
一篇博客彻底掌握:粒子滤波 particle filter (PF) 的理论及实践(matlab版)
温馨提示:这篇文章已超过444天没有更新,请注意相关的内容是否还可用!
粒子滤波在目标跟踪中的应用:粒子滤波VS无迹卡尔曼滤波
粒子滤波—从贝叶斯滤波到粒子滤波理论到实践
原创不易,路过的各位大佬请点个赞
机动目标跟踪/非线性滤波/传感器融合/导航等探讨代码联系WX: ZB823618313
粒子滤波 —从贝叶斯滤波到粒子滤波理论到实践
- 粒子滤波在目标跟踪中的应用:粒子滤波VS无迹卡尔曼滤波
- 粒子滤波—从贝叶斯滤波到粒子滤波理论到实践
- 1、问题描述
- 2、递推贝叶斯滤波
- 3、 标准的粒子滤波PF
- 5、粒子滤波PF的在目标跟踪应用:
- 5.1、 仿真参数
- 5.2、 跟踪轨迹和误差
- 6、粒子滤波PF的标准验证模型
- 6.1、 模型参数
- 6.2、 基于随机重采样粒子滤波PF
- 6.3、 基于多项式重采样粒子滤波PF
- 6.4、 基于残差重采样粒子滤波PF
- 6.5、 基于系统重采样粒子滤波PF
- 6.6、 基于系统重采样粒子滤波PF代码
在非线性条件下,贝叶斯滤波面临一个重要问题是状态分布的表达和积分式的求解,由前面章节中的分析可知,对于一般的非线性/非高斯系统,解析求解的途径是行不通的。在数值近似方法中,蒙特卡罗仿真是一种最为通用、有效的手段,粒子滤波就是建立在蒙特卡罗仿真基础之上的,它通过利用一组带权值的系统状态采样来近似状态的统计分布。由于蒙特卡罗仿真方法具有广泛的适用性,由此得到的粒子滤波算法也能适用于一般的非线性/非高斯系统。但是,这种滤波方法也面临几个重要问题,如有效采样(粒子)如何产生、粒子如何传递以及系统状态的序贯估计如何得到等。
简单的理解,粒子滤波就是使用了大量的随机样本,采用蒙特卡洛(MonteCarlo,MC)仿真技术完成贝叶斯递推滤波(Recursive Bayesian Filter)过程。因此本博客从贝叶斯滤波出发,简单介绍粒子滤波PF的出生、即应用
1、问题描述
考虑离散时间非线性系统动态模型,
x k = f ( x k − 1 , w k − 1 ) z k = h ( x k , v k ) (1) x_k=f(x_{k-1},w_{k-1}) \\ z_k=h(x_k,v_k ) \tag{1} xk=f(xk−1,wk−1)zk=h(xk,vk)(1)
其中 x k x_k xk为 k k k时刻的目标状态向量, z k z_k zk为 k k k时刻量测向量(传感器数据)。这里不考虑控制器 u k u_k uk。 w k {w_k} wk和 v k {v_k} vk分别是过程噪声序列和量测噪声序列。 w k w_k wk和 v k v_k vk为零均值高斯白噪声。
由于贝叶斯滤波的递推形式是基于非线性系统的后验概率密度,因此这里并不需要假设 w k w_k wk和 v k v_k vk为零均值高斯白噪声。而KF、EKF、CKF、QKF等需要假设过程、测量噪声为高斯白噪声。
因此基于贝叶斯滤波的粒子滤波可以处理非线性非高斯的状态估计问题。
定义 1 1 1 ~ k k k时刻对状态 x k x_k xk的所有测量数据为
z k = [ z 1 T , z 2 T , ⋯ , z k T ] T z^k=[z_1^T,z_2^T,\cdots,z_k^T]^T zk=[z1T,z2T,⋯,zkT]T
