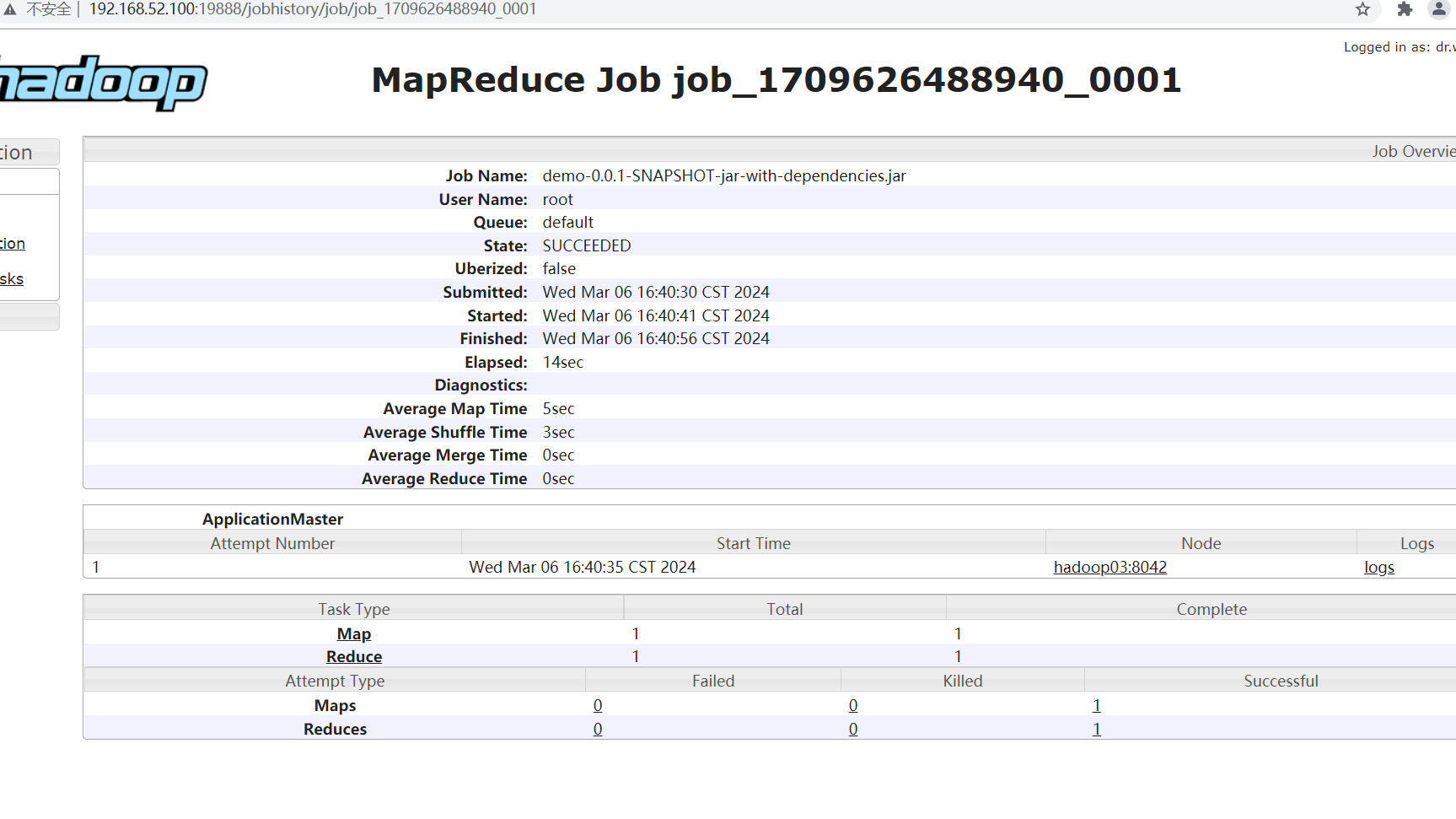
停止Hadoop集群中的任务
假设任务执行到一半了,发现代码有漏洞,那么错误的代码没有必要再去执行,所以要给它停掉。
[root@hadoop01 hadoop-3.2.0]# yarn application -kill application_1709774078248_0001

MapReduce程序扩展
当数据只需要进行过滤、解析,不需要聚合的时候不需要reduce阶段,此时在job设置的时候将job.setNumReduceTasks(0);就可以了
Shuffle过程详解
Shuffle就是一个将map数据传输到reduce的过程


Hadoop中的序列化机制

通过上图,影响MapReduce执行效率的主要原因是磁盘IO,如果想提高这个任务的执行效率,就需要对这方面进行优化。进行磁盘IO的时候都要对数据进行序列化和反序列化。
常见的实现
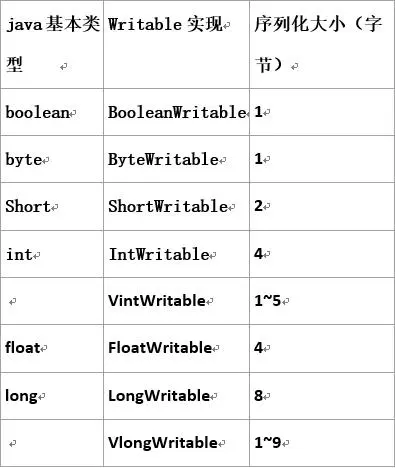
- Text等价于String的Writable,针对UTF-8序列
- NullWritable是单例,获取实例使用NullWritable.get()
Hadoop序列化机制的特点
- 紧凑:高效的存储控件
- 快速:读写数据的额外开销小
- 可扩展:可透明的读取老格式的数据
- 互操作:支持多语言的交互
Java序列化的不足之处
-
不精简,附加信息太多,不太适合随机访问
adoop序列化机制的特点
-
紧凑:高效的存储控件
-
快速:读写数据的额外开销小
-
可扩展:可透明的读取老格式的数据
-
互操作:支持多语言的交互
Java序列化的不足之处
- 不精简,附加信息太多,不太适合随机访问
- 存储空间大,递归地输出类的超类描述直到不再有超类
-
- 需要开启YARN的日志聚合功能,把散落在NodeManager节点上的日志统一收集管理,方便日志查看
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们,邮箱:ciyunidc@ciyunshuju.com。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!



