
【旅游景点项目日记 | 第二篇】基于Python中的Selenium爬取携程旅游网景点详细数据

文章目录
- 3.基于Python中的Selenium爬取携程旅游网景点详细数据
- 3.1前提环境
- 3.2思路
- 3.3代码详讲
- 3.3.1查询指定城市的所有景点
- 3.3.2获取详细景点的访问路径
- 3.3.3获取景点的详细信息
- 3.4数据库设计
- 3.5全部代码
- 3.6效果图
Gitee仓库地址:travel-server:景点旅游项目服务端
3.基于Python中的Selenium爬取携程旅游网景点详细数据
3.1前提环境
- 确保安装python3.x环境
- 以管理员身份打开cmd,安装selenium、pymysql、datetime,默认安装最新版即可
pip install selenium pip install pymysql pip install datetime
-
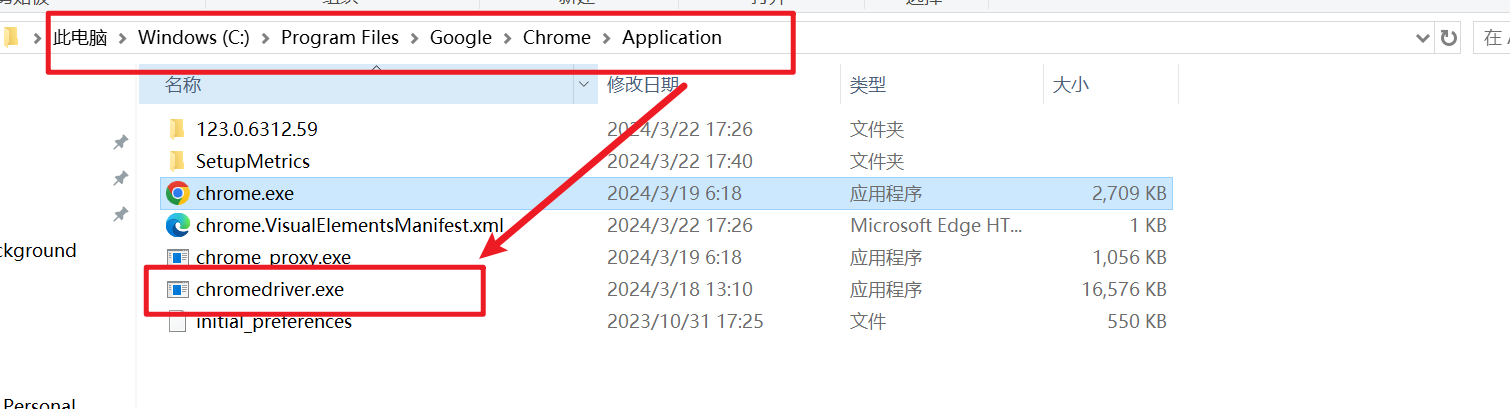
确保chrome安装对应版本的驱动(将该驱动放在chrome安装路径下),用于控制chrome浏览器,并将路径添加到环境变量的Path变量中,如图所示!
