
数学建模:相关性分析学习——皮尔逊(pearson)相关系数与斯皮尔曼(spearman)相关系数
温馨提示:这篇文章已超过395天没有更新,请注意相关的内容是否还可用!
目录
前言
一、基本概念及二者适用范围比较
1、什么是相关性分析
2、什么是相关系数
3、适用范围比较
二、相关系数
1.皮尔逊相关系数(Pearson correlation)
1、线性检验
2、正态检验
3、求相关系数
2、斯皮尔曼相关系数(Spearman correlation)
1、秩相关系数
2、使用条件
3、求相关系数
3、结果对比
总结
前言
为参加数学建模做准备!从相关性分析学起!
一、基本概念及二者适用范围比较
1、什么是相关性分析
相关分析是指对两个或多个具备相关性的变量元素进行分析,从而衡量两个因素的的相关密切程度,相关性的元素之间需要存在一定的联系或者概率才可以进行相关性分析。
2、什么是相关系数
相关系数是反映两个变量之间线性相关程度的指标。
- 皮尔逊相关系数(Pearson correlation): 用于衡量两个连续性随机变量间的相关系数
- 斯皮尔曼相关系数(Spearman correlation) :秩相关系数,根据原始数据的等级排序进行求解,也称为等级变量之间的皮尔逊相关系数
(还有一种Kendall相关系数暂不作了解)
以上两种系数是两个变量之间变化趋势的方向以及程度,取值范围为[-1, 1]。当接近1时,表示两者具有强烈的正相关性;当接近-1时,表示有强烈的的负相关性;而值接近0,则表示相关性很低。
3、适用范围比较
斯皮尔曼相关系数和皮尔逊相关系数选择:
1.连续数据,正态分布,线性关系,使用pearson相关系数最为恰当,用spearman相关系数也可以, 就是效率没有pearson相关系数高。
2.上述三个条件均满足才能使用pearson相关系数,否则就用spearman相关系数。
