
【Python】科研代码学习:九 parser,argparse,HfArgumentParser
温馨提示:这篇文章已超过384天没有更新,请注意相关的内容是否还可用!
【Python】科研代码学习:九 parser,argparse,HfArgumentParser
- parser
- argparser
- add_argument 添加参数
- parse_args 解析参数
- add_argument 高级应用
- HfArgumentParser
parser
- 首先了解一下,parser 是干什么的
parser,解析器,可以让人轻松编写用户友好的命令行接口
主要从 sys.argv 识别解析用户给出的参数,方面这些参数后续 .py 文件中的操作
- parser 是 python 直接支持使用的库,使用
import parser
即可导入使用
- 但是现在使用 parser 的人越来越少了,为什么呢?
argparser
- 当然是有替换更好用的库,argparser
argparser, 官方API
- 首先看导入头文件:
import argparser
- 然后看一下,argparser 主要是通过实例化一个 ArgumentParser 类来做各种操作的:
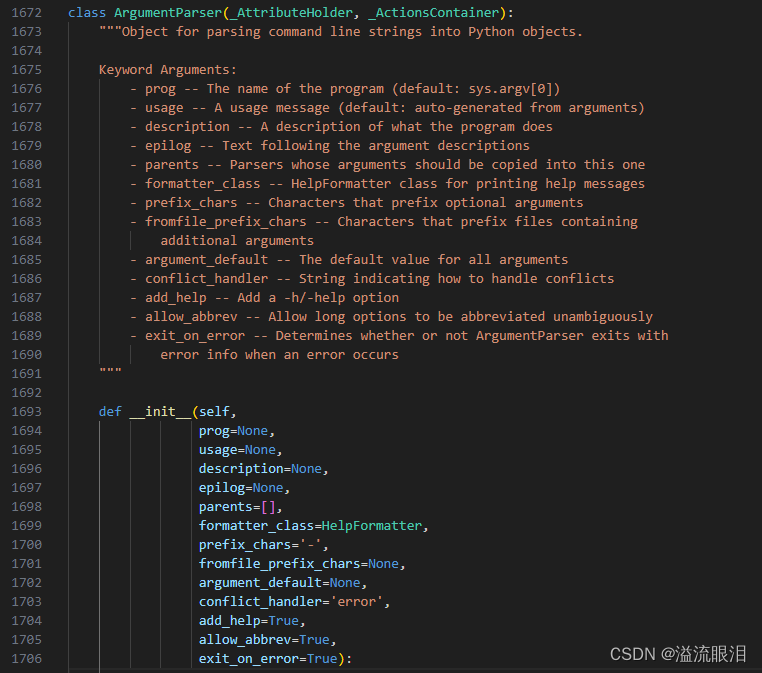
parser = argparse.ArgumentParser( prog='ProgramName', description='What the program does', epilog='Text at the bottom of help')- 顺便看下源码,以及构造参数
prog:描述项目名
description:描述项目作用
epilog:在参数帮助信息之后显示的文本
add_argument 添加参数
- 还是看最重要的方法吧
首先是为解析器添加参数
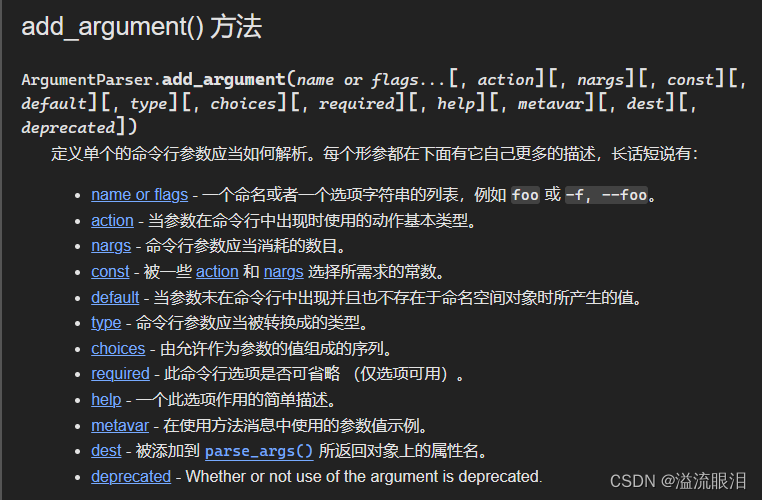
- 首先需要知道 位置参数,选项参数 这两者的区别,这相当于调用一个函数时的参数提供: f(12,b=5),前面就是位置参数,后面是选项参数
选项参数有短选项参数 -f 和长选项 --foo,他们表示相同的含义,只不过约定俗成,短选项参数为一个 - 后接一个字母,据说特殊情况也可以接多个。但比如 -abc,一般我们就认为它使用了三个短选项参数,即 -a -b -c 的简写
- 如果输入参数是以 - 开头,则识别为选项参数,否则其他都识别为位置参数。
parser.add_argument('filename') # 位置参数 parser.add_argument('-c', '--count') # 选项参数,其中 -c 和 --count 是一个含义 parser.add_argument('-v', '--verbose', action='store_true') parser.add_argument('--foo', help='foo help') # 只提供长选项参数parse_args 解析参数
- 有如下几种解析参数的方式
- 第一种:通过 cmd 中,或者 .sh 中,提供参数:
