
【论文阅读笔记】Meta Relational Learning for Few-Shot Link Prediction in Knowledge Graphs - EMNLP 2019
温馨提示:这篇文章已超过399天没有更新,请注意相关的内容是否还可用!
知识图谱 --> 知识补全 --> 长尾问题 --> 元关系学习
- 基于度量的方法
- 基于优化的方法(本文)
文章目录
- Abstract
- 1 Introduction
- 2 Related Work
- 2.1 知识图谱嵌入
- 2.2 元学习(Meta-Learning)
- 3 Task Formulation
- 4 Method
- 4.1 关系元学习器
- 4.2 嵌入学习器
- 4.3 训练目标
- 5 Experiments
- 5.1 数据集和评估指标
- 5.2 实施
- 5.3 结果
- 5.4 消融研究
- 5.5 影响 MetaR 性能的因素
- 实体的稀疏性
- 任务数量
- 6 Conclusion
Abstract
链接预测是完成知识图谱(KG)的重要方法,而基于嵌入的方法对于知识图谱中的链接预测有效,但在只有少量关联三元组的关系上表现不佳。在这项工作中,我们提出了一个元关系学习(MetaR)框架来进行知识图谱中常见但具有挑战性的小样本链接预测,即通过仅观察几个关联三元组来预测关于关系的新三元组。我们通过专注于传输特定于关系的元信息来解决小样本链接预测,使模型学习最重要的知识并学得更快,即MetaR中对应关系的关系元和梯度元。根据实践,我们的模型在少样本链接预测 KG 基准上取得了最先进的结果。研究背景 + 研究目的 + 研究内容 +研究结果
1 Introduction
尽管拥有大量的实体、关系和三元组,但许多知识图谱仍然存在不完备性,因此知识图谱的完善对于知识图谱的发展至关重要。知识图谱补全任务之一是链接预测,即根据现有三元组预测新的三元组。对于链接预测,KG 嵌入方法是有效的方法。他们学习连续向量空间中实体和关系的潜在表示(称为嵌入),并通过嵌入计算完成链接预测。
KG 嵌入方法的有效性是通过足够的训练样本来保证的,因此对于训练过程中实例较少的元素,结果要差得多。然而,KG 中普遍存在少样本问题。例如,维基数据中大约 10% 的关系的三元组不超过 10 个。与少数实例的关系称为少样本关系。在本文中,我们致力于讨论知识图中的少样本链接预测,通过仅观察关于r的K个三元组来预测给定头实体h和关系r的尾实体t,通常K很小。图 1 描述了 KG 中 3 次链接预测的示例。研究问题1:知识图谱中存在少样本问题
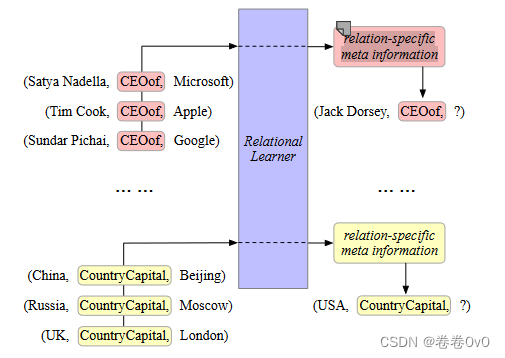
为了进行少样本链接预测,(Xiong 等, 2018) 进行了第一次试验并提出了 GMatching,通过考虑学习的嵌入和单跳图结构来学习匹配度量,但是我们尝试从另一个角度来完成few-shot链接预测,即从几个现有实例转移到不完整三元组的最重要信息应该是一项任务中的共享的知识。我们将此类信息称为特定于关系的元信息,并提出了一种新的框架元关系学习(MetaR),用于few-shot链接预测。例如,在图 1 中,MetaR 将提取与关系 CEOof 或 CountryCapital 相关的特定于关系的元信息,并将其从一些现有实例传输到不完整的三元组。
特定于关系的元信息在以下两个方面很有帮助:
- 将常见关系信息从观察到的三元组转移到不完整的三元组;
- 通过仅观察少数实例来加速一项任务中的学习过程。
因此,我们提出了两种特定于关系的元信息:关系元和梯度元,分别对应于上述两个视角。在我们提出的框架 MetaR 中,创新点
- 关系元是连接头实体和尾实体的关系的高阶表示;
- 梯度元是关系元的损失梯度,用于在预测期间将关系元转移到不完整三元组之前进行快速更新。
