
【yolov5】将标注好的数据集进行划分(附完整可运行python代码)
温馨提示:这篇文章已超过375天没有更新,请注意相关的内容是否还可用!
问题描述
准备使用yolov5训练自己的模型,自己将下载的开源数据集按照自己的要求重新标注了一下,然后现在对其进行划分。
问题分析
划分数据集主要的步骤就是,首先要将数据集打乱顺序,然后按照一定的比例将其分为训练集,验证集和测试集。
这里我定的比例是7:1:2。
步骤流程
1、将数据集打乱顺序
数据集有图片和标注文件,我们需要把两种文件绑定然后将其打乱顺序。
首先读取数据后,将两种文件通过zip函数绑定
each_class_image = []
each_class_label = []
for image in os.listdir(file_path):
each_class_image.append(image)
for label in os.listdir(xml_path):
each_class_label.append(label)
data=list(zip(each_class_image,each_class_label))
然后打乱顺序,再将两个列表分开
random.shuffle(data)
each_class_image,each_class_label=zip(*data)
2、按照确定好的比例将两个列表元素分割
分别用三个列表储存一下图片和标注文件的元素
train_images = each_class_image[0:int(train_rate * total)]
val_images = each_class_image[int(train_rate * total):int((train_rate + val_rate) * total)]
test_images = each_class_image[int((train_rate + val_rate) * total):]
train_labels = each_class_label[0:int(train_rate * total)]
val_labels = each_class_label[int(train_rate * total):int((train_rate + val_rate) * total)]
test_labels = each_class_label[int((train_rate + val_rate) * total):]
3、在本地生成文件夹,将划分好的数据集分别保存
这样就保存好了。
for image in train_images:
#print(image)
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'train' + '/' + 'images'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
for label in train_labels:
#print(label)
old_path = xml_path + '/' + label
new_path1 = new_file_path + '/' + 'train' + '/' + 'labels'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + label
shutil.copy(old_path, new_path)
for image in val_images:
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'val' + '/' + 'images'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