3.定序数据之间也只用spearman相关系数,不能用pearson相关系数。
注:(1)定序数据是指仅仅反映观测对象等级、顺序关系的数据,是由定序尺度计量形成的,表现为类别,可以进行排序,属于品质数据。
例如,对成绩进行排名后,对排名进行数学运算就没有意义了。定序数据最重要的意义代表了一组数据中的逻辑顺序。
(2)斯皮尔曼相关系数的适用条件比皮尔逊相关系数要广,只要数据满足单调关系(例如线性函数、指数函数、对数函数等)就能够使用。
二、相关系数
1.皮尔逊相关系数(Pearson correlation)
当两个变量都是正态连续变量,且两者之间呈线性关系时,则可以用Pearson来计算相关系数。取值范围[-1,1]。计算公式如下:

从形式上看即为概率论中所学的相关系数。
变量相关强度:
相关程度 极强相关 强相关 中等程度相关 弱相关 极弱相关或无相关 相关系数绝对值 0.8——1 0.6——0.8 0.4——0.6 0.2——0.4 0——0.2 1、线性检验
一般使用散点图进行线性检验:
import numpy as np from matplotlib import pyplot as plt def linear_test(): #为显示线性关系手动输入的数据 x = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) y = np.array([1, 1, 3, 4, 3, 6, 5, 7, 9, 8, 9]) fig = plt.figure() ax1 = fig.add_subplot(1, 1, 1) ax1.set_title('Linear Test') ax1.set_xlabel('X') ax1.set_ylabel('Y') ax1.scatter(x, y, c='k', marker='.') plt.savefig('linear_test.png') linear_test()