与依赖于背景知识图的 GMatching (Xiong 等, 2018) 相比,我们的 MetaR 与它们无关,因此更加稳健,因为背景知识图可能无法用于实际场景中的少样本链接预测。研究问题2:背景知识图无法应用于实际场景的few-shot任务
我们在少样本链接预测数据集上使用不同的设置来评估 MetaR。 MetaR 取得了最先进的结果,表明在few-shot链接预测任务中成功传输特定于关系的元信息。总之,我们工作的主要贡献有三方面:
-
首先,我们提出了一种新颖的元关系学习框架(MetaR)来解决知识图中的少样本链接预测问题。
-
其次,我们强调了关系特定元信息对于少样本链接预测的关键作用,并提出了两种关系特定元信息:关系元和梯度元。实验表明,两者都有显着的贡献。
-
第三,我们的 MetaR 在少量链接预测任务上取得了最先进的结果,并且我们还分析了影响 MetaR 性能的因素。
2 Related Work
受知识图嵌入方法的启发,MetaR 的目标之一是学习适合few-shot链接预测任务的实体表示。此外,使用损失梯度作为一种元信息受到 MetaNet (Munkhdalai 和 Yu, 2017)和 MAML (Finn 等, 2017) 的启发,它们探索了通过元学习进行小样本学习的方法。从这两点出发,我们将知识图谱嵌入和元学习视为两种主要的相关工作。
2.1 知识图谱嵌入
知识图嵌入模型将关系和实体映射到连续向量空间中。他们使用评分函数来衡量每个三元组 (h, r, t) 的真值。与知识图嵌入相同,我们的 MetaR 也需要一个评分函数,主要区别在于 r 的表示是 MetaR 中学习到的关系元,而不是像普通知识图嵌入方法那样对 r 进行嵌入。MetaR的评分函数用于衡量每个三元组的真值,GMatching的评分函数用于衡量候选尾实体。
TransE (Bordes 等, 2013) 开始了一系列工作,其中包括距离评分函数。 TransH (Wang 等, 2014) 和 TransR (Lin 等, 2015) 是两种典型的模型,使用不同的方法连头实体、尾实体及其关系。 DistMult 和 ComplEx 源自 RESCAL ,试图以不同的方式挖掘潜在语义。还有其他一些,例如 ConvE 使用卷积结构对三元组进行评分,以及使用实体类型和关系路径等附加信息的模型。(Wang 等, 2017)全面总结了当前流行的知识图谱嵌入方法。
传统的嵌入模型严重依赖于丰富的训练实例,因此受限于少样本链接预测任务。我们的 MetaR 旨在填补现有嵌入模型的这一漏洞。
2.2 元学习(Meta-Learning)
元学习寻求的是从同一概念内的少数实例快速学习并不断适应更多概念的能力,这实际上是人类非常擅长的快速增量学习。
最近提出了几种元学习模型。目前,元学习方法一般分为三种:
-
基于度量的元学习,它试图学习查询和支持集之间泛化到所有任务的匹配度量,其中匹配的思想类似于一些最近邻算法。
-
连体神经网络(Koch et al., 2015)是一种使用对称孪生网络来计算两个输入的度量的典型方法。
-
GMatching (Xiong 等, 2018) 是知识图谱中一次性链接预测的第一个尝试,它学习基于实体嵌入和局部图结构的匹配度量,这也可以被视为一种基于度量的方法。
-
基于模型的方法,该方法使用专门设计的部件(如存储器)仅通过少量训练实例即可实现快速学习的能力。
MetaNet (Munkhdalai 和 Yu, 2017) 是一种记忆增强神经网络(MANN),从损失梯度中获取元信息,并通过其快速参数化快速泛化。
-
基于优化的方法,该方法通过改变优化算法获得更快学习的思想。
与模型无关的元学习 (Finn 等, 2017) 缩写为 MAML,是一种与模型无关的算法。它首先更新特定任务学习器的参数,并使用上述更新的参数对参数进行跨任务的元优化,就像“通过梯度的梯度”。
-
