
最全的正则表达式教程
温馨提示:这篇文章已超过406天没有更新,请注意相关的内容是否还可用!
一、正则基础概述
首先给出正则最基础的知识点概述,好让同学们能回想起一些之前学过的知识点,能更好地进行阅读
这里分享一个在线练习正则的网站,同学们可以在这里进行练习 --> [ 在线练习 ]
笔记中例子中如特殊没有指出,则默认使用 /g 标志(修饰符)全局搜索作为示范
1、什么是正则表达式?
正则表达式是一组由字母和符号组成的特殊文本,它可以用来从文本中找出满足你想要的格式的句子。通俗的讲就是按照某种规则去匹配符合条件的字符串
一个正则表达式是一种从左到右匹配主体字符串的模式。 “Regular expression”这个词比较拗口,我们常使用缩写的术语“regex”或“regexp”。 正则表达式可以从一个基础字符串中根据一定的匹配模式替换文本中的字符串、验证表单、提取字符串等等
2、基础语法图表
Ⅰ - 基础语法表格
首先先给出最最基础部分的匹配规则,这个是肯定要会的
| single char (单字符) | quantifiers(数量) | position(位置) |
|---|---|---|
| \d 匹配数字 | * 0个或者更多 | ^一行的开头 |
| \w 匹配word(数字、字母) | + 1个或更多,至少1个 | $一行的结尾 |
| \W 匹配非word(数字、字母) | ? 0个或1个,一个Optional | \b 单词"结界"(word bounds) |
| \s 匹配white space(包括空格、tab等) | {min,max}出现次数在一个范围内 | |
| \S 匹配非white space(包括空格、tab等) | {n}匹配出现n次的 | |
| . 匹配任何,任何的字符 |
Ⅱ - 常用语法示例图解析
此处暂时看不懂没关系,后面会进行详细的语法介绍,此处只是让我们对正则表达式更有概念,感觉不好理解可以跳过,学完再回来看
此示例图解析部分主要摘录自 comer的60分钟正则从入门到深入,本人觉得其图画的挺好的,且确实刚开始可以稍微看下正则具体应用,方便后续理解,便摘录下来
a) 通用正则表达式
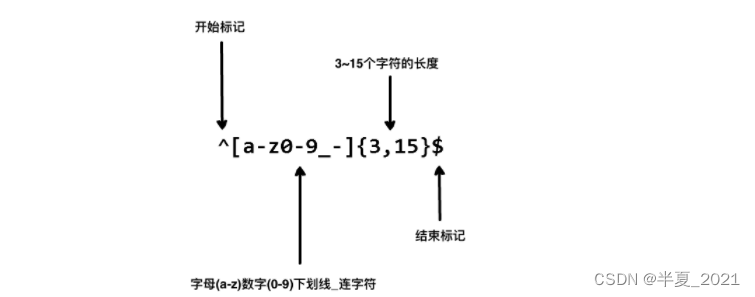
b) 手机号正则
/^1[34578][0-9]{9}$/
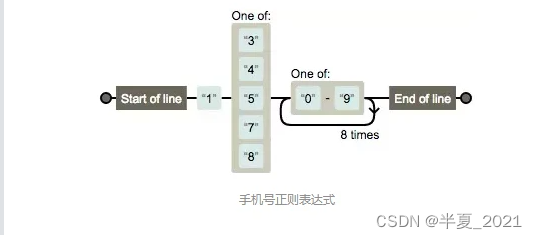
c) 日期匹配与分组替换
/^\d{4}[/-]d{1,2}[/-]\d{1,2}$/
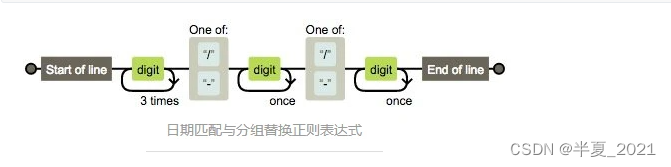
这个正则比较复杂,画符念咒的地方太多了,一一分析:
- Start of line 是由^生效的表示以此开头
- 对应结尾End of line 由$生效表示以此结尾
- 接着看digit 由 d 生效表示数字
- 3times 由{4} 生效表示重复4次,开始的时候有疑问,为什么不是 4times 。后来明白作者的用意,正则表达式是一个规则,用这个规则去从字符串开始匹配到结束(注意计算机读字符串可是不会分行的,都是一个串,我们看到的多行,人家会认为是个 t )这里设计好像小火车的轨道一直开到末尾。digit 传过一次,3times表示再来三次循环,共4次,后面的once同理。 自己被自己啰嗦到了。
- 接下来,是 one of 在手机正则里面已经出现了。表示什么都行。只要符合这两个都让通过。
好了这个正则解释完了,接下来用它做什么呢?