OUTPUT_DIR=${1:-"./llama-2-7b-oscar-ft"} export HF_DATASETS_CACHE=".cache/huggingface_cache/datasets" export TRANSFORMERS_CACHE=".cache/models/" # random port between 30000 and 50000 port=$(( RANDOM % (50000 - 30000 + 1 ) + 30000 )) accelerate launch --main_process_port ${port} --config_file configs/deepspeed_train_config.yaml \ run_llmmt.py \ --model_name_or_path meta-llama/Llama-2-7b-hf \ --oscar_data_path oscar-corpus/OSCAR-2301 \ --oscar_data_lang en,ru,cs,zh,is,de \ --interleave_probs "0.17,0.22,0.14,0.19,0.08,0.2" \ --streaming \ --max_steps 600000 \ --do_train \ ..... 太长省略然后在 .py 文件中,直接调用
args = parser.parse_args()
※ 然后就可以随意使用其中的参数啦
print(args.seed) print(args.do_train)
- 第二种:提供字符串列表作为参数,而不是上面的空参数
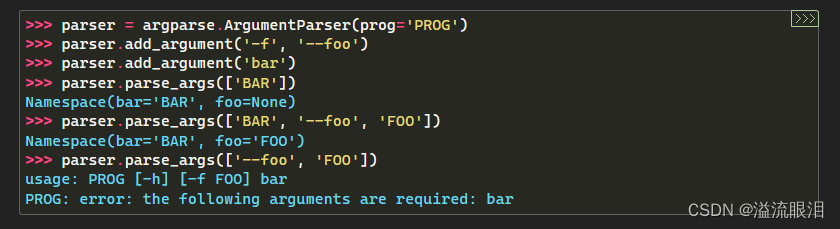
他这里有选项参数 --foo 和位置参数 bar
第一个只提供了 ['BAR'],默认作为位置参数,所以有 bar='BAR'
第二个提供了 ['BAR', '--foo', 'FOO'],第一个为位置参数,所以有 bar='BAR' 第二个选项参数 --foo 设置为 FOO
第三个,只提供了选项参数,报错,因为位置参数是都需要提供的
- 当然也可以给一整个字符串,然后 .split() 也是同理的,但这个更接近于 cmd / sh 的格式

add_argument 高级应用
- 核心就是上面两个方法,这两个都明白之后,就可以看能做什么高级操作了
- action
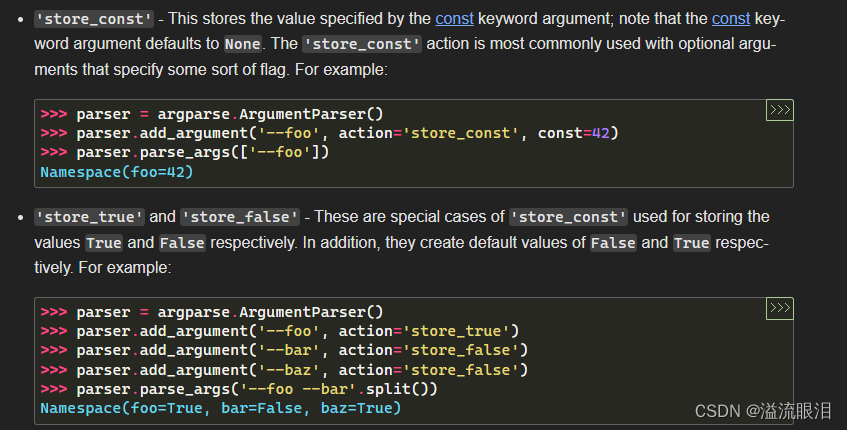
如果设置 action='store_const',那么使用 const=xxx 来设置存储的常数。这样调用 --foo 的话,最终foo=42,不然 foo=None
如果设置 action='store_true',那么如果有提供该参数,该参数值变为 true,没提供该参数的话该参数值为 false;store_false 同理
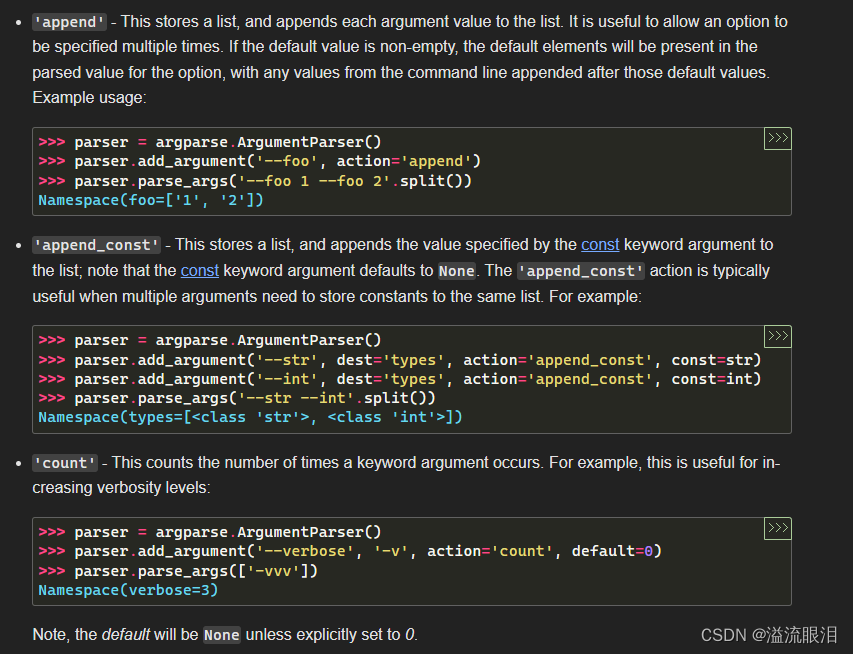
- action='apend' 的话,那么设定该参数是一个列表,我就可以提供多次该参数值,比如这里 --foo 1 --foo 2,那么 foo=['1','2'] 的列表了
- action='append_const' 的话,相当于是 const 和 append 的一个混合,同理。
- action='count' 的话,会返回调用该参数的次数
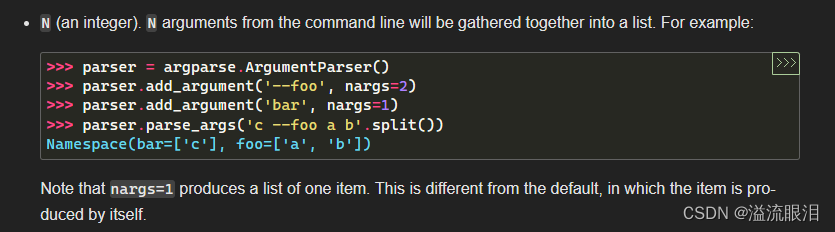
- nargs 可以设定该参数的接受参数个数
比如 ('--foo', nargs=2),表示 --foo 后面需要接受俩参数,即 --foo a b
可以设置为 nargs='?' ,表示可以接受1个或0个。0个的时候会调用 default 的值
