
Python使用lxml解析XML格式化数据
温馨提示:这篇文章已超过395天没有更新,请注意相关的内容是否还可用!
Python使用lxml解析XML格式化数据
- 1. 效果图
- 2. 源代码
- 参考
方法一:无脑读取文件,遇到有关键词的行再去解析获取值
方法二:利用lxml等库,解析格式化数据,批量获取标签及其值
这篇博客介绍第2种办法,以菜鸟教程中的俩个xml文档为例进行解析;
https://www.runoob.com/try/xml/cd_catalog.xml
https://www.runoob.com/try/xml/books.xml
1. 效果图
cd_catalog.xml原始文件如下:
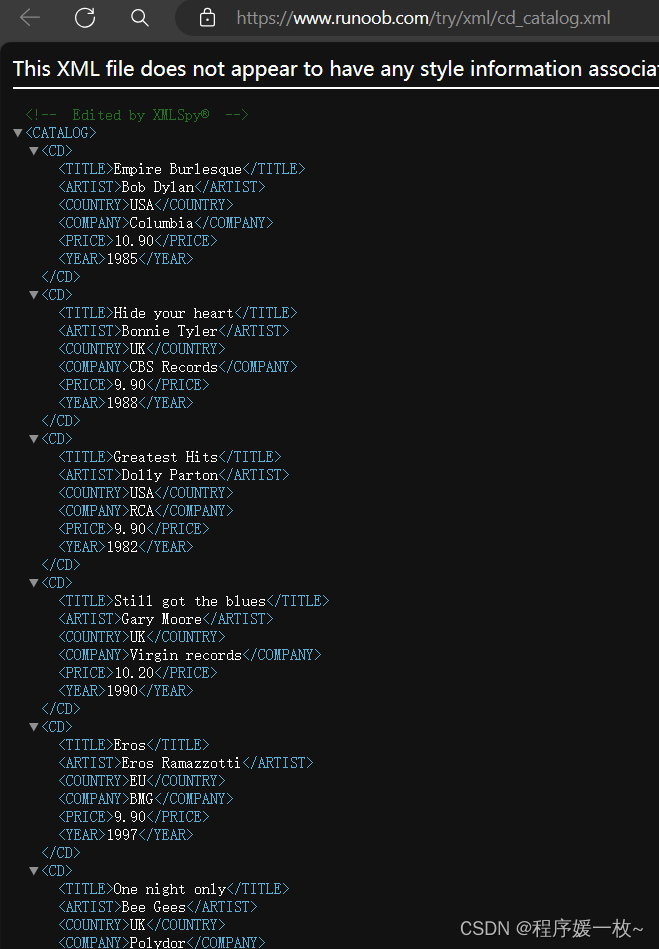
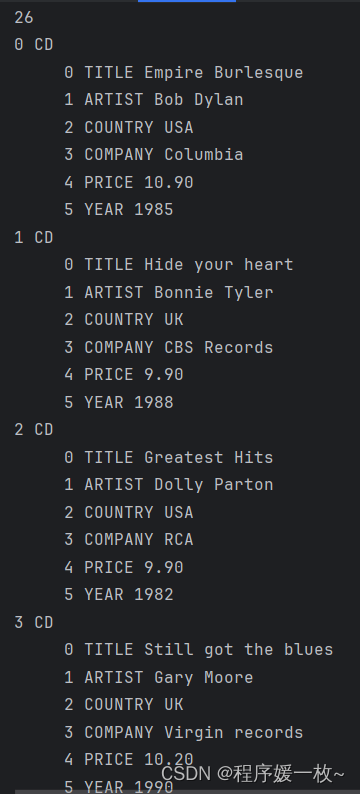
解析cd_catalog.xml后按顺序打印如下:
book.xml原始文件如下:
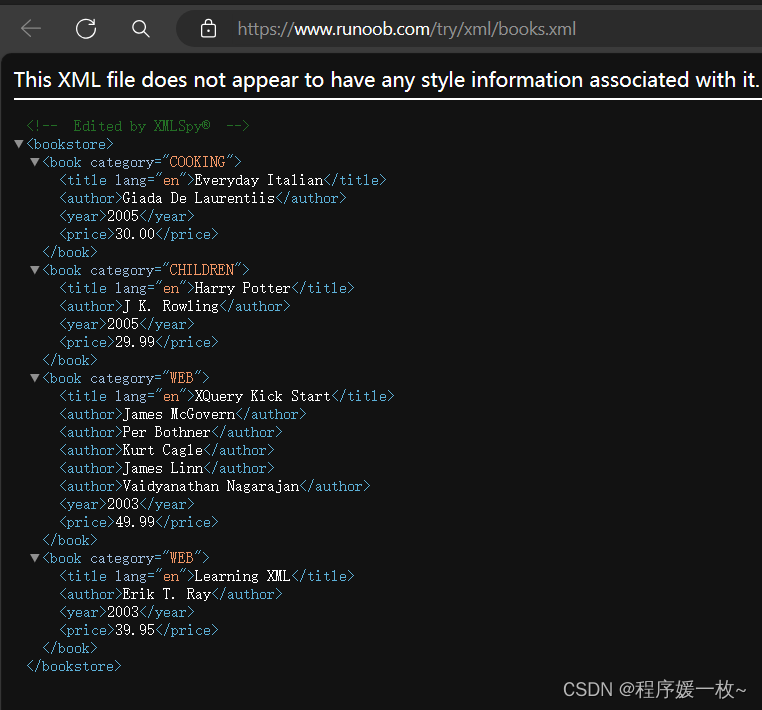
解析books.xml效果图如下:

2. 源代码
# parseXml.py # 解析cd_catalog.xml,book.xml from xml.etree import ElementTree as ET def readBookXml(file): # 直接读取xml文件,形成ElementTree结构 tree = ET.parse(file) root = tree.getroot() # 获取根元素 for i, child in enumerate(root): # 遍历子元素 print(i, child.tag, child.text, child.attrib) # 输出子元素的标签和属性值 for j in range(len(child)): print('\t', j, child[j].tag, child[j].text, child[j].attrib) # 输出子元素中的标签及属性值 # 获取XML文档的根元素 root = tree.getroot() # 查找具有指定标签的第一个子元素 element = root.find('book') # 查找具有指定标签的所有子元素 books = root.findall('book') print(len(books)) for i, book in enumerate(books): print(i, book.tag, book.text, book.attrib) # 