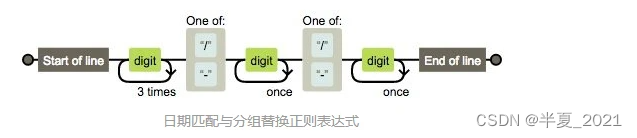
我们可以验证日期的合法性
结合URL分组替换所用到的分组特性,我们可以轻松写出日期格式化的方法
改造下这个正则
/^(\d{4})[/-](\d{1,2})[/-](\d{1,2})$/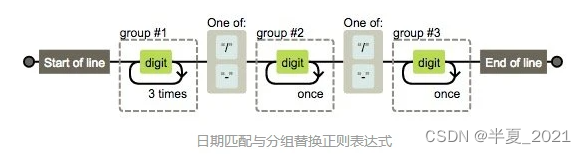
轻松的可以拿到 group#1 #2 #3 的内容,对应 $1 $2 $3

3、基本匹配
正则表达式其实就是在执行搜索时的格式,它由一些字母(也可以是汉字)和数字组合而成。
例如:一个正则表达式 学习的汪 H,它表示一个规则:由学开始,接着是习,…最后H。它是组个字符与输入的正则表达式作比较,同时大小写敏感
"学习的汪 H" => 努力学习的汪 hongjilin //无符合匹配字符串 努力学习的汪 Hongjilin //其中的 [ 学习的汪 H ] 高亮
结果示例: 这里分享一个在线练习正则的网站,同学们可以在这里进行练习 --> [ 在线练习 ]

二、元字符
正则表达式主要依赖于元字符。 元字符不代表他们本身的字面意思,他们都有特殊的含义。一些元字符写在方括号中的时候有一些特殊的意思
1、元字符列举
以下是一些元字符的列举:
元字符 描述 . 句号匹配任意单个字符除了换行符。 [ ] 字符种类。匹配方括号内的任意字符。 [^ ] 否定的字符种类。匹配除了方括号里的任意字符 * 匹配>=0个重复的在*号之前的字符。 + 匹配>=1个重复的+号前的字符。 ? 标记?之前的字符为可选. {n,m} 匹配num个大括号之前的字符或字符集 (n //此处给出三个点 就是前三位为任意 努力学习的汪 hongjilin //其中的 [ 汪 ho ] 高亮 努力学习的汪 Hongjilin //其中的 [ 汪 Ho ] 高亮 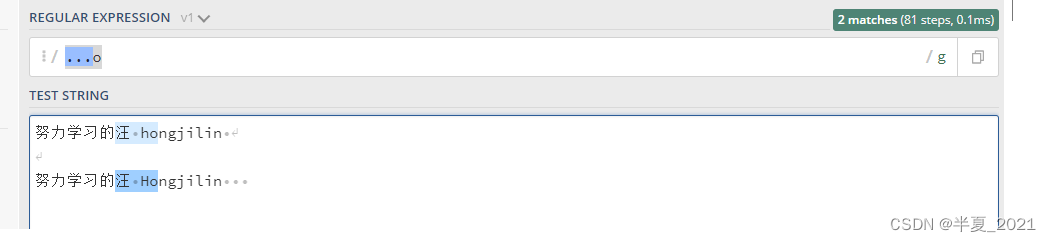
3、字符集
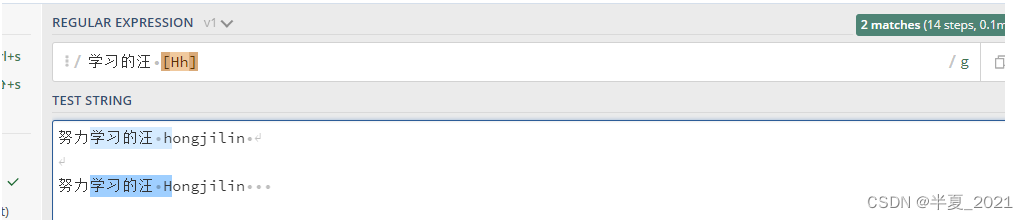
字符集也叫做字符类。 方括号用来指定一个字符集。 在方括号中使用连字符来指定字符集的范围。 在方括号中的字符集不关心顺序。 例如,表达式 [ 学习的汪 [Hh] ] 匹配 [ 学习的汪 h ] 和 [ 学习的汪 H ] 。
"学习的汪 [Hh]" => 努力学习的汪 hongjilin //其中的 [ 学习的汪 h ] 高亮 努力学习的汪 Hongjilin //其中的 [ 学习的汪 H ] 高亮
Ⅰ- 字符集中匹配句号. -->> [.]
