
Kafka零拷贝技术与传统数据复制次数比较
温馨提示:这篇文章已超过390天没有更新,请注意相关的内容是否还可用!
读Kafka技术书遇到困惑:
"对比传统的数据复制和“零拷贝技术”这两种方案。假设有10个消费者,传统复制方式的数据复制次数是4×10=40次,而“零拷贝技术”只需1+10= 11次(一次表示从磁盘复制到页面缓存,另外10次表示10个消费者各自读取一次页面缓存)。显然,“零拷贝技术”比传统复制方式需要的复制次数更少。 "
困惑我的有两个问题:
1. 传统一次数据传输为什么需要4次拷贝
2. 为什么零拷贝下10个消费者只需要11次
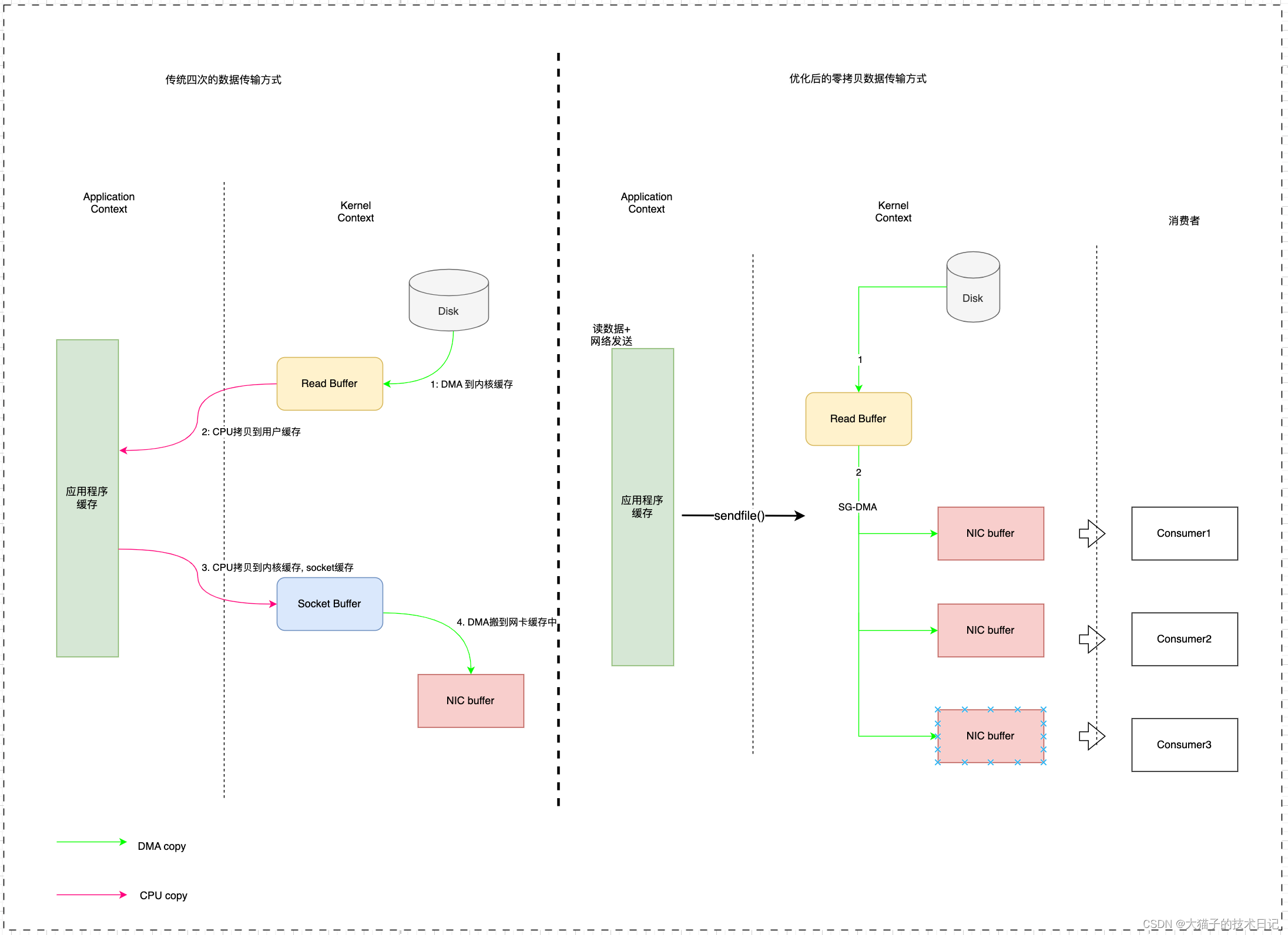
第一个问题:传统一次数据传输为什么需要4次拷贝?
传统数据传输在实现上包含两个操作, read 和write,都是由用户程序来发起, 其中read和write中各有两次复制操作. read负责将数据从磁盘加载到内存空间中, 由于用户程序没有直接读取磁盘或写入网卡等操作系统资源的的权限, 因此每次调用时, 上下文都需要从用户态切换到内核态.
在read中, 首先由系统交由DMA(direct memory access)做第一次复制, 将数据从磁盘搬运到内核空间的文件系统的页面缓存中; 然后再交由CPU执行数据的第二次复制, 将数据从页面缓存拷贝到用户内存空间中.
