
【C++】详解priority
温馨提示:这篇文章已超过432天没有更新,请注意相关的内容是否还可用!

目录
一、priority_queue 的介绍和使用
1.1priority_queue 的介绍
2.2priority_queue 的使用
二、仿函数
2.1什么是仿函数
2.2仿函数的作用
三、函数对象的特点(知识点多)
3.1分析特点5(比较普通函数与函数对象)
3.1.1利用普通函数传递参数
拓展之:深度剖析函数利用模板的本质
3.1.2利用函数对象传递参数
3.1.3函数对象作为for_each的参数(知识点较多)
2.第三个参数传递函数:(计算从0到100)
3.第三个参数传递函数对象:(计算从0到100)
4.难点:关于第三个参数是传值的易错点
5.拓展:如果我重写for_each,加上引用,会不会得到我想要的效果?
3.2分析特点6(一共俩句话)
3.2.1分析保持函数的调用状态(本质是因为成员变量不会销毁)
3.2.2参数个数可变是什么意思?代码分析过程中居然用到了匿名对象!
1.分析函数对象的用法及匿名对象
2.探究匿名对象的生命周期
3.回忆匿名对象拆分开怎么写
4.讨论多参数问题(多参数不是重载函数多,而是类中多变量)
四、函数对象的分类
4.1一元函数
4.2二元函数
4.3一元判定函数
4.4二元判定函数
五、总结知识点(未完待续.....)
一、priority_queue 的介绍和使用
1.1priority_queue 的介绍
priority_queue (优先级队列)是一种容器适配器,它与 queue 共用一个头文件,其底层结构是一个堆,并且默认情况下是一个大根堆,所以它的第一个元素总是它所包含的元素中最大的,并且为了不破坏堆结构,它也不支持迭代器。
同时,由于堆需要进行下标计算,所以 priority_queue 使用 vector 作为它的默认适配容器 (支持随机访问):

但是,priority_queue 比 queue 和 stack 多了一个模板参数 – 仿函数;关于仿函数的具体细节,我们将在后文介绍
class Compare = less
2.2priority_queue 的使用
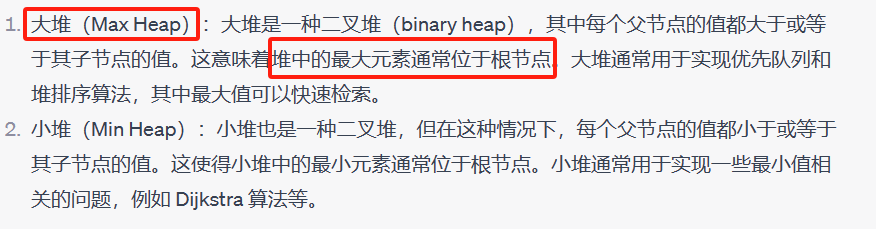
优先级队列默认使用 vector 作为其底层存储数据的容器,在 vector 上又使用了堆算法将 vector 中元素构造成堆的结构,因此 priority_queue 就是堆,所有需要用到堆的位置,都可以考虑使用 priority_queue。(注意:默认情况下priority_queue是大堆)
priority_queue 的使用文档
| 函数声明 | 接口说明 |
| priority_queue() | 构造一个空的优先级队列 |
| priority_queue(first, last) | 迭代器区间构造优先级队列 |
| empty( ) | 检测优先级队列是否为空 |
| top( ) | 返回优先级队列中最大(最小元素),即堆顶元素 |
| push(x) | 在优先级队列中插入元素x |
| pop() | 删除优先级队列中最大(最小)元素,即堆顶元素 |
| size() | 返回优先级队列中的元素个数 |
注意事项:
priority_queue 默认使用的仿函数是 less,所以默认建成的堆是大堆;如果我们想要建小堆,则需要指定仿函数为 greater,该仿函数包含在头文件 functional 中,并且由于仿函数是第三个缺省模板参数,所以如果要传递它必须先传递第二个模板参数即适配容器


void test_priority_queue() {
priority_queue pq; //默认建大堆,仿函数为less
pq.push(5);
pq.push(2);
pq.push(4);
pq.push(1);
pq.push(3);
while (!pq.empty()) {
cout 