前面我们说过点运算符,那同学们是否会有个疑惑, . 被用来匹配任意字符,那么作为字符串中的句号.,又该用什么匹配呢?
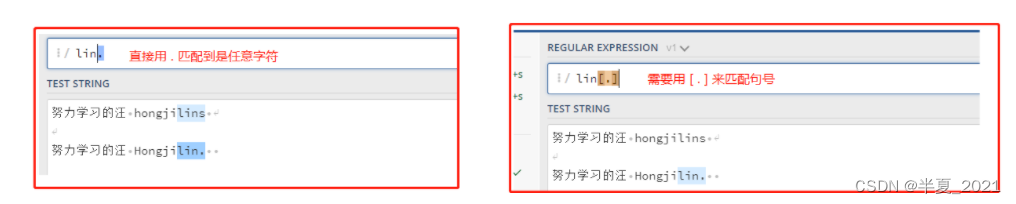
方括号的句号就表示句号。 表达式 lin[.] 匹配 lin.字符串
"lin[.]" => 努力学习的汪 hongjilins 努力学习的汪 Hongjilin.
Ⅱ - 否定字符集 -->> [^]
一般来说 ^ 表示一个字符串的开头,但它用在一个方括号的开头的时候,它表示这个字符集是否定的。 例如,表达式[^地]学习的[^帅] 匹配一个字符串为 [ 学习的 ]的, 同时前面一位字符串不能为地,后面一位字符串不能为帅
"[^地]学习的[^帅]" => 努力学习的汪 hongjilins //只有此处高亮 努力学习的帅汪 Hongjilin. 帅气地学习的

a) 一个特殊的用法
正则表达式中,点(.)是一个特殊字符,代表任意的单个字符,但是有两个例外。一个是四个字节的 UTF-16 字符,这个可以用u修饰符解决;另一个是行终止符(line terminator character)。
所谓行终止符,就是该字符表示一行的终结。以下四个字符属于“行终止符”。
- U+000A 换行符(\n)
- U+000D 回车符(\r)
- U+2028 行分隔符(line separator)
- U+2029 段分隔符(paragraph separator)
/foo.bar/.test('foo\nbar') // false上面代码中,因为.不匹配\n,所以正则表达式返回false。
但是,很多时候我们希望匹配的是任意单个字符,这时有一种变通的写法。
/foo[^]bar/.test('foo\nbar') // true当然,这种解决方案毕竟不太符合直觉, ES2018 引入s修饰符,使得.可以匹配任意单个字符。
/foo.bar/s.test('foo\nbar') // trueⅢ - 重复次数 -->> *、+、?