可以设置为 nargs='*' ,表示可以接受任意数量个参数。
可以设置为 nargs='+' ,表示可以接受1个或更多参数。

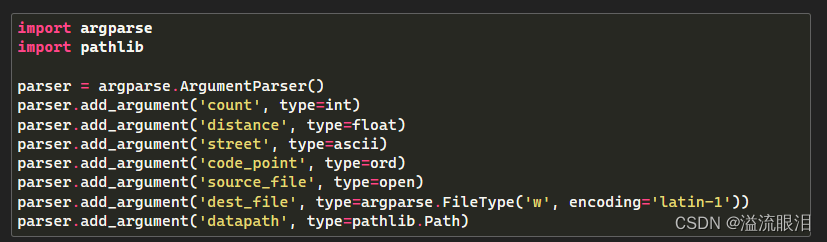
- 可以使用 type 设定接受参数的数据类型,例子有:
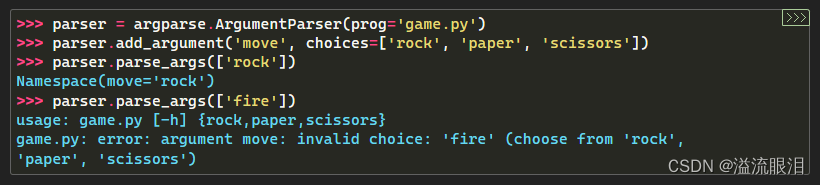
- 可以使用 choices=[...] 设定,该参数值是给定列表中的一个选项。否则报错。
- 可以设定 required=True 表示该参数必须提供,否则报错。
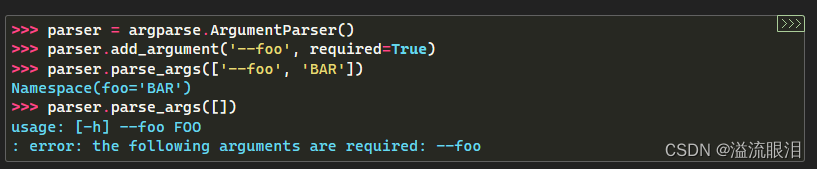
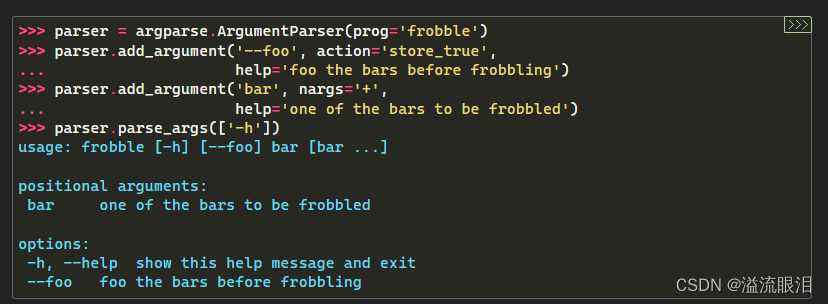
- 可以设定 help='str...' ,表示该参数的作用介绍
可以使用格式 %(var)s 就可以显示变量的值,比如 %(prog)s 或者 %(default)s
HfArgumentParser
- 看名字就知道,HfArgumentParser 是 HF 使用了 ArgumentParser,为了更契合 HF 中的一些方法,做的一个工具
HF官网API:trainer_utils / HfArgumentParser
首先是导入
from transformers import HfArgumentParser
- 然后是怎么使用,这一段几乎大部分使用到它都会有的代码
一开始会去初始化 模型配置、数据配置和训练配置的参数
接下来,通过判断 sys.argv ,观察是通过 .json 传递参数(加载对应的json_file),还是通过 cmd / sh 里提供配置参数(解析成 dataclass)
然后传递到 model_args, data_args, training_args 三个变量中去
from utils.arguments import ModelArguments, DataTrainingArguments from transformers import ( HfArgumentParser, TrainingArguments, default_data_collator, ) from transformers import HfArgumentParser def main(): # See all possible arguments in src/transformers/training_args.py # or by passing the --help flag to this script. # We now keep distinct sets of args, for a cleaner separation of concerns. parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments)) if len(sys.argv) == 2 and sys.argv[1].endswith(".json"): # If we pass only one argument to the script and it's the path to a json file, # let's parse it to get our arguments. model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1])) else: model_args, data_args, training_args = parser.parse_args_into_dataclasses()- 最后就是通过这些参数,进行调用咯。这里给了一些代码例子
