
【数据结构】一文带你全面了解排序(上)——直接插入排序、希尔排序、选择排序、堆排序
温馨提示:这篇文章已超过461天没有更新,请注意相关的内容是否还可用!
目录
一、排序的概念及其运用
1.1 排序的概念
1.2 常见的算法排序
二、常见排序算法的实现
2.1 插入排序
2.1.1 思想
2.1.2 直接插入排序
2.1.3 希尔排序(缩小增量排序)
2.2 选择排序
2.2.1 基本思想
2.2.2 直接选择排序
2.2.3 堆排序
没有坚持的努力实质上并没有太大的意义!
一、排序的概念及其运用
1.1 排序的概念
排序 :所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。 稳定性 :假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i]=r[j] ,且r[i]在r[j] 之前,而在排序后的序列中, r[i] 仍在 r[j] 之前,则称这种排 序算法是稳定的;否则称为不稳定的。稳定的:直接插入排序、冒泡排序、归并排序
不稳定的:希尔排序、选择排序、堆排序、快速排序
内部排序 :数据元素全部放在内存中的排序。 外部排序 :数据元素太多不能同时放在内存中,根据排序过程的要求不能在内外存之间移动数据的排序。1G = 1024MB 1024MB = 1024*1024KB 1024*1024KB = 1024 * 1024 * 1024byte(10亿)
(1) 直接插入排序、希尔排序、直接选择排序、桶排序、冒泡排序、快速排序、归并排序都是内部排序。 归并排序可以外部排序
(2)内部排序:数据在内存中,速度快、下标可以随机访问(因为是数组);外部排序:数据在磁盘、速度慢、串行访问(文件)、数据量很大
给一个10亿(4G内存)个整数的文件,但是只给1G的运行内存,请对文件的10亿个数据进行排序?
思想:数据量大加载不到内存,想办法控制两个有序文件归并成一个更大的有序文件
思路:首先分成4等份,分别读到内存排序(这里不能使用归并排序,因为需要额外空间),排完序,写回到磁盘小文件,然再磁盘中,进行归并
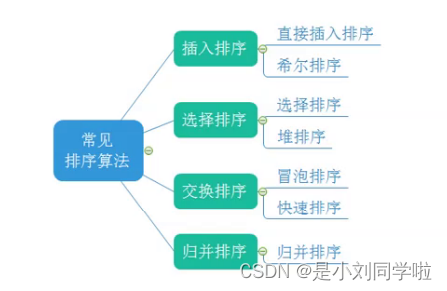
1.2 常见的算法排序
冒泡排序= 0) { if (a[end]
第二层循环的n-gap也是最后一个元素的下标,但是一共有gap组,所以是n-gap
预排序:大的数据更快的来到后面,更小的数据更快的来到前面 ,使其接近有序
首先分组,取gap = 3,然后取第一个元素,第四个元素,第七个元素……(直到这个元素的下标大于数组的最后一个下标)分为一组;取第二个元素,第五个元素……分为一组;取第三个元素,第六个元素……分为一组;【gap是多少,就分为多少组】分完组之后,进行排序,分别使用直接插入排序对这gap组数据进行排序
如果gap越小,越接近有序;gap越大,大的数据可以更快的到最后,小的数据可以更快的到前面,但是它越不接近有序。
时间复杂度:O(N*log以3为底N的对数),平均是O(N^1.3)
看预排序部分,如果gap很大,那么最里面的循环,可以忽略不计,就是O(N),
如果gap很小,数据已经非常接近有序了,那么就也是O(N)。
看最外面的循环,N/3/3/3/3/3……/3=1 即3的x次方等于N,即log以3为底N的对数
稳定性:不稳定
2.2 选择排序
2.2.1 基本思想
每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完。2.2.2 直接选择排序
遍历找出最大和最小的数的位置, 放在数组的两头位置【注意:这里是交换元素,否则就会覆盖数据】,然后遍历找出次小和次大的数字,放在数组的次头位置……一直到全数据元素排完。
代码展示:【优化后的】没有优化的是一次找一个元素
void SelectSort(int* a, int n)
{
int left = 0;
int right = n - 1;
while (left
注意:(第一次进行最小值进行交换的时候)如果left_0是最大值,最大值此时换到mini_5的位置,/maxi最大位置本来是0,但是此时最大值被换到5的位置,那么此时最小值会被换到最后
1.
直接选择排序思考非常好理解,但是效率不是很好。实际中很少使用
2.
时间复杂度:
O(N^2)
在最好的情况下、最差的情况下时间复杂度都为O(N),因为无论有序、无序都要进行遍历找出最大和最小的元素下标
3.
空间复杂度:
O(1)
4.
稳定性:不稳定
直接选择排序是优于冒泡排序的,但是在数据有序或者接近有序的情况下,冒泡排序是优于直接选择排序的。
2.2.3 堆排序
详细内容见:堆排序链接
堆排序
(Heapsort)
是指利用堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的一种。它是通过堆来进行选择数据。需要注意的是排升序要建大堆,排降序建小堆。
1.
堆排序使用堆来选数,效率就高了很多。
2.
时间复杂度:
O(N*logN)
3.
空间复杂度:
O(1)
4.
稳定性:不稳定