for label in val_labels:
old_path = xml_path + '/' + label
new_path1 = new_file_path + '/' + 'val' + '/' + 'labels'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + label
shutil.copy(old_path, new_path)
for image in test_images:
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'test' + '/' + 'images'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
for label in test_labels:
old_path = xml_path + '/' + label
new_path1 = new_file_path + '/' + 'test' + '/' + 'labels'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + label
shutil.copy(old_path, new_path)
运行结果展示
直接运行单个python文件即可。
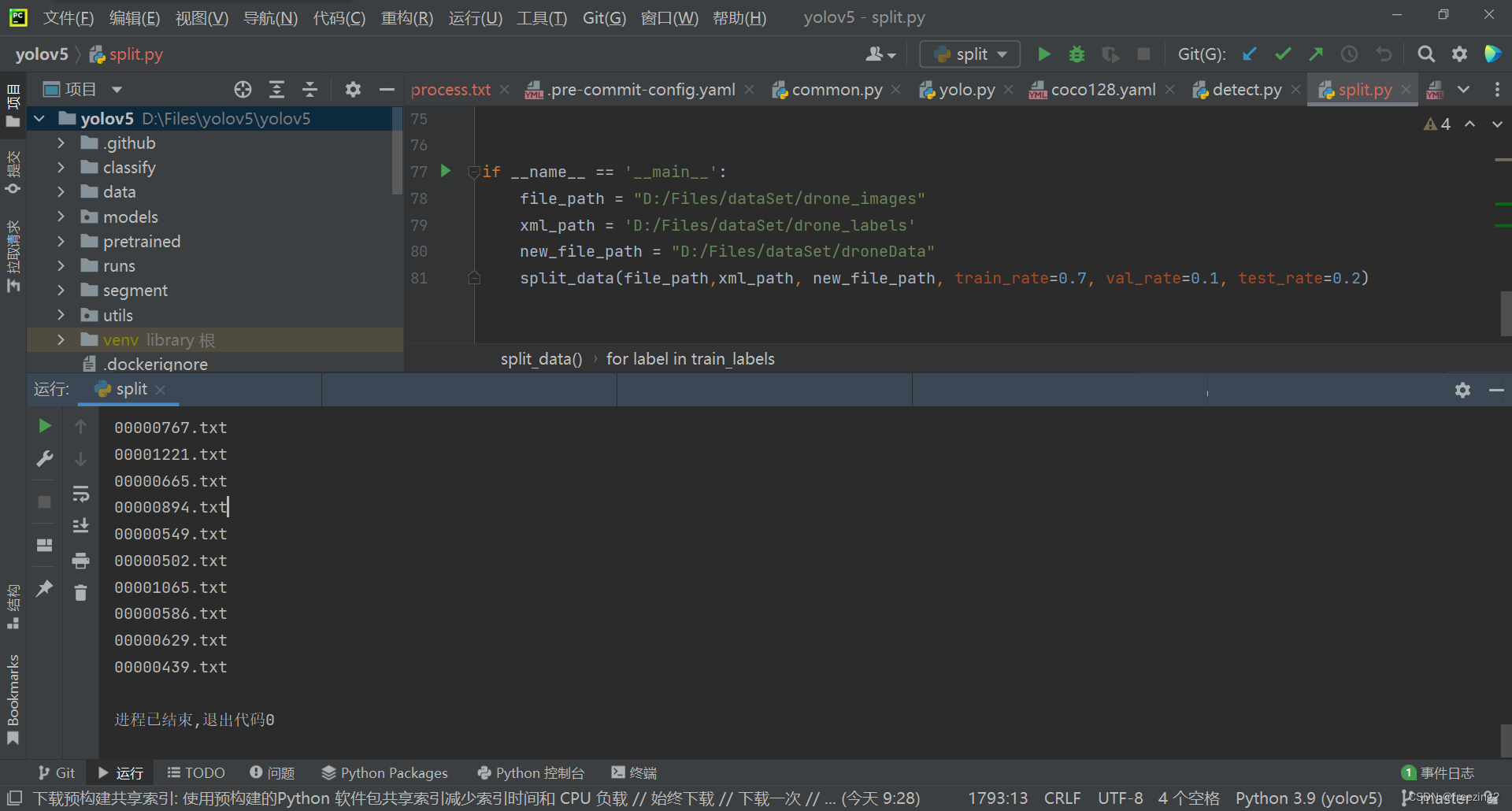
运行完毕
去本地查看
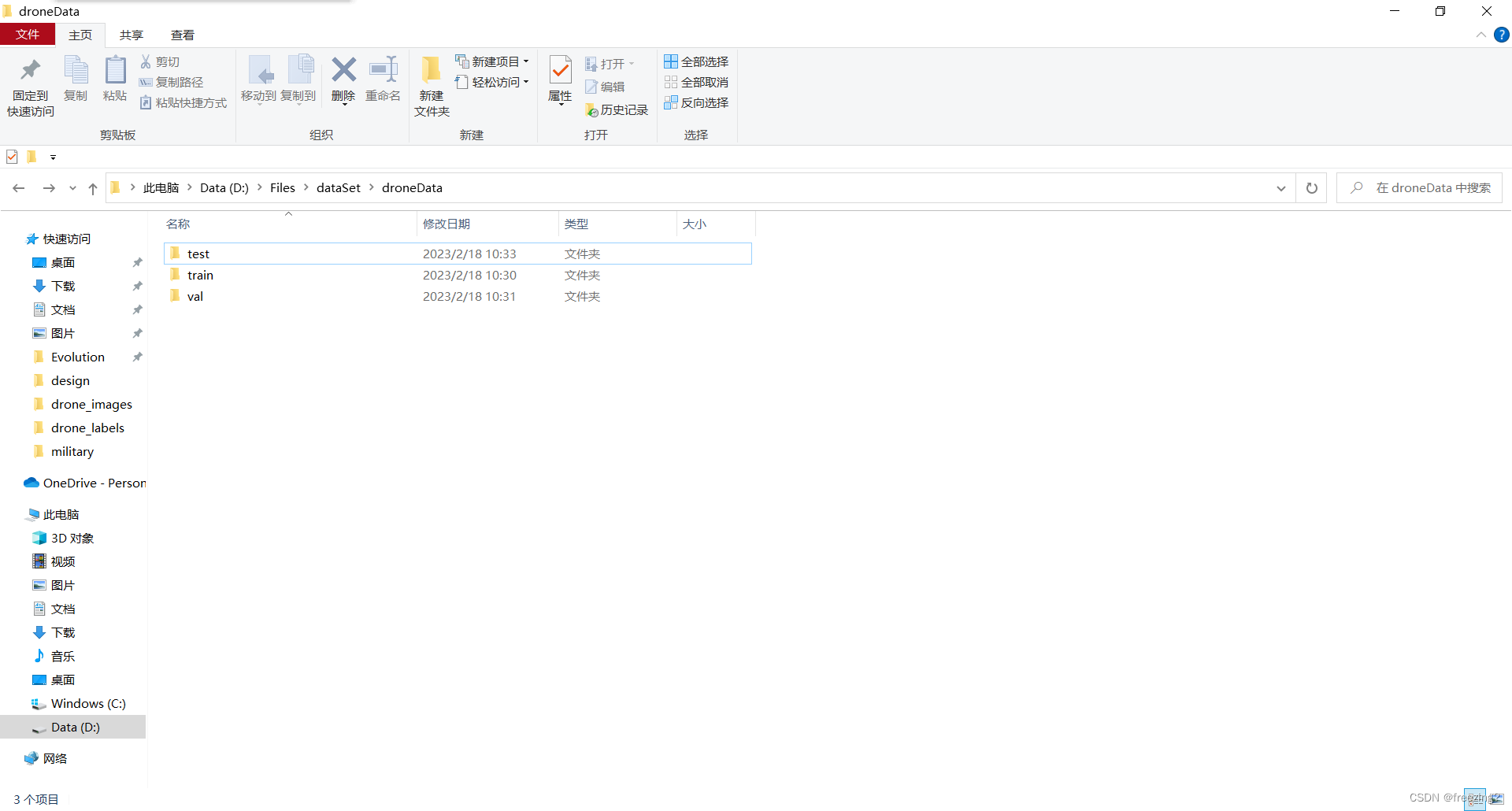

图片和标注文件乱序,且一一对应。
完整代码分享
import os
import shutil
import random
random.seed(0)
def split_data(file_path,xml_path, new_file_path, train_rate, val_rate, test_rate):
each_class_image = []
each_class_label = []
for image in os.listdir(file_path):
each_class_image.append(image)
for label in os.listdir(xml_path):
each_class_label.append(label)
data=list(zip(each_class_image,each_class_label))
total = len(each_class_image)
random.shuffle(data)
each_class_image,each_class_label=zip(*data)
train_images = each_class_image[0:int(train_rate * total)]
val_images = each_class_image[int(train_rate * total):int((train_rate + val_rate) * total)]
test_images = each_class_image[int((train_rate + val_rate) * total):]
train_labels = each_class_label[0:int(train_rate * total)]
val_labels = each_class_label[int(train_rate * total):int((train_rate + val_rate) * total)]
test_labels = each_class_label[int((train_rate + val_rate) * total):]
for image in train_images:
print(image)
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'train' + '/' + 'images'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
for label in train_labels:
print(label)
old_path = xml_path + '/' + label
new_path1 = new_file_path + '/' + 'train' + '/' + 'labels'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + label
shutil.copy(old_path, new_path)
for image in val_images:
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'val' + '/' + 'images'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
for label in val_labels:
old_path = xml_path + '/' + label
new_path1 = new_file_path + '/' + 'val' + '/' + 'labels'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + label
shutil.copy(old_path, new_path)
for image in test_images:
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'test' + '/' + 'images'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
for label in test_labels:
old_path = xml_path + '/' + label
new_path1 = new_file_path + '/' + 'test' + '/' + 'labels'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + label
shutil.copy(old_path, new_path)
if __name__ == '__main__':
file_path = "D:/Files/dataSet/drone_images"
xml_path = 'D:/Files/dataSet/drone_labels'
new_file_path = "D:/Files/dataSet/droneData"
split_data(file_path,xml_path, new_file_path, train_rate=0.7, val_rate=0.1, test_rate=0.2)
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们,邮箱:ciyunidc@ciyunshuju.com。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!