贝叶斯滤波问题就是计算对 k k k时刻状态 x x x估计的置信程度,为此构造概率密度函数 p ( x k ∣ z k ) p(x_k |z^k) p(xk∣zk),在给定初始分布 p ( x 0 ∣ z 0 ) = p ( x 0 ) p(x_0|z_0)= p(x_0) p(x0∣z0)=p(x0)后,从理论上看,可以通过预测和更新两个步骤递推得到概率密度函数 p ( x k ∣ z k ) p(x_k |z^k) p(xk∣zk)的值。
是不是卡尔曼滤波的雏形出现了,哈哈哈,预测、更新也存在KF中。
2、递推贝叶斯滤波
1)预测
现假定 k − 1 k- 1 k−1时刻的概率密度函数已知,则通过将Chapman-Kolmogorov等式应用
于动态方程(1),即可预测 k k k时刻状态的先验概率密度函数为
p ( x k ∣ z k − 1 ) = ∫ p ( x k ∣ x k − 1 ) p ( k − 1 ∣ z k − 1 ) d x k − 1 ) (2) p(x_k |z^{k-1})=\int p(x_k |x_{k-1})p({k-1} |z^{k-1}) dx_{k-1}) \tag{2} p(xk∣zk−1)=∫p(xk∣xk−1)p(k−1∣zk−1)dxk−1)(2)
实际上,状态转移方程写为概率密度的形式即为: x k = f ( x k − 1 , w k − 1 ) = 等价 p ( x k ∣ x k − 1 ) x_k=f(x_{k-1},w_{k-1}) \underset{\text{等价}}= p(x_k |x_{k-1}) xk=f(xk−1,wk−1)等价=p(xk∣xk−1)
式(2)中隐含假定了 p ( x k ∣ x k − 1 ) = p ( x k ∣ x k − 1 , z k − 1 ) p(x_k |x_{k-1})= p(x_k |x_{k-1}, z^{k-1}) p(xk∣xk−1)=p(xk∣xk−1,zk−1),实际上这本身在这里就是成立的,基于(1)式的马尔可夫过程。
2)更新
在获得 p ( x k ∣ z k − 1 ) p(x_k |z^{k-1}) p(xk∣zk−1)的基础上,结合 k k k时刻得到的新的量测值,基于贝叶斯公式,可以计算 k k k时刻状态的后验概率密度函数:
p ( x k ∣ z k ) = p ( z k ∣ x k ) p ( x k ∣ z k − 1 ) p ( z k ∣ z k − 1 ) (3) p(x_k |z^{k})=\frac{p(z_k |x_k)p(x_k |z^{k-1})}{p(z_k |z^{k-1})} \tag{3} p(xk∣zk)=p(zk∣zk−1)p(zk∣xk)p(xk∣zk−1)(3)
式中分子 p ( z k ∣ z k − 1 ) p(z_k |z^{k-1}) p(zk∣zk−1)有全概率公式得到
p ( z k ∣ z k − 1 ) = ∫ p ( z k ∣ x k ) p ( x k ∣ z k − 1 ) d x k (4) p(z_k |z^{k-1})=\int p(z_k |x_k)p(x_k |z^{k-1}) dx_{k} \tag{4} p(zk∣zk−1)=∫p(zk∣xk)p(xk∣zk−1)dxk(4)
我就说吧,上述过程实际上贝叶斯后燕推断的公式,哈哈哈哈啊哈
实际上这也是卡尔曼滤波的更新思想:在 k k k时刻得到测量 z k z_k zk后,利用测量 z k z_k zk修正先验概率,进而获得当前时刻状态的后验概率。我正是太机智了,哈哈啊哈
3) 基于 p ( x k ∣ z k ) p(x_k |z^{k}) p(xk∣zk)的各种滤波器
说实话,你关于状态 x k x_k xk的概率密度函数(分布)都得到了,难道确定他们的各种估计还难吗?