后面跟着元字符 +,* or ? 的,用来指定匹配子模式的次数。 这些元字符在不同的情况下有着不同的意思。
a) * 号
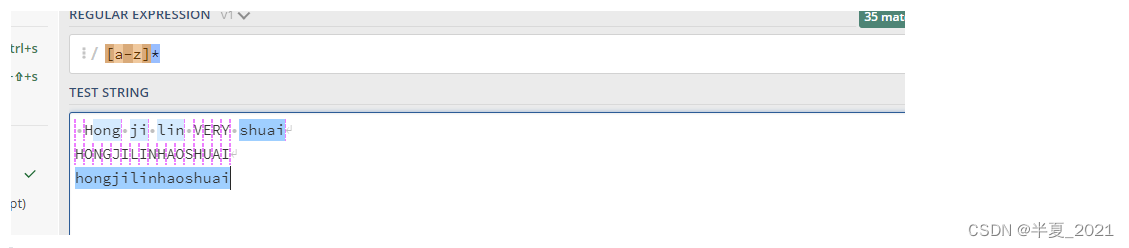
*号匹配 在*之前的字符出现大于等于0次。 例如,表达式 a* 匹配0或更多个以a开头的字符。表达式[a-z]* 匹配一个行中所有以小写字母开头的字符串。
"[a-z]*" => Hong ji lin VERY shuai //部分高亮 HONGJILINHAOSHUAI //全部不亮 hongjilinhaoshuai //全部高亮
*号搭配 .号
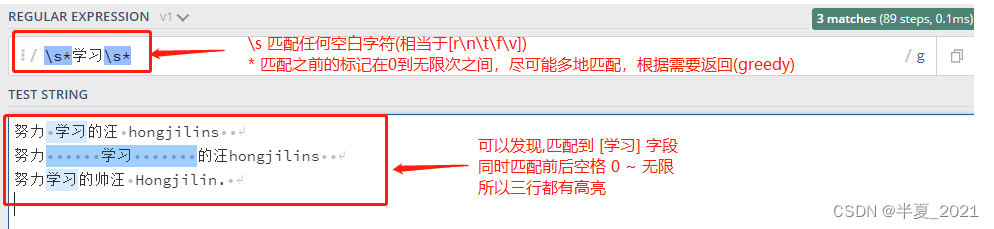
*字符和.字符搭配可以匹配所有的字符.*。 *和表示匹配空格的符号\s连起来用,如表达式\s*学习\s*匹配0或更多个空格开头和0或更多个空格结尾的cat字符串。
"\s*学习\s*" => //0~无限次,所以只要有[ 学习 ]都会被匹配,同时会被匹配的还有其紧靠的无限次的空格 努力 学习的汪 hongjilins //[ 学习 ]前一个空格,后面无空格 努力 学习 的汪hongjilins //[ 学习 ]前后多个空格 努力学习的帅汪 Hongjilin. //[ 学习 ] 前后无空格
b) +号
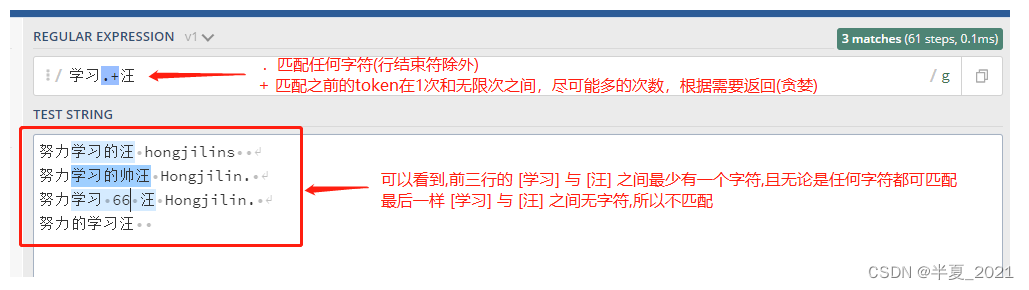
+号匹配+号之前的字符出现 >=1 次。 例如表达式学习.+汪 匹配以中文(也可以是字母)学习开头以 [汪] 结尾,中间跟着至少一个字符的字符串。
"学习.+汪" => 努力学习的汪 hongjilins 努力学习的帅汪 Hongjilin. 努力学习 66 汪 Hongjilin. 努力的学习汪 //此行无匹配结果
c) ? 号
在正则表达式中元字符 ? 标记在符号前面的字符为可选,即出现 0 或 1 次。 例如,表达式 学习的[帅]?汪 匹配字符串 学习的汪 和 学习的帅汪。