#安装chrome驱动教程链接: https://blog.csdn.net/linglong_L/article/details/136283810
3.2思路
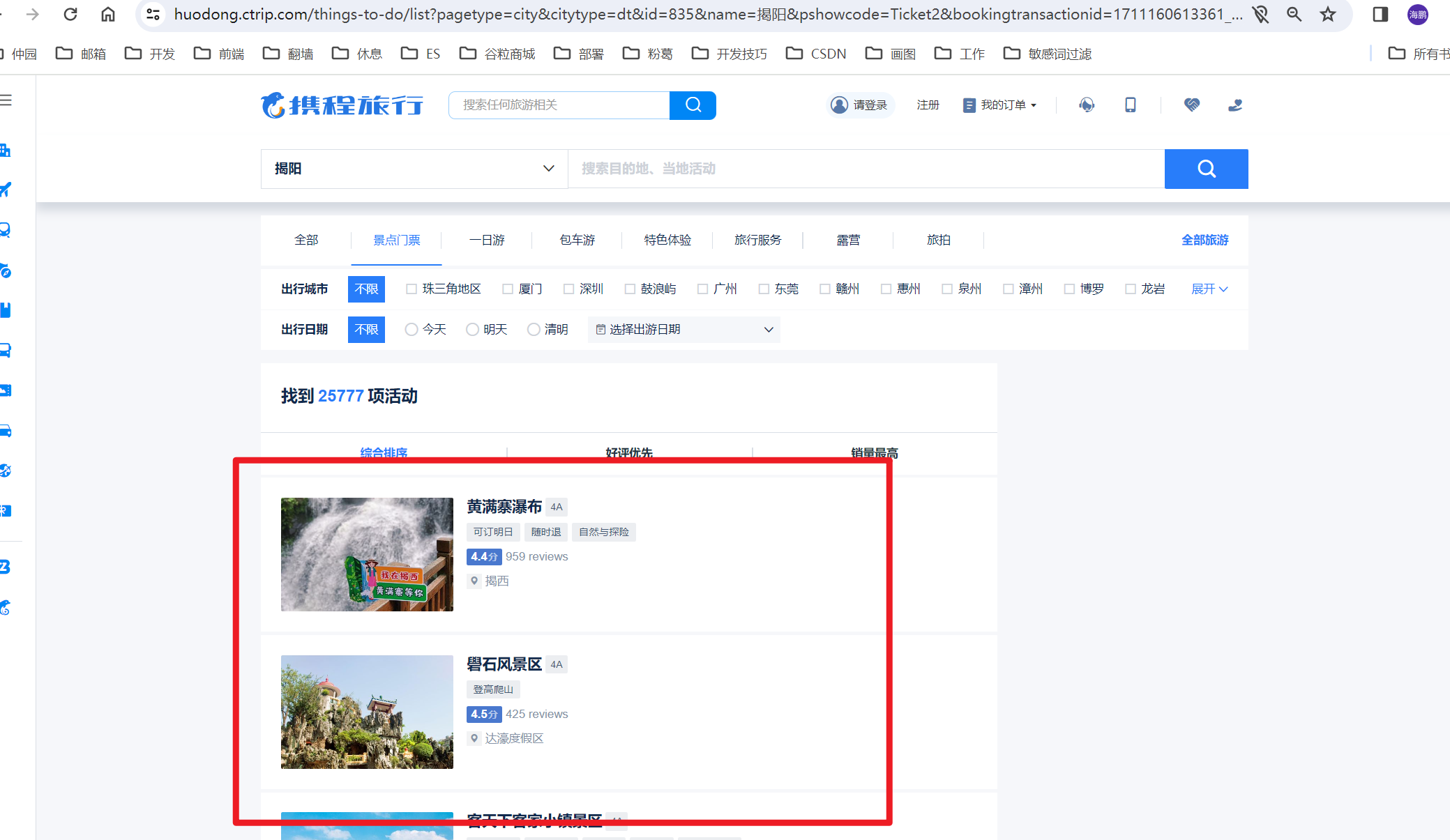
- 搜索指定城市景点,网站通过分页进行展示;
- 使用selenium每个景点的详细访问路径,并点击该路径获取详细景点信息,再通过正则表达式获取需要的内容;
-
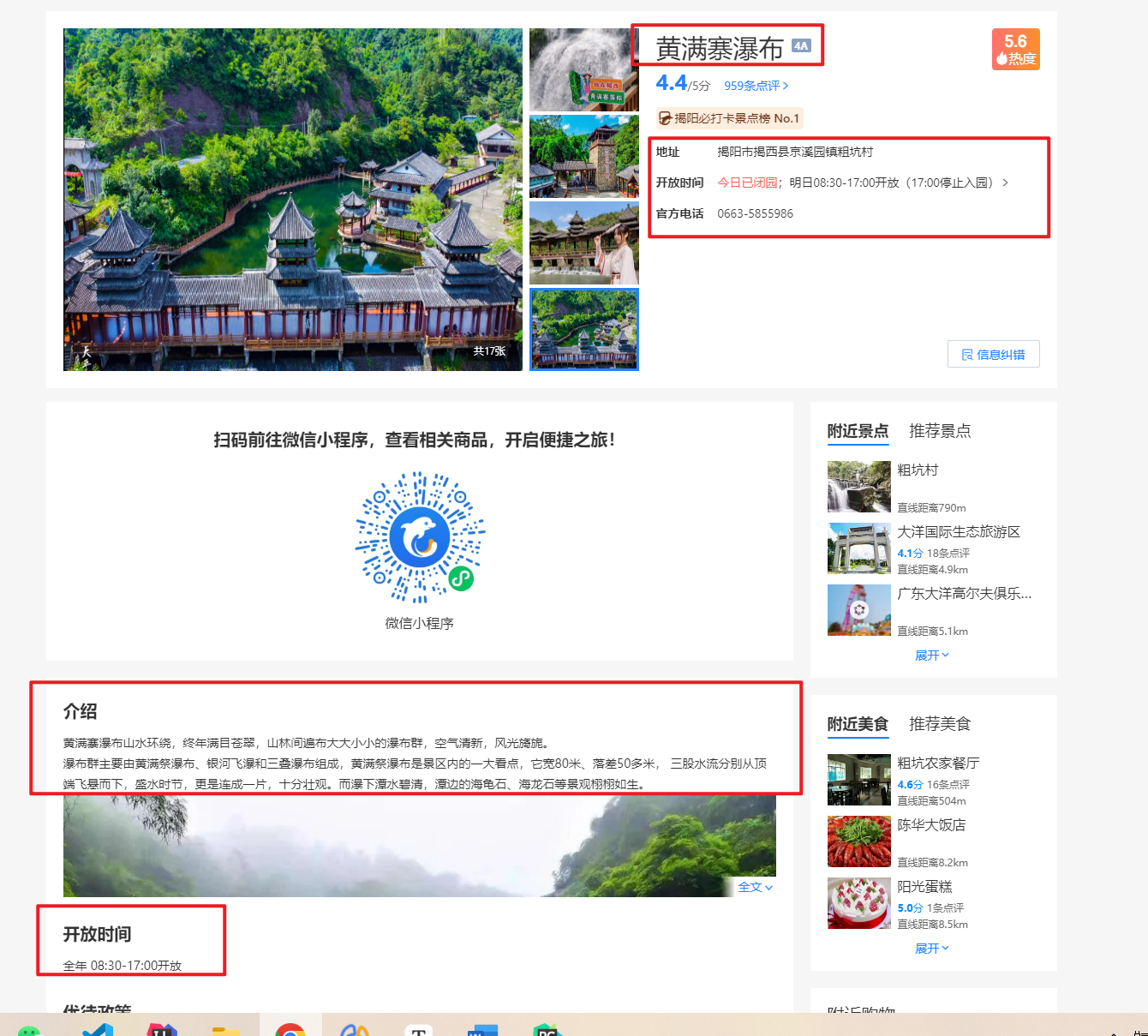
如下图,景点的详细信息有:景点名称、景点等级(1-5A)、景点地址、开放时间(有两种,我们采用下面的)、联系电话、景点介绍、景点图片等内容
3.3代码详讲
3.3.1查询指定城市的所有景点
- 控制打开chrome,并访问指定查询所有景点路径
def __init__(self): options = Options() options.add_argument('--headless') service = Service() self.chrome = Chrome(service=service) self.chrome.get( 