在write时, 首先cpu会将数据将用户空间拷贝到内核空间(文件系统缓冲区,pagecache), 放在socket缓存区中,完成第一次复制; 然后再由DMA将数据从socket缓存区搬运到网卡接口, 由网卡将数据传输到到网络中.
在此过程中发生了4次用户态与内核态的上下文切换(一次系统调用会发生两次上下文切换)、4次拷贝, 其中CPU复制两次、 DMA复制两次, 在其中很多复制步骤是非必要的, 如何进行优化?
常见优化手段有两种:
- mmap + write
- sendfile
mmap是个共享缓存方案, 即把内核空间缓存去中的数据映射到用户空间中, 可被用户程序直接使用, 进行共享, 就不用将数据从内核空间搬到用户空间了, 在write时还是需要由CPU将数据从共享区复制到socket缓存区中.
这种做法还是会有4次上下文切换, 但少了一次数据拷贝. 做了优化, 但不多.
再看另外一种sendfile, sendfile可以看成是对mmap + write操作的一种封装, 只需要指定下文件描述符和数据长度, 将两次系统调用减少为一次, 可以做到在内核态时将数据从磁盘复制到网卡, 但其中还是会经过三次数据复制:
- 磁盘->内核缓存
- 内核缓存-> socket缓存
- socket缓存->NIC缓冲区(Network Interface Card buffer), 网卡缓存区
这种不是实际意义上的零拷贝, 但不在发生从内核空间到用户空间的拷贝了, 所以我理解所谓零拷贝指的是不发生从内核空间到用户空间的拷贝了。
第二个问题: 为什么零拷贝下10个消费者只需要11次拷贝?
那第二个问题"为什么零拷贝下10个消费者只需要11次拷贝?"怎么理解?
这是使用了更牛逼的SG-DMA(The Scatter-Gather Direct Memory Access)技术, SG-DMA是一种特殊的DMA, 通过sendfile指定的文件描述符和数据长度, 实现了将内核中页缓存数据直接搬运到网卡中, 中间不需要经过socket缓存区, 且中间拷贝操作全程无cpu参与.
在这种情况下, sendfile的数据流转流程:
- SG-DMA将数据磁盘复制到内核态Buffer(具体来说是读缓存区, ReadBuffer)
- SG-DMA从内核态Buffer搬运到NIC buffer中.
整个读文件-网络发送由一个sendfile完成, 并且在此过程中无只有两次上下文切换, 且无CPU数据copy, 因此大大提升了性能
在这种意义下, 零拷贝指的是零cpu拷贝技术.
SG-DMA实现了仅需两次拷贝就完成了一次磁盘数据的网络传输操作, 而对于10个消费者则需要10次使用SG-DMA将数据从内核页缓存拷贝到网卡的动作, 页缓存顾名思义是数据在内核空间的缓存, 对于同一条数据从磁盘拷贝到内核空间后就缓存起来, 后面再使用时就可无需再重新拷贝了.
所以1条消息发送给10个消费者, kafka做到了仅需通过11次拷贝就完成了, 越少的数据复制, 就越能更快的读取的数据, 延迟越少, 消费者性能就越好, 你说他的文件传输效率高不高.
其他使用零拷贝技术的还有Nginx系统.
其他:
chatgpt的答案:
零拷贝技术与传统数据复制次数比较解释
传统数据复制
在传统的数据复制方法中,数据在从磁盘到达消费者之前会经历多次复制。这个过程通常包括以下步骤:
- 从磁盘读取数据到内核空间的文件系统缓冲区(页缓存)。
- 从文件系统缓冲区复制数据到用户空间的应用程序缓冲区。
- 从应用程序缓冲区复制数据回内核空间的socket缓冲区。
- 从socket缓冲区将数据发送到网络。
如果有10个消费者,这个过程需要为每个消费者重复进行,导致数据被复制了4次(磁盘到文件系统缓冲区,文件系统缓冲区到用户空间,用户空间到socket缓冲区,socket缓冲区到网络)。因此,总的数据复制次数是4×10=40次。
零拷贝技术
零拷贝技术通过减少数据在用户空间和内核空间之间的不必要复制,来降低CPU的负载和提高数据传输效率。在零拷贝的情况下,数据传输过程如下:
- 从磁盘读取数据到内核空间的文件系统缓冲区(页缓存),这是唯一的一次数据复制。
- 使用零拷贝技术(如Linux的sendfile系统调用),直接从文件系统缓冲区传输数据到网络,避免了数据到用户空间的复制。
每个消费者直接从文件系统缓冲区读取数据,所以对于10个消费者,数据复制次数为1(磁盘到文件系统缓冲区)加上10(每个消费者读取一次文件系统缓冲区),总共是1+10=11次。
但是数据传输是否一定会调用sendfile取决于具体系统, 具体来看: kafka的数据传输是调用了TransportLayer完成, 其具体实现中会通过Java NIO的FileChannel中的transferTo()和transferFrom()来实现零拷贝方法, 这两个方法在支持sendfile特性的系统上就能充分利用零拷贝的优势来提升性能.
结论
零拷贝技术显著减少了数据复制次数,从40次降低到了11次。这减少了CPU的工作负担,提高了数据传输的效率,并且减少了延迟。在处理大量数据或者高速网络传输时,零拷贝技术的优势尤为明显
参考:
- chatgpt
- 原来 8 张图,就可以搞懂「零拷贝」了
 https://www.cnblogs.com/xiaolincoding/p/13719610.html
https://www.cnblogs.com/xiaolincoding/p/13719610.html