"学习的[帅]?汪" => 努力学习的汪 hongjilins 努力学习的帅汪 Hongjilin. 努力的学习汪 //无匹配结果 努力学习的帅气汪 Hongjilin. //无匹配结果

Ⅳ - 量词 -->> {}
a) 正常使用示例
在正则表达式中 {} 是一个量词,常用来限定一个或一组字符可以重复出现的次数。 例如, 表达式 [0-9]{2,3} 匹配最少 2 位最多 3 位 0~9 的数字。
"[0-9]{2,3}" => 努力学习的1汪1 努力学习的233汪 努力学习的4个4444汪 努力学习的5个55555汪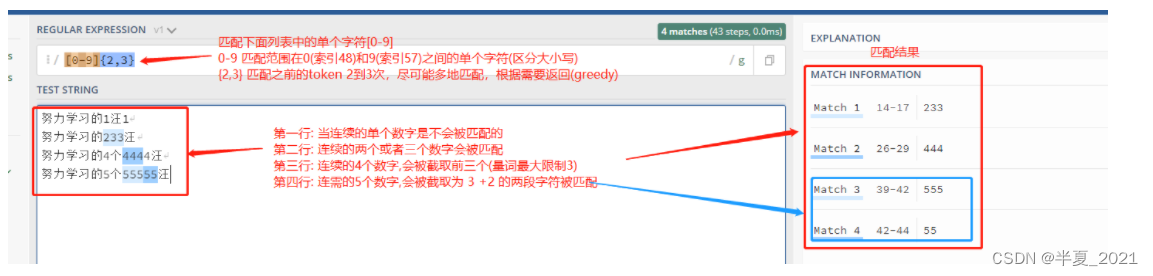
b) 省略第二个参数,带逗号
我们可以省略第二个参数。 例如,[0-9]{2,} 匹配至少两位 0~9 的数字。
"[0-9]{2,}" => 努力学习的1汪1 努力学习的233汪 努力学习的4个4444汪 努力学习的5个55555汪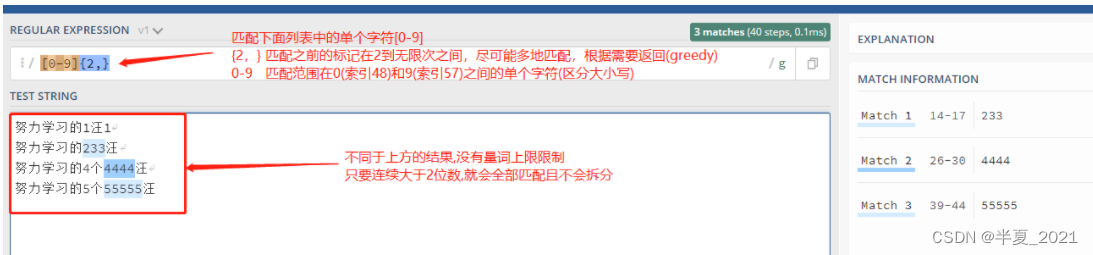
c) 逗号也省略
如果逗号也省略掉则表示重复固定的次数。 例如,[0-9]{2} 匹配2位数字
"[0-9]{2}" => 努力学习的1汪1 努力学习的233汪 努力学习的4个4444汪 努力学习的5个55555汪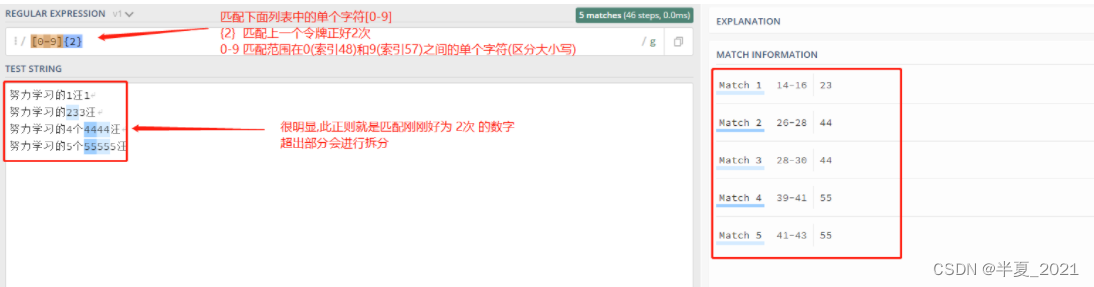
Ⅴ- 特征标群 -->> (...)
特征标群是一组写在 (...) 中的子模式。(...) 中包含的内容将会被看成一个整体,和数学中小括号( )的作用相同。例如, 表达式 (ab)* 匹配连续出现 0 或更多个 ab。如果没有使用 (...) ,那么表达式 ab* 将匹配连续出现 0 或更多个 b 。再比如之前说的 {} 是用来表示前面一个字符出现指定次数。但如果在 {} 前加上特征标群 (...) 则表示整个标群内的字符重复 N 次。
我们还可以在 () 中用或字符 | 表示或。例如,(学习|打工)的汪 匹配 学习的汪 或 打工的汪 .