这里给所有有缘人提醒下,实际上各种滤波、估计就是求 p ( x k ∣ z k ) p(x_k |z^{k}) p(xk∣zk)的一阶矩( x k x_k xk的估计)以及二阶矩(估计的协方)。(基操、勿6)
式(3)描述了一个由 k − 1 k-1 k−1时刻后验概率密度函数向 k k k时刻后验概率密度函数递推的完整过程,从而构成了贝叶斯估计最优解的通用表示形式。进而通过后验分布 p ( x k ∣ z k ) p(x_k |z^{k}) p(xk∣zk)可以得到不同准则条件下 x x x的最优估计划。
如最小均方误差(MMSE)估计为:
x ^ k = E [ x k ∣ z k ] = ∫ x k p ( x k ∣ z k ) d x k (5) \hat{x}_k=E[x_k|z_k]=\int x_kp(x_k |z^{k}) dx_k \tag{5} x^k=E[xk∣zk]=∫xkp(xk∣zk)dxk(5)
最大后验(MAP)估计为:
x ^ k = arg min x k p ( x k ∣ z k ) \hat{x}_k=\arg \min_{x_k} p(x_k |z^{k}) x^k=argxkminp(xk∣zk)
实际上粒子滤波就是基于蒙特卡洛技术、将上述递推过程用大量采样的方式实现了。
是不是看到这里,有一种豁然开朗的感觉,实际上上面的介绍及推导都是简化版本,也加了本人一些愚钝的理解在里面,因此也是有一些误区、对高水平之人、还是建议看经典的著作最为有用和严谨。
3、 标准的粒子滤波PF
核心思想:是使用一组具有相应权值的随机样本(粒子)来表示状态的后验分布。该方法的基本思路是选取一个重要性概率密度并从中进行随机抽样,得到一些带有相应权值的随机样本后,在状态观测的基础上调节权值的大小。和粒子的位置,再使用这些样本来逼近状态后验分布,最后将这组样本的加权求和作为状态的估计值。粒子滤波不受系统模型的线性和高斯假设约束,采用样本形式而不是函数形式对状态概率密度进行描述,使其不需要对状态变量的概率分布进行过多的约束,因而在非线性非高斯动态系统中广泛应用。尽管如此,粒子滤波目前仍存在计算量过大、粒子退化等关键问题亟待突破。
粒子滤波实际上是上述基于递推贝叶斯滤波的MMSE(5)估计的近似实现,而近似方法就是蒙特卡洛方法。到这里应该很多人就明白了为什么将粒子滤波都要提及贝叶斯滤波。
通常情况下选择先验分布作为重要性密度函数、即
q ( x k ∣ x k − 1 ( i ) , z k ) = p ( x k ∣ x k − 1 ( i ) ) q(x_k |x_{k-1}^{(i)}, z_{k})=p(x_k |x_{k-1}^{(i)}) q(xk∣xk−1(i),zk)=p(xk∣xk−1(i))
对该函数取重要性权值为
w k ( i ) = w k − 1 ( i ) p ( z k ∣ x k ( i ) ) w_k^{(i)}=w_{k-1}^{(i)}p(z_k |x_{k}^{(i)}) wk(i)=wk−1(i)p(zk∣xk(i))