据我们所知,(Xiong 等, 2018) 是第一个关于知识图的小样本学习的研究。它是一个基于度量的模型,由邻居编码器和匹配处理器组成。邻居编码器通过一跳邻居增强实体的嵌入,匹配处理器通过 LSTM 块执行多步匹配。
3 Task Formulation
在本节中,我们提出知识图和少样本链接预测任务的正式定义。知识图谱定义如下:
- 定义3.1(知识图
G
\mathcal G
G)知识图
G
=
{
E
,
R
,
T
P
}
\mathcal G = \{\mathcal E, \mathcal R, \mathcal T \mathcal P\}
G={E,R,TP}。
E
\mathcal E
E是实体集。
R
\mathcal R
R是关系集。且
T
P
=
{
(
h
,
r
,
t
)
∈
E
×
R
×
E
}
\mathcal T \mathcal P = \{(h, r, t) ∈ \mathcal E × \mathcal R × \mathcal E\}
TP={(h,r,t)∈E×R×E} 是三元组。
知识图中的few-shot链接预测任务定义为:
- 定义 3.2 (少样本链接预测任务
T
\mathcal T
T ) 具有知识图
G
=
{
E
,
R
,
T
P
}
\mathcal G = \{\mathcal E, \mathcal R, \mathcal T \mathcal P\}
G={E,R,TP},给定支持集
S
r
=
(
h
i
,
t
i
)
∈
E
×
E
∣
(
h
i
,
r
,
t
i
)
∈
T
P
S_r = {(h_i, t_i) ∈\mathcal E ×\mathcal E|(h_i, r, t_i) ∈\mathcal T\mathcal P}
Sr=(hi,ti)∈E×E∣(hi,r,ti)∈TP 关于关系
r
∈
R
r ∈ \mathcal R
r∈R,其中
∣
S
r
∣
=
K
|S_r| = K
∣Sr∣=K,预测由关系
r
r
r 链接到头实体
h
j
hj
hj的尾部实体,公式为
r
:
(
h
j
,
?
)
r : (h_j, ?)
r:(hj,?),称为
K
−
s
h
o
t
K-shot
K−shot 链接预测。支持集
如上所述,小样本链接预测任务始终是针对特定关系定义的。在预测过程中,通常需要预测多个三元组,在支持集 S r S_r Sr 的情况下,我们将所有待预测三元组的集合称为查询集 Q r = r : ( h j , ? ) \mathcal Q_r = {r : (h_j, ?)} Qr=r:(hj,?)。查询集
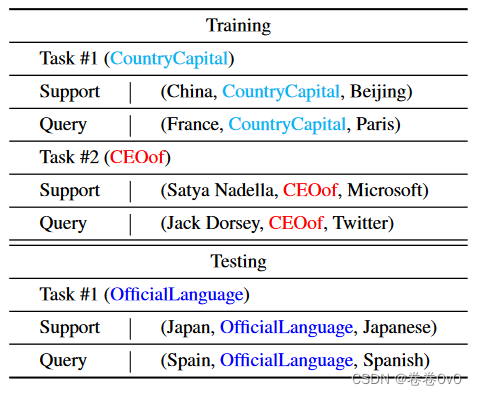
几次链接预测方法的目标是获得仅观察有关 r r r 的几个三元组即可预测有关关系 r r r 的新三元组的能力。因此,它的训练过程基于一组任务 T t r a i n = { T i } i = 1 M \mathcal T_{train} = \{\mathcal T_i\}^M_{i=1} Ttrain={Ti}i=1M,其中每个任务 T i = { S i , Q i } \mathcal T_i = \{\mathcal S_i, \mathcal Q_i\} Ti={Si,Qi} 对应于具有自己的支持和查询集的单个少样本链接预测任务。它的测试过程是在一组新任务 T t e s t = { T j } j = 1 N \mathcal T_{test} = \{\mathcal T_j\}_{j=1}^N Ttest={Tj}j=1N 上进行的,与 T t r a i n \mathcal T_{train} Ttrain 类似,不同之处在于 T j ∈ T t e s t \mathcal T_j ∈ \mathcal T_{test} Tj∈Ttest 应该是 T t r a i n \mathcal T_{train} Ttrain 中从未见过的关系。训练集 + 测试集