tokenizer = load_tokenizer(data_args, model_args, training_args, logger) train_datasets, eval_datasets, test_datasets = preprocess_cpo_data(train_raw_data, valid_raw_data, test_raw_data, pairs, tokenizer, shots_eval_dict, data_args, training_args, model_args) model = load_model(data_args, model_args, training_args, tokenizer, logger) trainer = CPOTrainer( model, args=training_args, beta=model_args.cpo_beta, train_dataset=train_datasets, eval_dataset=eval_datasets, tokenizer=tokenizer, max_prompt_length=data_args.max_source_length, max_length=data_args.max_source_length+data_args.max_new_tokens, callbacks=[SavePeftModelCallback] if model_args.use_peft else None, ) # Training if training_args.do_train: checkpoint = None if training_args.resume_from_checkpoint is not None: checkpoint = training_args.resume_from_checkpoint trainer.train(resume_from_checkpoint=checkpoint) trainer.save_state() if model_args.use_peft: if torch.distributed.get_rank() == 0: model.save_pretrained(training_args.output_dir) else: trainer.save_model() # Saves the tokenizer too for easy upload
- 最后就是通过这些参数,进行调用咯。这里给了一些代码例子
- 然后是怎么使用,这一段几乎大部分使用到它都会有的代码
- 看名字就知道,HfArgumentParser 是 HF 使用了 ArgumentParser,为了更契合 HF 中的一些方法,做的一个工具
- 第二种:提供字符串列表作为参数,而不是上面的空参数
- 还是看最重要的方法吧
- 顺便看下源码,以及构造参数
- 然后看一下,argparser 主要是通过实例化一个 ArgumentParser 类来做各种操作的:
- 当然是有替换更好用的库,argparser
- 但是现在使用 parser 的人越来越少了,为什么呢?
- 首先了解一下,parser 是干什么的