同样 w k ( i ) w_k^{(i)} wk(i)需要归一化得到 w ~ k ( i ) \tilde{w}_k^{(i)} w~k(i)。
标准的粒子滤波算法步骤为:
粒子滤波PF:
Step 1: 根据 p ( x 0 ) p(x_{0}) p(x0)采样得到 N N N个粒子 x 0 ( i ) ∼ p ( x 0 ) x_0^{(i)} \sim p(x_{0}) x0(i)∼p(x0)
For i = 2 : N i=2:N i=2:N
Step 2: 根据状态转移函数产生新的粒子为:$ x k ( i ) ∼ p ( x k ∣ x k − 1 ( i ) ) x_k^{(i)} \sim p(x_{k} |x_{k-1}^{(i)}) xk(i)∼p(xk∣xk−1(i))
Step 3: 计算重要性权值: w k ( i ) = w k − 1 ( i ) p ( z k ∣ x k ( i ) ) w_k^{(i)}=w_{k-1}^{(i)}p(z_k |x_{k}^{(i)}) wk(i)=wk−1(i)p(zk∣xk(i))
Step 4: 归一化重要性权值: w ~ k ( i ) = w k ( i ) ∑ j = 1 N w k ( j ) \tilde{w}_k^{(i)}=\frac{w_k^{(i)}}{\sum_{j=1}^Nw_k^{(j)}} w~k(i)=∑j=1Nwk(j)wk(i)
Step 5: 使用重采样方法对粒子进行重采样(以系统重采样为例)(见面)
Step 6: 得到 k k k时刻的后验状态估计:
E [ x ^ k ] = ∑ i = 1 N x k ( i ) w ~ k ( i ) E[\hat{x}_{k}]= \sum_{i=1}^Nx_{k}^{(i)}\tilde{w}_k^{(i)} E[x^k]=i=1∑Nxk(i)w~k(i)
End For
粒子滤波PF算法结构图
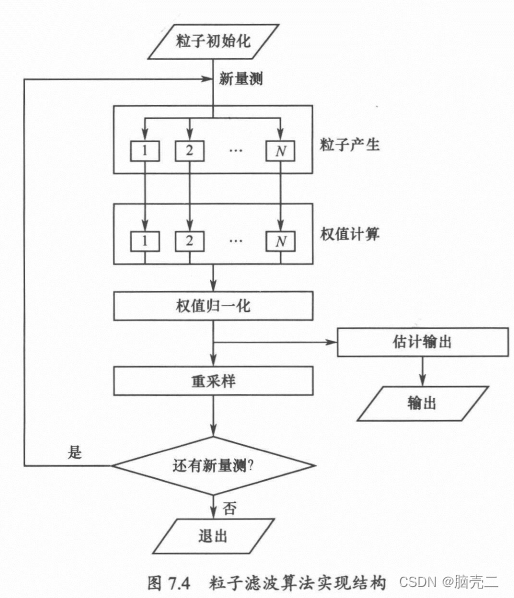
算法:系统重采样 (systematic resampling)
For i = 1 : N i=1:N i=1:N
Step 1: 初始化累积概率密度函数CDF: c 1 = 0 c_1=0 c1=0
For i = 2 : N i=2:N i=2:N
Step 2: 构造CDF: c i = c i − 1 + w k ( i ) c_i=c_{i-1}+w_k^{(i)} ci=ci−1+wk(i)
Step 3: 从CDF的底部开始: i = 1 i=1 i=1
Step 4: 采样起始点: u 1 = U [ 0 , 1 / N ] u_1=\mathcal{U}[0,1/N] u1=U[0,1/N]
End For
For j = 1 : N j=1:N j=1:N
Step 5: 沿CDF移动: u j = u 1 + ( j − 1 ) / N u_j=u_{1}+(j-1)/N uj=u1+(j−1)/N
Step 6: While u j > c i u_j>c_i uj>ci