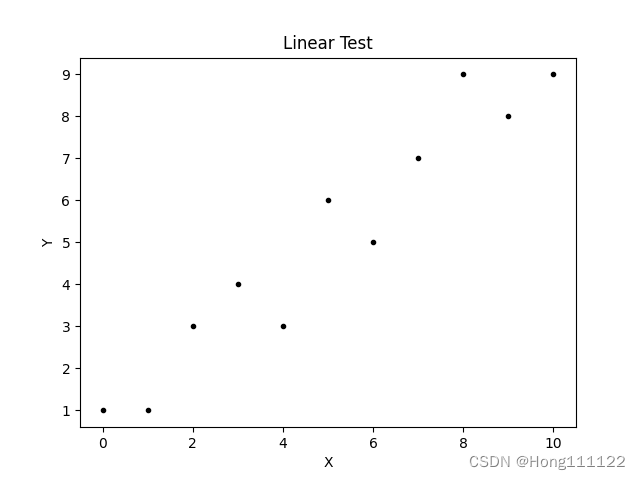
2、正态检验
这里运用到scipy模块的kstest方法,具体代码如下:
def normal_test(): data = np.array([1, 2, 5, 4, 4, 6, 7, 3, 9, 5, 4, 7, 1, 2, 9]) u = data.mean() std = data.std() result = stats.kstest(data, 'norm', (u, std)) print(result)结果:KstestResult(statistic=0.12726344134326134, pvalue=0.9427504251048978)
结果返回两个值:statistic → D值,pvalue → P值
H0:样本符合
H1:样本不符合
p值>0.05则接受H0,该数据为正态分布。3、求相关系数
若以上验证均成功则采取皮尔逊相关系数进行相关性分析:
import pandas as pd # 读取数据 df = pd.read_excel('spearman_data.xlsx') df = pd.DataFrame(df) # print(df) # 生成相关性矩阵 rho = df.corr(method='pearson') print(rho)对生成的相关系数矩阵进行可视化操作(生成热力图):
def heatmapplot(): plt.rcParams['font.family'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False sns.heatmap(rho, annot=True) plt.title('Heat Map', fontsize=18) plt.savefig('heatmap1.png', dpi=300)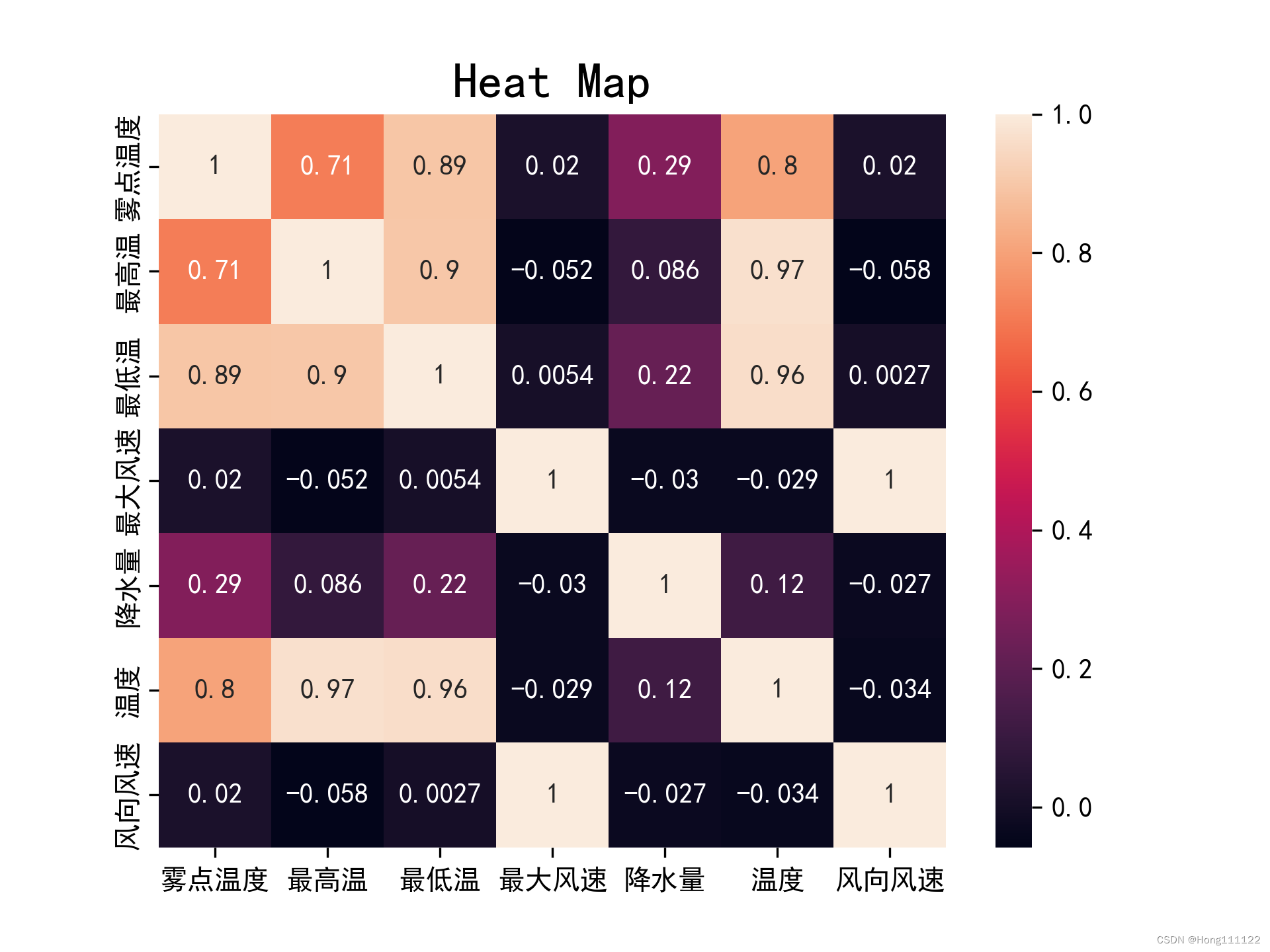