'https://huodong.ctrip.com/things-to-do/list?pagetype=city&citytype=dt&keyword=%E6%A2%85%E5%B7%9E&id=523&name=%E6%A2%85%E5%B7%9E&pshowcode=Ticket2&kwdfrom=srch&bookingtransactionid=1711160613361_6064') time.sleep(3) self.page = 1 self.headers = { 'cookie': 'suid=lh/P1+4RKuhAYg684ErS+g==; suid=lh/P1+4RKuhAYg684ErS+g==', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36', }3.3.2获取详细景点的访问路径
- 使用selenium的根据class定位元素方法,找到详细景点的href属性,即为该景点的访问路径
- 并通过page属性控制访问的页数
#获取景点请求路径 def get_url(self): while True: content = self.chrome.find_element(By.CLASS_NAME, "right-content-list").get_attribute('innerHTML') cons = re.findall(r'href="(.*?)" ', content) for con in cons: self.detail_url = 'https:' + con[0] self.title = con[1] print(self.detail_url, self.title) self.get_detail() self.chrome.find_element(By.CLASS_NAME,'u_icon_enArrowforward').click() time.sleep(1) self.page += 1 if self.page == 120: break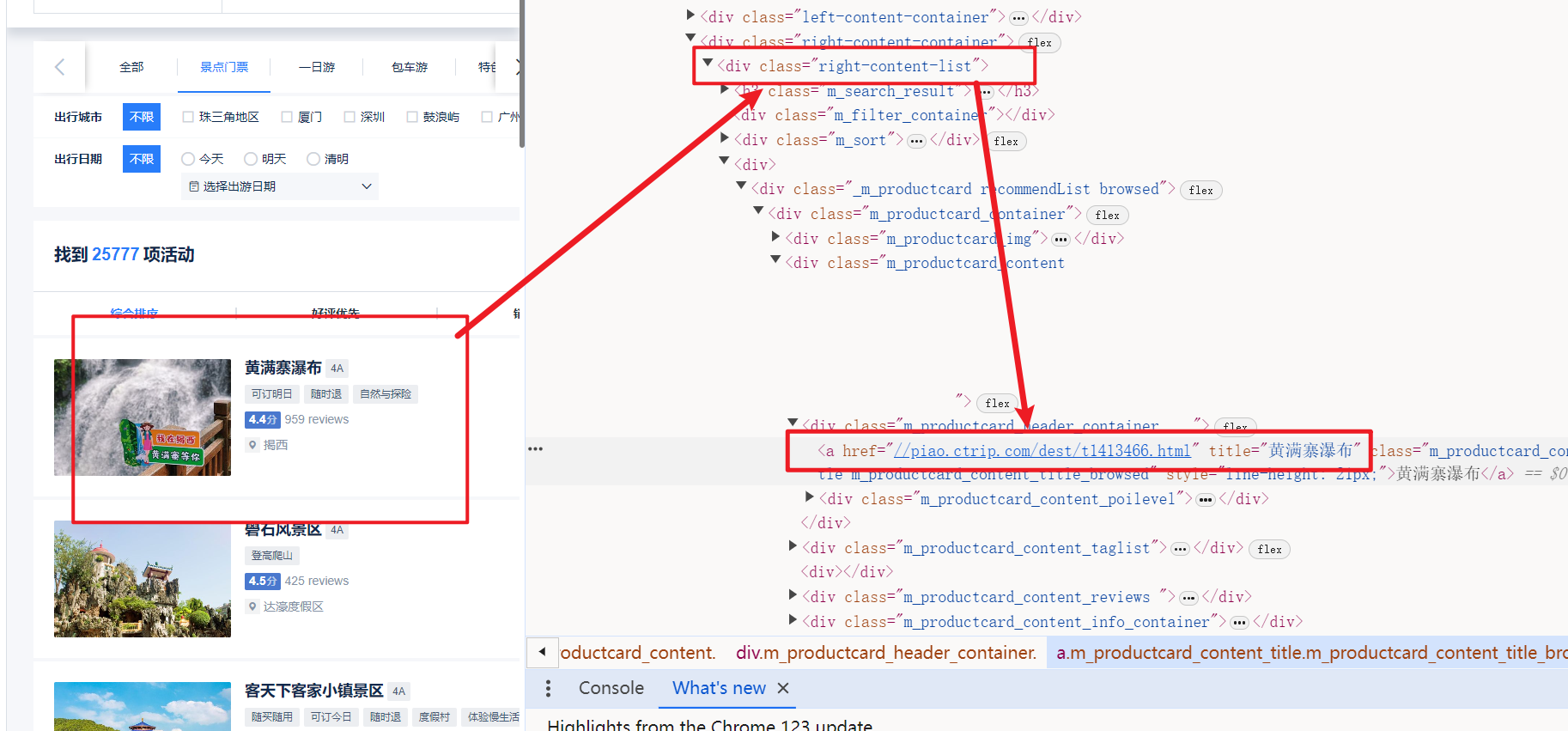
3.3.3获取景点的详细信息
- 景点的详细信息有:景点名称、景点等级(1-5A)、景点地址、开放时间(有两种,我们采用下面的)、联系电话、景点介绍、景点图片等内容
- 通过正则表达式获取,详细代码如下:
- 并每次获取详细信息之后,将信息保存到mysql数据库中
def get_detail(self): detail_con = requests.get(self.detail_url, verify=False, headers=self.headers).text # time.sleep(2) '''使用正则获取信息''' self.title = ''.join(re.findall(r'(.*?)
文章版权声明:除非注明,否则均为主机测评原创文章,转载或复制请以超链接形式并注明出处。



