
随机森林算法介绍及多分类预测的R实现
温馨提示:这篇文章已超过392天没有更新,请注意相关的内容是否还可用!
随机森林(Random Forest)是一种经典的机器学习算法,是数据科学家中最受欢迎和常用的算法之一,最早由Leo Breiman和Adele Cutler于2001年提出。它是基于集成学习(Ensemble Learning)的一种方法,通过组合多个决策树来进行预测和分类,在回归问题中则取平均值。其最重要的特点之一是能够处理包含连续变量和分类变量的数据集。在本文中,我们将详细了解随机森林的工作原理,介绍其在R中的实现及其优缺点。
1. 算法基本原理
1) 随机抽样:在随机森林中,每个决策树的训练样本都是通过随机抽样得到的。随机抽样是指从原始训练集中有放回地抽取一部分样本,构成一个新的训练集。这样做的目的是使得每个决策树的训练样本略有差异,增加决策树之间的多样性。
2) 随机特征选择:在每个决策树的节点上,随机森林算法会从所有特征中随机选择一部分特征进行分割。这样做的目的是增加每个决策树之间的差异性,防止某些特征过于主导整个随机森林的决策过程。
3) 决策树构建:使用随机采样的数据和随机选择的特征,构建多个决策树。决策树的构建过程中,采用通常的决策树算法(如ID3、CART等)。
4) 随机森林的预测:当新的样本输入到随机森林中时,它会经过每个决策树的预测过程,最后根据决策集成的方式得到最终的预测结果。对于分类问题,最常见的集成方式是采用多数投票,即根据每个决策树的分类结果进行投票,选择获得最多票数的类别作为最终的预测结果。对于回归问题,可以采用平均预测的方式,即将每个决策树的预测值取平均作为最终的预测结果。n
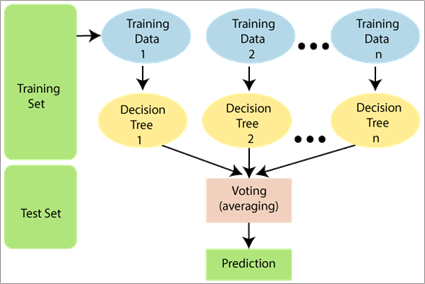
通过随机抽样和随机特征选择,随机森林算法能够减少过拟合风险,提高模型的泛化能力。同时,通过集成多个决策树的预测结果,随机森林能够获得更稳定和准确的预测。
2. 随机森林算法的R实现
以鸢尾花数据集为例,加载需要的包及数据集,未安装的需要先安装。
library(randomForest) library(datasets) library(caret) data