表1给出了小样本链接预测的学习和测试期间的数据的具体示例。
4 Method
要使一个模型获得少样本链接预测能力,最重要的是将信息从支持集转移到查询集,并且有两个问题需要我们思考:(1)支持集和查询集之间最可传递和最常见的信息是什么;(2)如何通过仅观察一项任务中的几个实例来更快地学习。对于问题(1),在一项任务中,支持集和查询集中的所有三元组都具有相同的关系,因此很自然地假设关系是支持集和查询集之间的关键公共部分。对于问题(2),学习过程通常是通过梯度下降最小化损失函数来进行的,因此梯度揭示了模型的参数应该如何改变。直观上,我们相信梯度是加速学习过程的宝贵来源。
基于这些想法,我们提出了两种在支持集和查询集之间共享的元信息来处理上述问题:
-
关系元: 表示连接支持集和查询集中头实体和尾实体的关系,我们从支持集中提取每个任务的关系元(表示为向量)并将其传输到查询集。
-
梯度元: 是支持集中关系元的损失梯度。由于梯度元显示了关系元应该如何改变以达到损失最小值,从而加速学习过程,关系元在转移到查询集之前通过梯度元进行更新。这次更新可以看作是关系元的快速学习。
为了提取关系元和梯度元并将它们与知识图嵌入相结合以解决few-shot链接预测,我们的提案MetaR主要包含两个模块:
-
Relation-Meta Learner(元关系学习器): 从支持集中的头和尾嵌入生成关系元。
-
Embedding Learner(嵌入学习器): 通过实体嵌入和关系元计算支持集和查询集中三元组的真值。基于嵌入学习器中的损失函数,计算梯度元,并在将关系元传输到查询集之前实现关系元的快速更新。
MetaR 的概述和算法如图 2 和算法 1 所示。
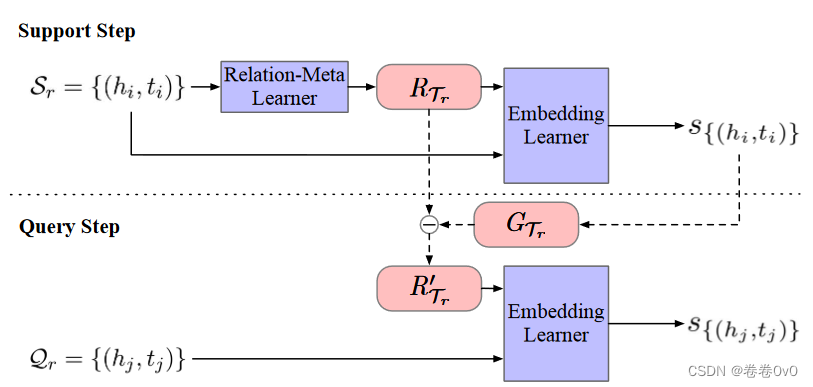

接下来,我们通过一个few-shot链接预测任务 T r = { S r , Q r } \mathcal T_r = \{\mathcal S_r, \mathcal Q_r\} Tr={Sr,Qr} 来介绍 MetaR 的各个模块。
4.1 关系元学习器
为了从支持集中提取关系元,我们设计了一个关系元学习器来学习从支持集中的头和尾实体到关系元的映射。该关系元学习器的结构可以实现为简单的神经网络。
在任务 T r \mathcal T_r Tr中,关系元学习器的输入是支持集中的头尾实体对 { ( h i , t i ) ∈ S r } \{(h_i, t_i) ∈ \mathcal S_r\} {(hi,ti)∈Sr}。我们首先通过 L 层全连接神经网络提取实体对特定关系元,
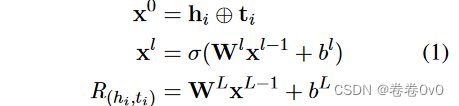
其中 h i ∈ R d h_i ∈ \mathbb R^d hi∈Rd 和 t i ∈ R d t_i ∈ \mathbb R^d ti∈Rd分别是头实体 h i h_i hi 和尾实体 t i t_i ti 的维度为 d d d 的嵌入。 L L L 是神经网络的层数, l ∈ { 1 , … , L − 1 } l ∈ \{1, …,L−1\} l∈{1,…,L−1}。 W l \bold W^l Wl 和 b l \bold b^l bl 是第 l l l 层的权重和偏差。我们使用 LeakyReLU来激活 σ。 x ⊕ y \bold x⊕\bold y x⊕y 表示向量 x \bold x x 和 y \bold y y 的串联。最后, R ( h i , t i ) R_{(h_i,t_i)} R(hi,ti)表示来自特定实体对 h i h_i hi 和 t i t_i ti 的关系元。
通过多个实体对特定关系元,我们通过对当前任务中所有实体对特定关系元进行平均来生成当前任务中的最终关系元,
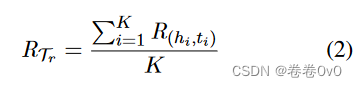
4.2 嵌入学习器