i = i + 1 i=i+1 i=i+1
End While
Step 7: 赋值粒子: x k ( j ) = x k ( i ) x_k^{(j)}=x_k^{(i)} xk(j)=xk(i)
Step 8: 赋值权值: w k ( j ) = 1 / N w_k^{(j)}=1/N wk(j)=1/N
Step 9: 赋值父代: i ( j ) = i i^{(j)}=i i(j)=i
End For
重采样的思路是:既然那些权重小的不起作用了,那就不要了。要保持粒子数目不变,得用一些新的粒子来取代它们。找新粒子最简单的方法就是将权重大的粒子多复制几个出来,至于复制几个?那就在权重大的粒子里面让它们根据自己权重所占的比例去分配,也就是老大分身分得最多,老二分得次多,以此类推。下面以数学的形式来进行说明。
除了系统重采样方法,还有几种重采样方法:
多项式重采样
残差重采样
随机重采样
5、粒子滤波PF的在目标跟踪应用:
5.1、 仿真参数
**一、目标模型:CT(细节见另一个博客) **
X k + 1 = [ 1 sin ( ω T ) ω 0 − 1 − cos ( ω T ) ω 0 cos ( ω T ) 0 − sin ( ω T ) 0 1 − cos ( ω T ) ω 1 sin ( ω T ) ω 0 sin ( ω T ) 0 cos ( ω T ) ] X k + [ T 2 / 2 0 T 0 0 T 2 / 2 0 T ] W k X_{k+1}=\begin{bmatrix}1&\frac{\sin(\omega T)}{\omega}&0&-\frac{1-\cos(\omega T)}{\omega}\\0&\cos(\omega T)&0&-\sin(\omega T)\\0&\frac{1-\cos(\omega T)}{\omega}&1&\frac{\sin(\omega T)}{\omega}\\0&\sin(\omega T)&0&\cos(\omega T)\end{bmatrix}X_{k} + \begin{bmatrix}T^2/2&0\\T&0\\0&T^2/2\\0&T\end{bmatrix}W_k Xk+1=⎣⎢⎢⎡1000ωsin(ωT)cos(ωT)ω1−cos(ωT)sin(ωT)0010−ω1−cos(ωT)−sin(ωT)ωsin(ωT)cos(ωT)⎦⎥⎥⎤Xk+⎣⎢⎢⎡T2/2T0000T2/2T⎦⎥⎥⎤Wk
CV CT 模型的具体方程形式见另一个博客
二、测量模型:2D主动雷达
在二维情况下,雷达量测为距离和角度
r k m = r k + r ~ k b k m = b k + b ~ k {r}_k^m=r_k+\tilde{r}_k\\ b^m_k=b_k+\tilde{b}_k rkm=rk+r~kbkm=bk+b~k
其中
r k = ( x k − x 0 ) + ( y k − y 0 ) 2 ) b k = tan − 1 y k − y 0 x k − x 0 r_k=\sqrt{(x_k-x_0)^+(y_k-y_0)^2)}\\ b_k=\tan^{-1}{\frac{y_k-y_0}{x_k-x_0}}\\ rk=(xk−x0)+(yk−y0)2) bk=tan−1xk−x0yk−y0