"(学习|打工)的汪 (hong){2}" => 努力学习的汪 hongjilins 努力学习打工的汪 hongjilins 努力打工的汪 honghongjilins 努力学习打工的汪 honghongjilins
Ⅵ - 或运算符 -->> |
或运算符就表示或,用作判断条件。
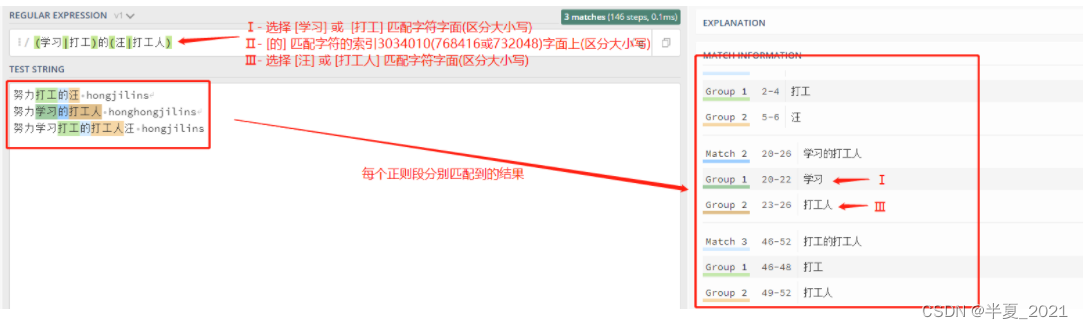
举个栗子: (学习|打工)的(汪|打工人) 进行匹配
"(学习|打工)的(汪|打工人)" => 努力打工的汪 hongjilins 努力学习的打工人 honghongjilins 努力学习打工的打工人汪 hongjilins
Ⅶ - 转码特殊字符 -->> \
反斜线 \ 在表达式中用于转码紧跟其后的字符。用于指定 { } [ ] / \ + * . $ ^ | ? 这些特殊字符。如果想要匹配这些特殊字符则要在其前面加上反斜线 \。
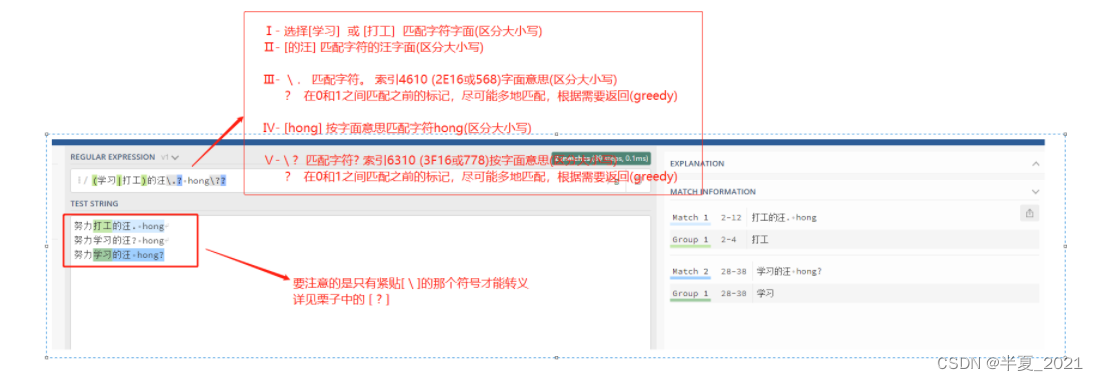
例如 . 是用来匹配除换行符外的所有字符的。如果想要匹配句子中的 . 则要写成 \. 以下这个例子 \.?是选择性匹配.
"(学习|打工)的汪\.? hong\??" => 努力打工的汪. hong 努力学习的汪? hong 努力学习的汪 hong?
Ⅷ - 锚点(边界) -->> ^、$、\b、\B
在正则表达式中,想要匹配指定开头或结尾的字符串就要使用到锚点。^ 指定开头,$ 指定结尾。
通常也会搭配标志(修饰符)相关知识点使用
由于还未说到标志相关知识,此处例子仍使用 [ /g ]全局搜索,如果对此有疑惑的可以留着疑问看下方的 五、标志
a) ^ 号
^ 用来检查匹配的字符串是否在所匹配字符串的开头。
例如,在 abc 中使用表达式 ^a 会得到结果 a。但如果使用 ^b 将匹配不到任何结果。因为在字符串 abc 中并不是以 b 开头。
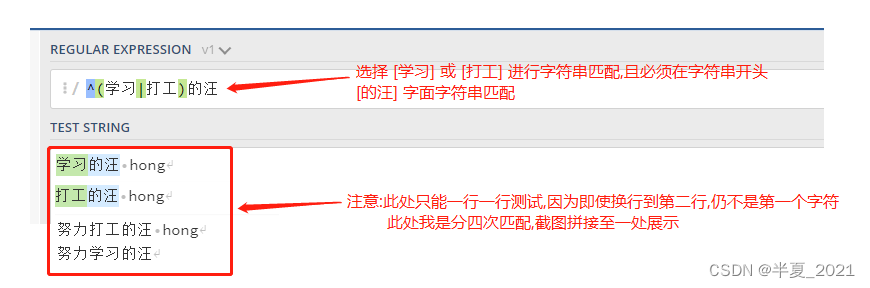
例如,^(学习|打工)的汪 进行匹配
"^(学习|打工)的汪" => //注意:下列字符串要分四次匹配,因为即使换行了,后三行字符串本质上都不在字符串开头 //或者标志换成 /m 而不是 /g 因为此处还未说到标志,所以默认大家使用/g全局搜索 学习的汪 hong 打工的汪 hong 努力打工的汪 hong 努力学习的汪
b) $ 号
同理于 ^ 号,$ 号用来匹配字符是否是最后一个。
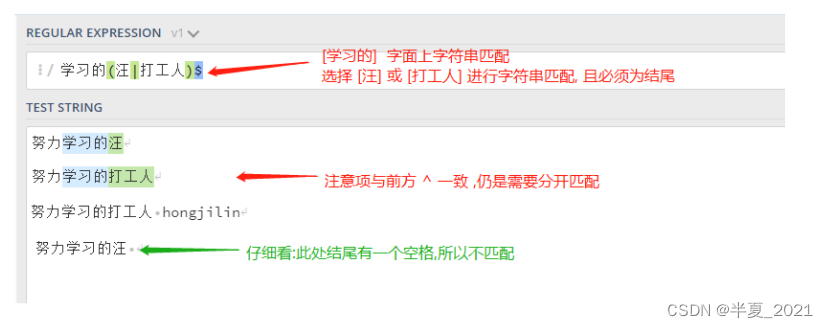