由于我们希望获得梯度元来对关系元进行快速更新,因此我们需要一个评分函数来评估特定关系下实体对的真值,以及当前任务的损失函数。
在任务 T r \mathcal T_r Tr 中,我们首先计算支持集 S r \mathcal S_r Sr 中每个实体对 ( h i , t i ) (h_i, t_i) (hi,ti) 的分数,如下所示:
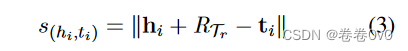
其中 ∥ x ∥ \Vert x\Vert ∥x∥ 表示向量 x \bold x x 的 L2 范数。我们设计的评分函数受到 TransE (Bordes 等, 2013) 的启发,它假设头实体嵌入 h h h、关系嵌入 r r r 和尾实体嵌入 t t t 为满足 h + r = t h+r = t h+r=t 的真三元组 ( h , r , t ) (h, r, t) (h,r,t)。因此,得分函数是根据 h + r h + r h+r 和 t t t 之间的距离来定义的。转移到我们的few-shot链接预测任务,我们用关系元 R T r R_{\mathcal T_r} RTr 替换关系嵌入 r r r,因为我们的任务中没有直接的一般关系嵌入, R T r R_{\mathcal T_r} RTr 可以被视为当前任务 T r \mathcal T_r Tr 的关系嵌入。
对于每个三元组的得分函数,我们设置以下损失,

其中 [ x ] + [x]_+ [x]+ 表示 x x x 的正部分, γ γ γ 表示 margin,它是一个超参数。 s ( h i , t i ′ ) s_{(h_i,t^′_i)} s(hi,ti′)是当前正实体对 ( h i , t i ) ∈ S r (h_i, t_i) \in \mathcal S_r (hi,ti)∈Sr 对应的负样本 ( h i , t i ′ ) (h_i, t^′_i) (hi,ti′) 的得分,其中 ( h i , r , t i ′ ) ∉ G (h_i, r, t^′_i) \notin \mathcal G (hi,r,ti′)∈/G。
对于任务 T r \mathcal T_r Tr 来说, L ( S r ) L(\mathcal S_r) L(Sr) 应该很小,这表示模型可以正确编码三元组的真值。因此参数的梯度表明参数应该如何更新。因此我们将基于 L ( S r ) L(\mathcal S_r) L(Sr) 的 R T r R_{\mathcal T_r} RTr 梯度视为梯度元 G T r G_{\mathcal T_r} GTr :
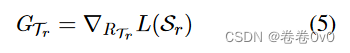
遵循梯度更新规则,我们对关系元进行快速更新,如下所示,其中β表示对关系元进行操作时梯度元的步长:
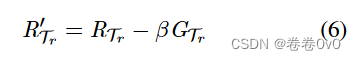
当通过嵌入学习器对查询集进行评分时,我们使用更新的关系元。获得更新后的关系元 R ′ R^′ R′ 后,我们将其转移到查询集 Q r = { ( h j , t j ) } \mathcal Q_r = \{(h_j , t_j)\} Qr={(hj,tj)} 中的样本,并计算它们的分数和查询集的损失,在支持集中遵循相同的方式:损失函数
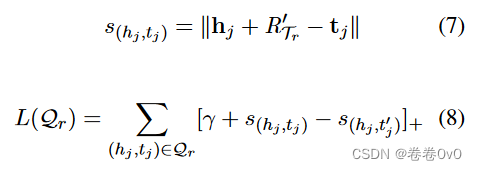
其中 L ( Q r ) L(\mathcal Q_r) L(Qr) 是我们要最小化的训练目标。我们使用这个损失来更新整个模型。
4.3 训练目标
在训练过程中,我们的目标是最小化以下损失 L,它是一个小批量中所有任务的查询损失之和:
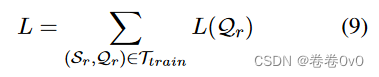
5 Experiments
使用 MetaR,我们想弄清楚以下问题:
- MetaR 能否完成少样本链接预测任务,甚至比以前的模型表现更好?