2、斯皮尔曼相关系数(Spearman correlation)
1、秩相关系数
秩相关系数(Coefficient of Rank Correlation),又称等级相关系数,反映的是两个随机变量的变化趋势方向和强度之间的关联,是将两个随机变量的样本值按数据的大小顺序排列位次,以各要素样本值的位次代替实际数据而求得的一种统计量。它是反映等级相关程度的统计分析指标,常用的等级相关分析方法有Spearman相关系数和Kendall秩相关系数等。主要用于数据分析。斯皮尔曼相关系数被定义成等级变量之间的皮尔逊相关系数。
2、使用条件
- 数据为非线性或非正态
- 至少有一组数据为等级类型,如排名,位次
- 数据中有异常值或错误值,斯皮尔曼相关系数对于异常值不太敏感,因为它基于排序位次进行计算,实际数值之间的差异大小对于计算结果没有直接影响
3、求相关系数
较为常用简单的计算公式如下所示:
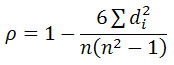
表示第i个数据对的位次值之差
- n 总的观测样本数
使用python求解与上文类似(metho = ‘spearman’)
3、结果对比
两种相关系数的热力图对比:
pearson:
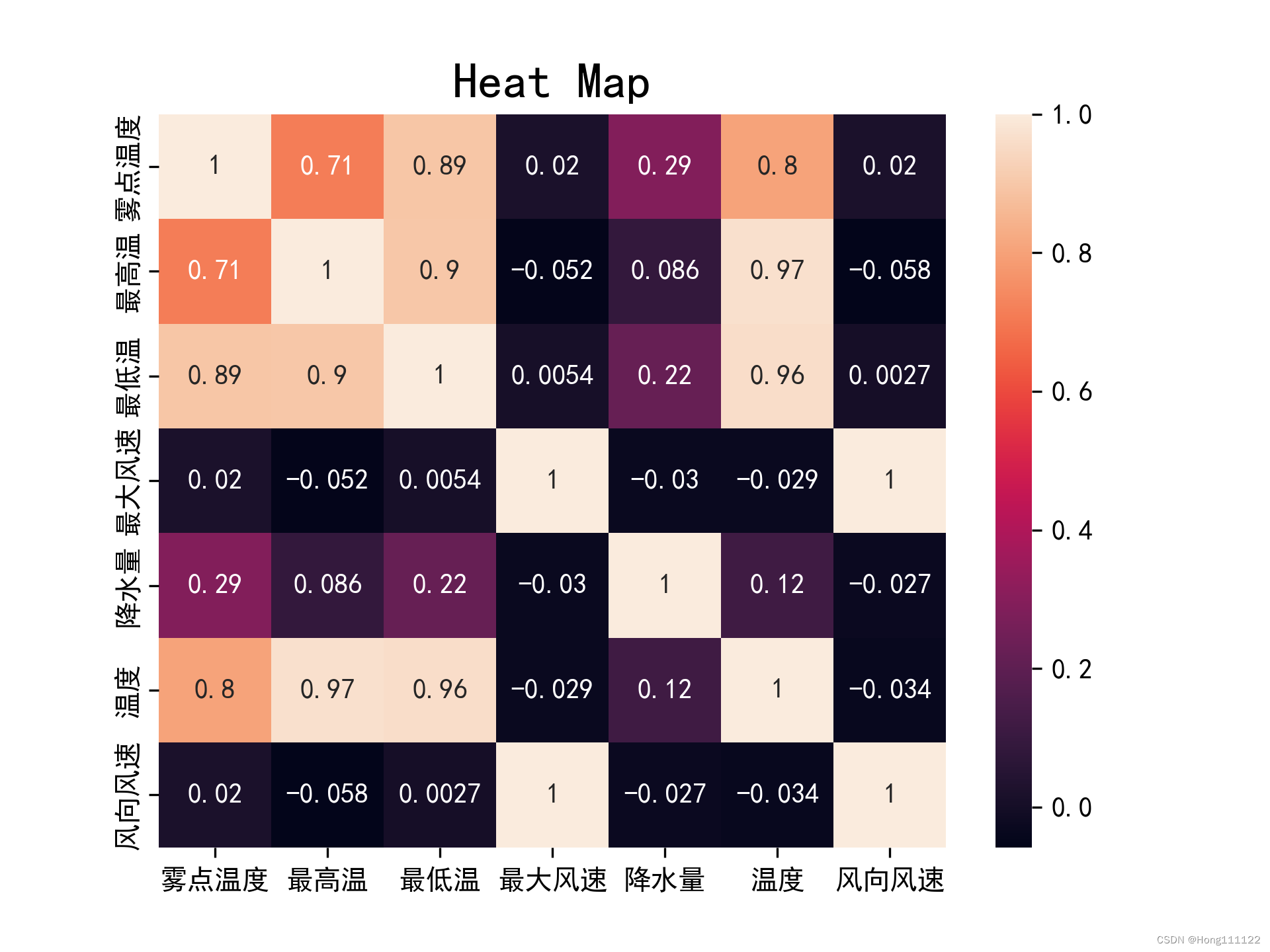
spearman:
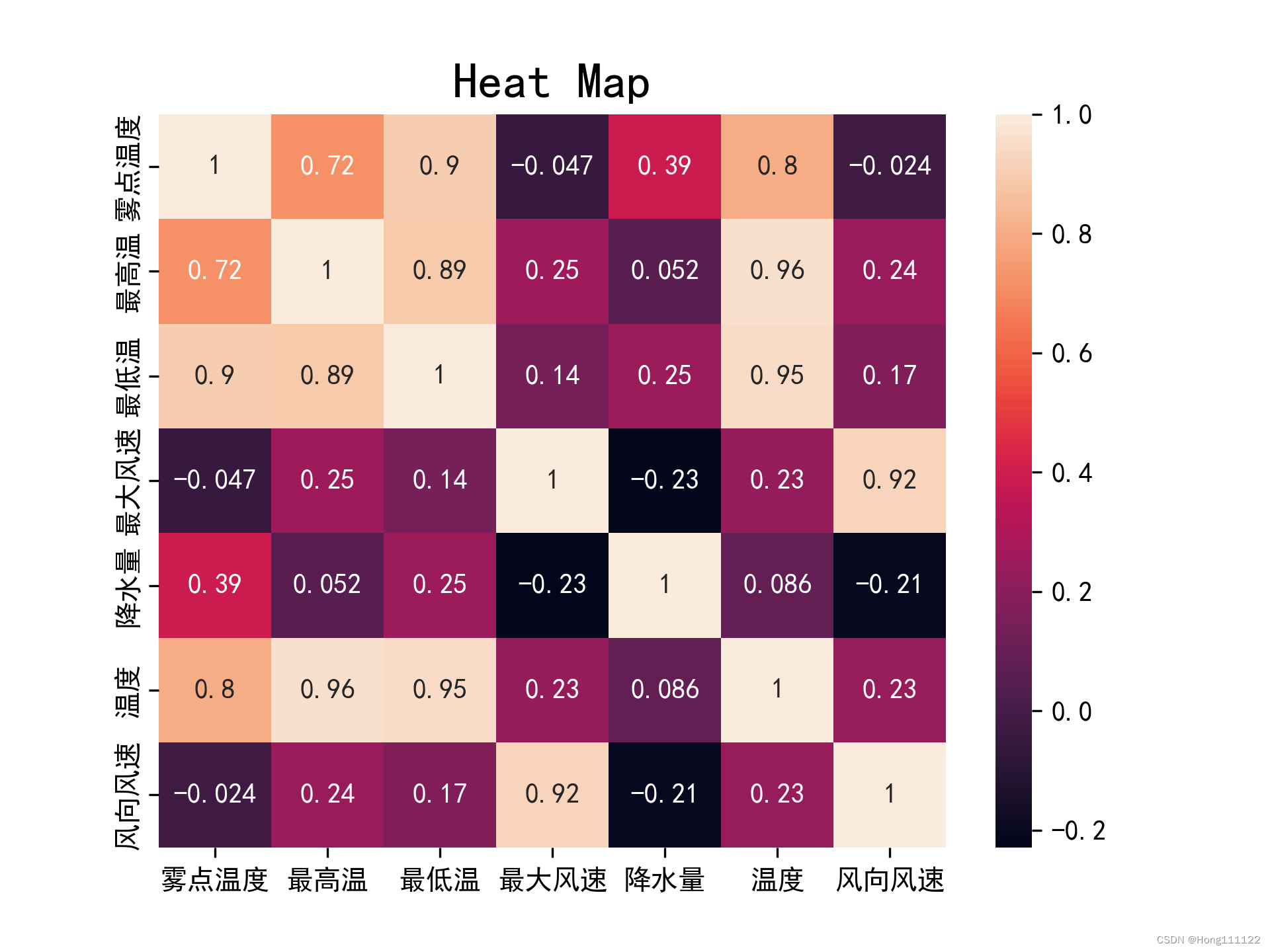
可见,对于同组数据,在满足了正态和线性检验的条件下,Pearson所得结果相对于Spearman会更加的精确和严格。
总结
第一次写学习笔记若有错误希望大佬赐教!
球球各位点个赞。
先行发布,之后会在补充显著性检验等内容。