例如,学习的(汪|打工人)$ 匹配以 [ 汪 ] 或者 [ 打工人 ] 结尾的字符串。
"学习的(汪|打工人)$" => //注意:下列字符串要分四次匹配,因为即使换行了,前三行字符串本质上都不在字符串结尾 //或者标志换成 /m 而不是 /g 因为此处还未说到标志,所以默认大家使用/g全局搜索 努力学习的汪 努力学习的打工人 努力学习的打工人 hongjilins 努力学习的汪_ //此处 _ 模拟表示空格
c) 单词边界 \b
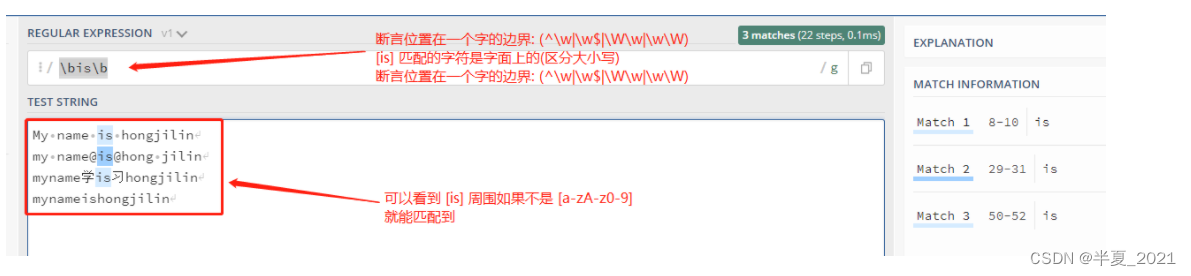
\b : 单词边界:指[a-zA-z0-9]之外的字符,举个栗子:\bis\b
'\bis\b'=> My name is hongjilin my name@is@hong jilin myname学is习hongjilin mynameishongjilin //只有此处不被匹配
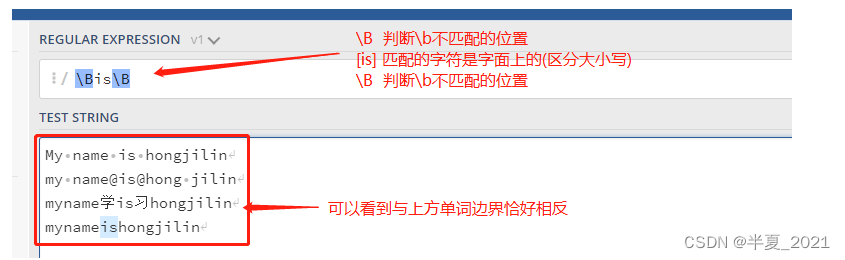
d) 非单词边界 \B
'\Bis\B'=> My name is hongjilin my name@is@hong jilin myname学is习hongjilin mynameishongjilin //只有此处被匹配,与单词边界切好相反
三、简写字符集
这些简写字符集,简洁明了且非常常用,但是也因为这样当初没有仔细去记,用时还得查阅资料十分不便,建议背下来
正则表达式提供一些常用的字符集简写。如下:
简写 描述 . 除换行符外的所有字符 \w 匹配所有字母数字,等同于 [a-zA-Z0-9_] \W 匹配所有非字母数字,即符号,等同于: [^\w] \d 匹配数字: [0-9] \D 匹配非数字: [^\d] \s 匹配所有空格字符,等同于: [\t\n\f\r\p{Z}] \S 匹配所有非空格字符: [^\s] \f 匹配一个换页符 \n 匹配一个换行符 \r 匹配一个回车符 \t 匹配一个制表符 \v 匹配一个垂直制表符 \p 匹配 CR/LF(等同于 \r\n),用来匹配 DOS 行终止符 四、零宽度断言 (前后预查)
先行断言和后发断言都属于非捕获簇(不捕获文本 ,也不针对组合计进行计数)。 先行断言用于判断所匹配的格式是否在另一个确定的格式之前,匹配结果不包含该确定格式(仅作为约束)。
例如,我们想要获得所有跟在 $ 符号后的数字,我们可以使用正后发断言 (? $0.,1,2,3,$4,5,6,$?7,8,$..9.9? //0. //4 //?7 //..9.9?