- 有多少关系特定的元信息有助于few-shot链接预测?
- MetaR 进行少样本链接预测有什么要求吗?
为此,作者在两个少样本链接预测数据集上进行了实验,并深入分析了实验结果。
5.1 数据集和评估指标
我们使用两个数据集,NELL-One 和 Wiki-One,它们是由 (Xiong 等, 2018) 构建的。此外,由于这两个基准首先在考虑学习嵌入和一跳图结构的 GMatching 上进行测试,因此使用训练/验证/测试集之外的关系构建背景图,以获得预训练实体嵌入并提供本地GMatching 的图表。
与使用背景图来增强实体表示的 Gmatching 不同,我们的 MetaR 可以在没有背景图的情况下进行训练。对于原本就有背景图的 NELL-One 和 Wiki-One,我们可以通过将其拟合到训练任务中或使用它来训练嵌入来初始化实体表示来利用这种背景图。总的来说,我们有三种数据集设置,如表3所示。对于BG:In-Train的设置,为了使背景图包含在训练任务中,我们从背景图和原始训练集中的三元组中采样任务,而不是仅从原始训练集中采样。
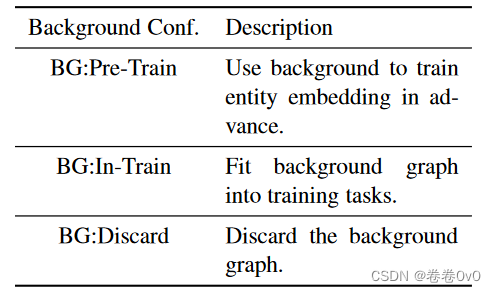
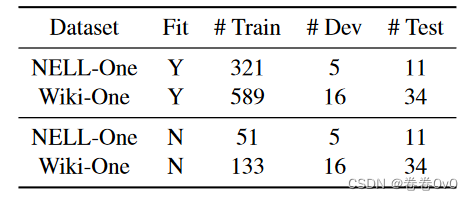
请注意,这三个设置并不违反知识图谱中few-shot链接预测的任务制定。 NELL-One和Wiki-One的统计数据如表2所示。
我们使用两种传统指标来评估这些数据集上的不同方法:
- MRR :平均倒数排名;
- Hits@N :链接预测中排名前 N 的正确实体的比例。
5.2 实施
在训练过程中,应用小批量梯度下降,NELL-One 和 Wiki-One 的批量大小分别设置为 64 和 128。我们使用 Adam (Kingma 和 Ba, 2015),初始学习率为 0.001 来更新参数。我们设置 γ = 1 和 β = 1。在 NELL-One 和 Wiki-One 中,查询集中的正三元组和负三元组的数量分别为 3 和 10。训练好的模型将每 1000 个 epoch 应用于验证任务,并记录当前的模型参数和相应的性能,停止后,在 Hits@10 上性能最好的模型将被视为最终模型。对于训练时期的数量,当 Hits@10 上的性能连续下降 30 次时我们停止训练。 和GMatching一致,NELL-One的嵌入维数为100,Wiki-One的嵌入维数为50。关系元学习器中两个隐藏层的大小分别为500、200和250,NELL-One和Wiki-One的嵌入维数为100。
5.3 结果
NELL-One 和 Wiki-One 上的两个少样本链接预测任务(包括 1-shot 和 5-shot)的结果如表 4 所示。我们实验中的基线是 GMatching (Xiong 等, 2018) ,它首次尝试了few-shot链接预测任务,并且是我们可以找到作为基线的唯一方法。在这个表中,不同KG嵌入初始化的GMatching的结果是从原始论文中复制的。我们的 MetaR 在表 3 中介绍的数据集的不同设置上进行了测试。
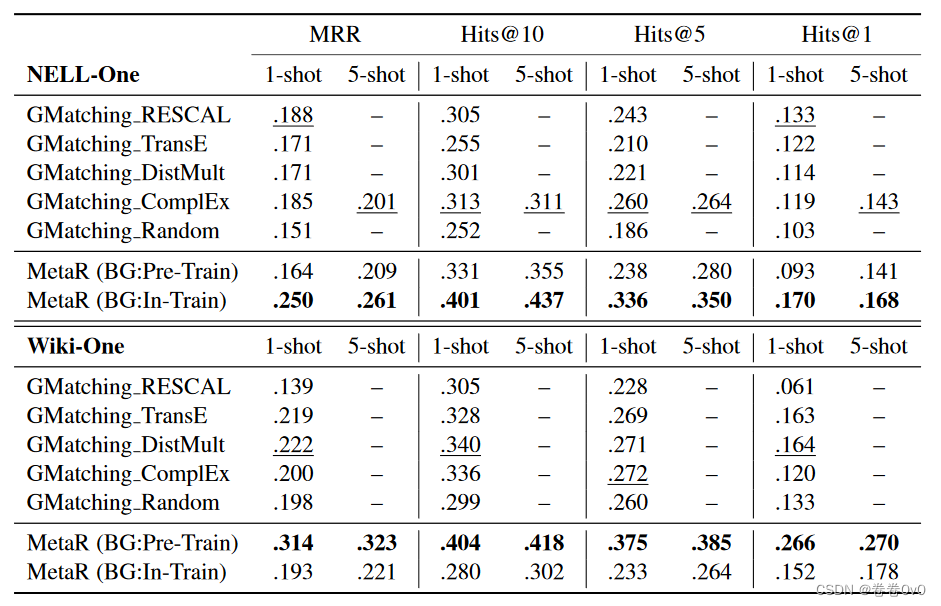
