
OpenCV与机器学习:OpenCV实现主成分分析
温馨提示:这篇文章已超过419天没有更新,请注意相关的内容是否还可用!
OpenCV实现主成分分析
- 前言
- 主成分分析(PCA)
- 数据生成
- 画图
- cv2.PCACompute
- 绘制主成分分析结果
前言
维数灾难是指出现一定数量的特征(或者维度)后,分类器的性能将开始下降。特征越多,数据集中的信息就越多。但是,如果考虑的特征超过了所需的特征,分类器甚至会考虑异常值或者会过拟合数据集。因此分类器的性能开始下降,而不是上升。
降维技术允许我们在不丢失太多信息的情况下,找到高维数据的一种紧凑表示。
主成分分析(PCA)
最常见的一种降维技术是主成分分析(Principal Component Analysis,PCA)。PCA所做的是旋转所有的数据点,直到数据点与解释大部分数据分布的两个轴对齐。
数据生成
np.random.multivariate_normal
首先我们使用numpy中的np.random.multivariate_normal来生成一个数据集用于降维。np.random.multivariate_normal是 NumPy 库中的一个函数,用于生成满足多元正态(也称为高斯)分布的随机样本。
多元正态分布是多个随机变量的概率分布,其中每个随机变量都服从正态分布,并且这些随机变量之间存在一定的相关性。
函数的基本用法如下:
numpy.random.multivariate_normal(mean, cov, size)
参数 含义 mean 一个表示分布的均值的1-D数组。 cov 一个表示分布的协方差矩阵的2-D数组。 size 输出的形状。如果是一个整数,则输出会有这么多样本;如果是一个元组,则输出会有相应的维度。 import numpy as np mean = [20, 20] cov = [[12, 8], [8, 18]] np.random.seed(42) x, y = np.random.multivariate_normal(mean, cov, 1000).T x.shape, y.shape
生成的数据形状如下:
((1000,), (1000,))
画图
将数据的两个维度用二维图画出来,这里使用的画图风格为ggplot(没有别的原因,就是因为这个好看)
import matplotlib.pyplot as plt plt.style.use('ggplot') plt.figure(figsize=(35, 35)) plt.plot(x, y, 'o', zorder=5) plt.axis([0, 35, 0, 35]) plt.xlabel('feature 1') plt.ylabel('feature 2')
cv2.PCACompute
首先我们将x,y合并起来作为主成分分析的数据。
X = np.vstack((x, y)).T X.shape
(1000, 2)
在OpenCV中,cv2.PCACompute() 函数用于计算主成分分析(PCA)的结果。PCA 是一种常用的统计方法,用于减少数据集的维度,同时保留数据中的主要变化特征。通过 PCA,你可以找到数据中的“主成分”,这些主成分定义了数据的主要变化方向。在代码中np.array([]) 是一个空的均值向量,当设置为空时PCACompute()将自动计算数据的均值。
import cv2 mu, eig = cv2.PCACompute(X, np.array([])) eig
array([[ 0.57128392, 0.82075251], [ 0.82075251, -0.57128392]])函数返回两个值:在投影之前减去均值(mean)和协方差矩阵的特征向量(eig)。这些特征向量指向PCA认为信息最丰富的方向。如果我们使用maplotlib在我们数据的顶部绘制这些特征向量,那么就会发现这些特征向量与数据的分布是一致的。
绘制主成分分析结果
使用plt.quiver可以绘制出特征向量,其中参数mean为数据的均值,在这里表示的时箭头的起点,eig则是特征向量,即箭头的方向。
plt.figure(figsize=(10, 6)) plt.plot(x, y, 'o', zorder=1) plt.quiver(mean, mean, eig[:, 0], eig[:, 1], zorder=3, scale=0.2, units='xy') plt.text(mean[0] + 5 * eig[0, 0], mean[1] + 5 * eig[0, 1], 'u1', zorder=5, fontsize=16, bbox=dict(facecolor='white', alpha=0.6)) plt.text(mean[0] + 5 * eig[1, 0], mean[1] + 8 * eig[1, 1], 'u2', zorder=5, fontsize=16, bbox=dict(facecolor='white', alpha=0.6)) plt.axis([0, 40, 0, 40]) plt.xlabel('feature 1') plt.ylabel('feature 2')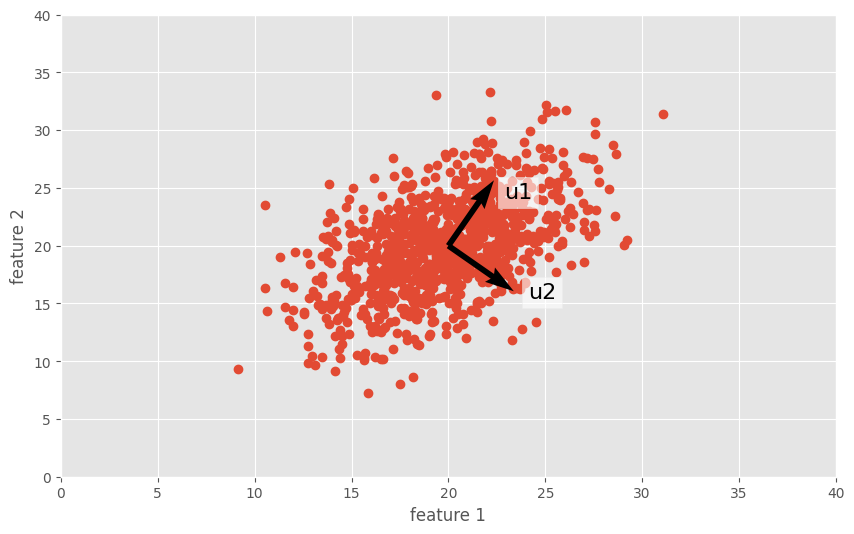
PCA告诉我们的是,我们预先确定的x轴和y轴对于描述我们选择的数据并不是那么有意义。因为所选数据的分布角度大约是45度,所以选择u1和u2作为坐标轴比选择x和y更有意义。
为了证明这一点,我们可以使用cv2.PCAProject旋转数据
X2 = cv2.PCAProject(X, mu, eig) plt.plot(X2[:, 0], X2[:, 1], 'o') plt.xlabel('first principal component') plt.ylabel('second principal component') plt.axis([-20, 20, -10, 10])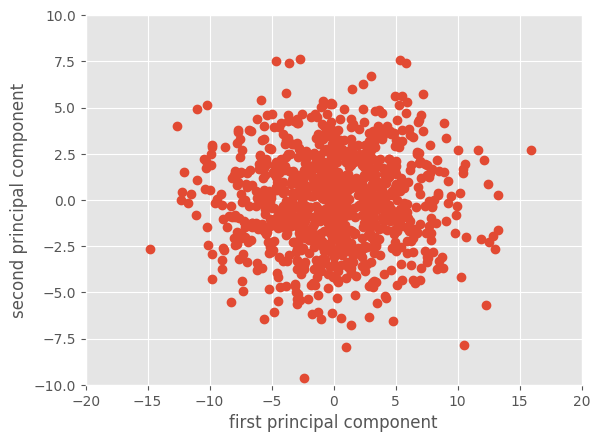
以上就是主成分分析用于调整数据分布的用法,除此之外我们还可以使用PCA进行降维操作,我们只需要选择相应的特征向量并与原数据相乘即可。
做法如下:
new_eig = eig[:, :选取的维度] X_new = X.dot(new_eig)