零宽度断言如下:
符号 描述 ?= 正先行断言-存在 ?! 负先行断言-排除 ?负后发断言-排除 1、 正先行断言 -->> ?=...
?=... 正先行断言,表示第一部分表达式之后必须跟着 ?=...定义的表达式。
返回结果只包含满足匹配条件的第一部分表达式(即不会返回先行断言匹配部分的内容)。 定义一个正先行断言要使用 ()。在括号内部使用一个问号和等号: (?=...)。
正先行断言的内容写在括号中的等号后面。 例如,表达式 学习的汪(?=\shong) 首先匹配 [ 学习的汪 ],然后在括号中我们又定义了正先行断言 (?=\shong) ,即 [ 学习的汪 ]后面紧跟着 [ (空格)hong ]。
"学习的汪(?=\shong)" => //此处断言中的可以再加如`+` 、`*` ......,此处举其中一个栗子说明 努力学习的汪 hong //只有此处被匹配到 返回: [学习的汪] -->断言中的匹配项作为约束不会返回 努力学习的汪 帅 努力学习的汪hong //此处后面没有空格
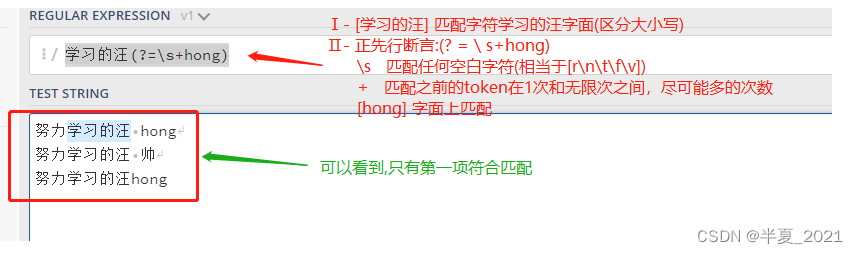
2、负先行断言 -->> ?!...
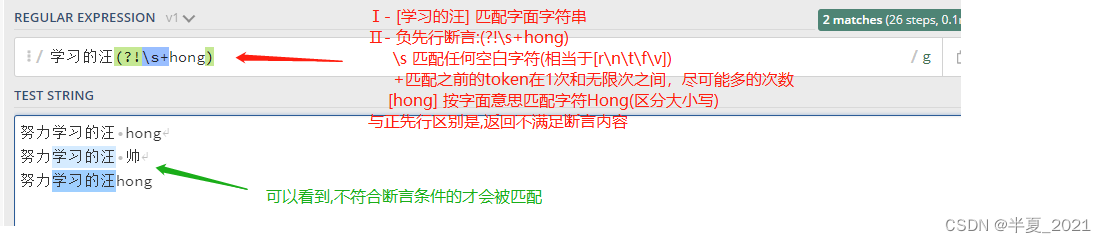
负先行断言 ?! 用于筛选所有匹配结果,筛选条件为 其后不跟随着断言中定义的格式。 正先行断言 定义和 负先行断言 一样,区别就是 = 替换成 ! 也就是 (?!...)。
表达式 学习的汪(?!\s+hong) 首先匹配 [ 学习的汪 ],然后在括号中我们又定义了负先行断言 (?!\shong) ,即 [ 学习的汪 ]后面不跟着 [ (空格)hong ]。
"学习的汪(?!\s+hong)" => 努力学习的汪 hong //只有此处不被匹配到 努力学习的汪 帅 努力学习的汪hong
3、 正后发断言 -->> ? ?
负后发断言 记作 (?
"/(?