在表 4 中,我们的模型在两个数据集上的所有评估指标上都表现更好。具体来说,对于 1-shot 链接预测,MetaR 在 MRR、Hits@10、Hits@5 和 Hits@1 上在 NELL-One 上提高了 33%、28.1%、29.2% 和 27.8%,在 NELL-One 上提高了 41.4%、18.8%、37.9 % 和 62.2%,平均提升分别为 29.53% 和 40.08%。对于 5 次射击,MetaR 在 NELL-One 上的 MRR、Hits@10、Hits@5 和 Hits@1 上分别提高了 29.9%、40.5%、32.6% 和 17.5%,平均提高了 30.13%。
因此,对于我们要探讨的第一个问题,MetaR的结果并不比GMatching差,这表明MetaR具有完成few-shot链接预测的能力。与此同时,与 GMatching 相比令人印象深刻的改进表明,MetaR 的关键思想,即将特定于关系的元信息从支持集传输到查询集,在少样本链接预测任务上效果很好。
此外,与 GMatching 相比,我们的 MetaR 与背景知识图无关。我们在部分 NELL-One 和 Wiki-One 中测试 MetaR 的 1-shot 链接预测,丢弃背景图,在 Hits@10 上分别得到 0.279 和 0.348 的结果。这样的结果仍然可以与具有背景的完整数据集中的 GMatching 相媲美。
5.4 消融研究
我们已经在上一节中证明了关系特定的元信息(MetaR 的关键点)成功地有助于few-shot链接预测。由于本文中有两种特定于关系的元信息,即关系元和梯度元,我们想要弄清楚这两种元信息如何对性能做出贡献。因此,我们进行了三种设置的消融研究。
- 第一个是我们完整的 MetaR 方法,表示为标准。
- 第二个是通过将未更新的关系元直接从支持集转移到查询集来删除梯度元,而不通过梯度元更新它,表示为-g。
- 第三个是进一步删除关系元,这使得模型变基为简单的 TransE 嵌入模型,表示为 -g -r。
第三种设置下的结果复制自(Xiong 等, 2018) 。它使用来自背景图、训练任务的三元组和来自验证/测试集的一次性训练三元组,因此它既不是 BG:Pre-Train 也不是 BG:In-Train。我们对 NELL-one 进行了度量 Hit@10 的消融研究,结果如表 5 所示。
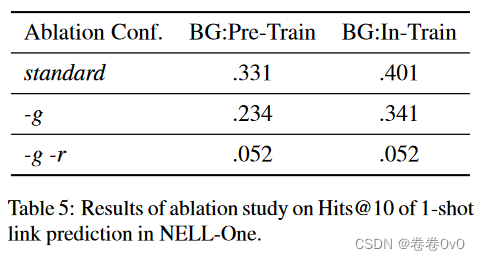
表 5 显示,与标准结果相比,删除梯度元在两个数据集设置上分别降低了 29.3% 和 15%,进一步删除关系元连续使性能降低了 55% 和 72%。因此,关系元和梯度元都贡献显着,并且关系元的贡献大于梯度元。如果没有梯度元和关系元,模型中就没有传输特定于关系的元信息,它几乎不起作用。这也说明了关系特定元信息对于few-shot链接预测任务是重要且有效的。
5.5 影响 MetaR 性能的因素
实体的稀疏性
我们注意到 NELL-One 和 Wiki-One 的最佳结果出现在不同的数据集设置中。使用 NELL-One,MetaR 在 BG:In-Train 数据集设置上表现更好,而使用 Wiki-One,它在 BG:Pre-Train 上表现更好。在 WikiOne 上,两个数据集设置之间的性能差异更为显着。