输出子元素的标签和属性值 for j in range(len(book)): print('\t', j, book[j].tag, book[j].text, book[j].attrib) # 输出子元素中的标签及属性值 def readCatalogXml(file): # 直接读取xml文件,形成ElementTree结构 tree = ET.parse(file) root = tree.getroot() # 获取根元素 for i, child in enumerate(root): # 遍历子元素 print(i, child.tag, child.text, child.attrib) # 输出子元素的标签和属性值 for j in range(len(child)): print('\t', j, child[j].tag, child[j].text, child[j].attrib) # 输出子元素中的标签及属性值 # 获取XML文档的根元素 root = tree.getroot() # 查找具有指定标签的第一个子元素 element = root.find('CD') # 查找具有指定标签的所有子元素 books = root.findall('CD') print(len(books)) for i, book in enumerate(books): print(i, book.tag) # 输出子元素的标签 for j in range(len(book)): print('\t', j, book[j].tag, book[j].text) # 输出子元素中的标签及属性值 file = 'test/books.xml' readBookXml(file) file = 'test/cd_catalog.xml' readCatalogXml(file)参考
- https://blog.csdn.net/qq233325332/article/details/130799948
- https://blog.csdn.net/weixin_43856625/article/details/134775566
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们,邮箱:ciyunidc@ciyunshuju.com。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!