大多数few-shot任务的数据集都是稀疏的,与NELL-One和Wiki-One相同,但这两个数据集中的实体稀疏度仍然存在显着差异,这尤其体现在仅出现在一个三元组中的实体比例上训练集,WikiOne 和 NELL-One 中分别为 82.8% 和 37.1%。实体在训练期间只有一个三元组,这使得 MetaR 无法为它们学习良好的表示,因为实体嵌入严重依赖于 MetaR 中与它们相关的三元组。仅基于一个三元组,学习到的实体嵌入将包含很多偏差。对于那些一次性实体,知识图嵌入方法可以比 MetaR 学习更好的嵌入,因为实体嵌入可以通过连接到它的关系的嵌入来纠正,而在 MetaR 中则不能。这就是为什么最佳性能出现在 Wiki-One 上的 BG:Pre-train 设置中,预训练实体嵌入有助于 MetaR 克服一次性实体的低质量问题。
任务数量
通过 NELL-One 上有后台数据集设置和无后台数据集设置的 MetaR 性能对比,我们发现任务数量会对 MetaR 的性能产生显着影响。使用 BG:In-Train,训练期间有 321 个任务,MetaR 在 Hits@10 上达到 0.401,而没有背景知识时,有 51 个任务,少了 270 个,MetaR 达到 0.279。这使得 MetaR 在 BG:In-Train 与 NELL-One 上取得最佳性能的原因变得合理。即使 NELLOne 也有 37.1% 的一次性实体,在数据集中添加背景知识显着增加了训练任务的数量,这补充了稀疏性问题,并对任务做出了更多贡献。
因此我们得出结论,实体的稀疏性和任务的数量都会影响 MetaR 的性能。一般来说,随着训练任务的增多,MetaR 的表现会更好,对于极其稀疏的数据集,预训练实体嵌入是首选。
6 Conclusion
我们提出了一个元关系学习框架来在知识图谱中进行少样本链接预测,并且我们设计了我们的模型以将特定于关系的元信息从支持集传输到查询集。具体来说,使用关系元来传递常见和重要的信息,并使用梯度元来加速学习。与该任务中唯一的方法 GMatching 相比,我们的方法 MetaR 获得了更好的性能,并且与背景知识图无关。根据实验结果,我们分析了MetaR的性能会受到训练任务数量和实体稀疏度的影响。未来我们可能会考虑在 KG 的少样本链接预测中获得有关稀疏实体的更多有价值的信息。
-
-
- 定义 3.2 (少样本链接预测任务
T
\mathcal T
T ) 具有知识图
G
=
{
E
,
R
,
T
P
}
\mathcal G = \{\mathcal E, \mathcal R, \mathcal T \mathcal P\}
G={E,R,TP},给定支持集
S
r
=
(
h
i
,
t
i
)
∈
E
×
E
∣
(
h
i
,
r
,
t
i
)
∈
T
P
S_r = {(h_i, t_i) ∈\mathcal E ×\mathcal E|(h_i, r, t_i) ∈\mathcal T\mathcal P}
Sr=(hi,ti)∈E×E∣(hi,r,ti)∈TP 关于关系
r
∈
R
r ∈ \mathcal R
r∈R,其中
∣
S
r
∣
=
K
|S_r| = K
∣Sr∣=K,预测由关系
r
r
r 链接到头实体
h
j
hj
hj的尾部实体,公式为
r
:
(
h
j
,
?
)
r : (h_j, ?)
r:(hj,?),称为
K
−
s
h
o
t
K-shot
K−shot 链接预测。支持集
-
-