[ x 0 , y 0 ] [x_0,y_0] [x0,y0]为雷达坐标,一般情况为0。雷达量测为 z k = [ r k , b k ] ′ z_k=[r_k,b_k]' zk=[rk,bk]′。雷达量测方差为
R k = cov ( v k ) = [ σ r 2 0 0 σ b 2 ] R_k=\text{cov}(v_k)=\begin{bmatrix}\sigma_r^2 & 0 \\0 & \sigma_b^2 \end{bmatrix} Rk=cov(vk)=[σr200σb2]
5.2、 跟踪轨迹和误差
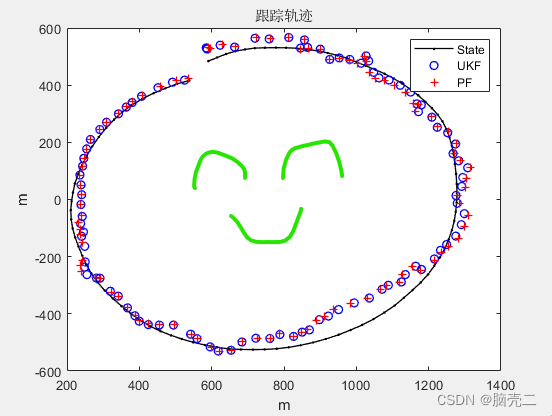
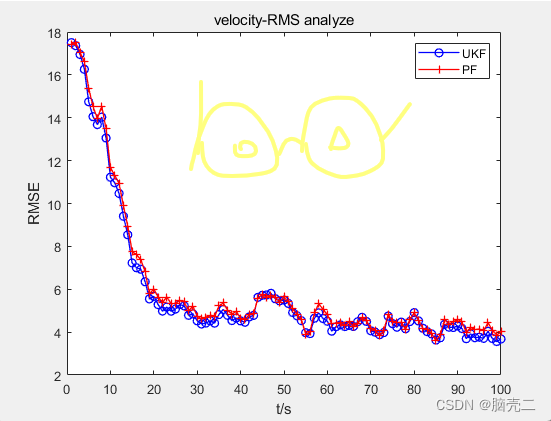
6、粒子滤波PF的标准验证模型
6.1、 模型参数
状态模型:
x ( k ) = f ( x ( k − 1 ) , k ) + w ( k − 1 ) x(k) = f (x(k-1), k) + w(k-1) x(k)=f(x(k−1),k)+w(k−1)
其中
f ( x ( ( k − 1 ) , k ) = 0.5 x ( k − 1 ) + 2.5 x ( k − 1 ) / ( 1 + x ( k − 1 ) 2 ) + 8 cos ( 1.2 k ) f(x((k-1), k) = 0.5x(k-1) + 2.5x(k-1) / (1+x(k-1)^2) + 8\cos(1.2k) f(x((k−1),k)=0.5x(k−1)+2.5x(k−1)/(1+x(k−1)2)+8cos(1.2k)
测量方程为:
z ( k ) = x ( k ) 2 / 20 + v ( k ) z(k) = x(k)^2 / 20 +v(k) z(k)=x(k)2/20+v(k)
w ( k ) w(k) w(k), v ( k ) v(k) v(k)为均值为 0 0 0、方差分别为 Q ( k ) = 10 Q(k)=10 Q(k)=10, R ( k ) = 1 R(k)=1 R(k)=1的高斯噪声。状态 x ( k ) x(k) x(k)与 x ( k − 1 ) x(k-1) x(k−1)为非线性关系,观测方程中 z ( k ) z(k) z(k)和x ( k ) (k) (k)也是非线性关系。
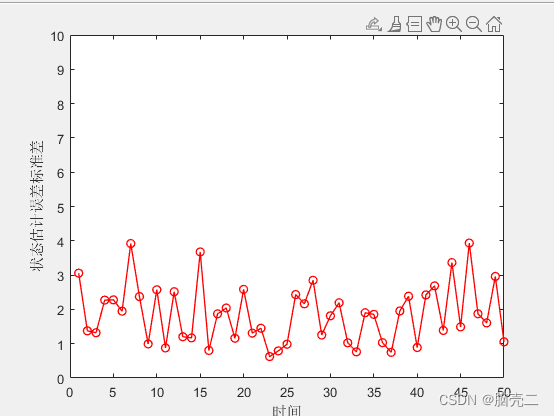
6.2、 基于随机重采样粒子滤波PF
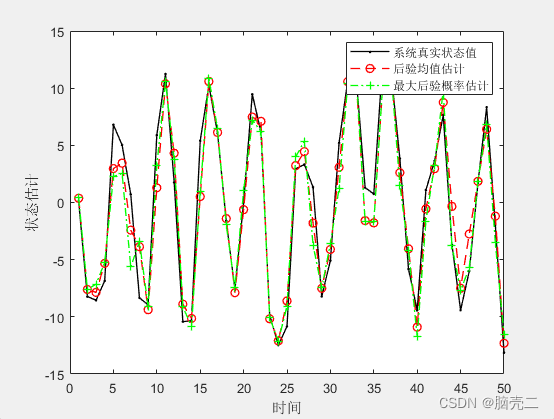
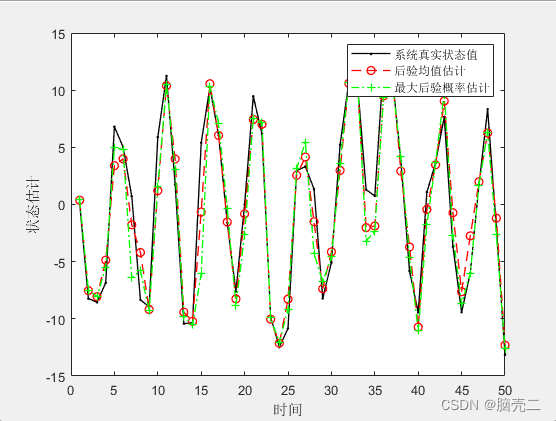
6.3、 基于多项式重采样粒子滤波PF
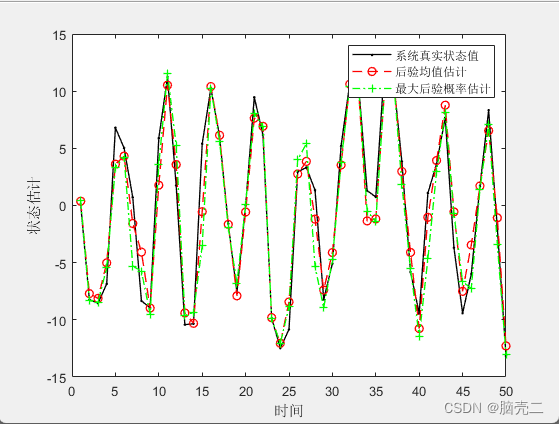
6.4、 基于残差重采样粒子滤波PF
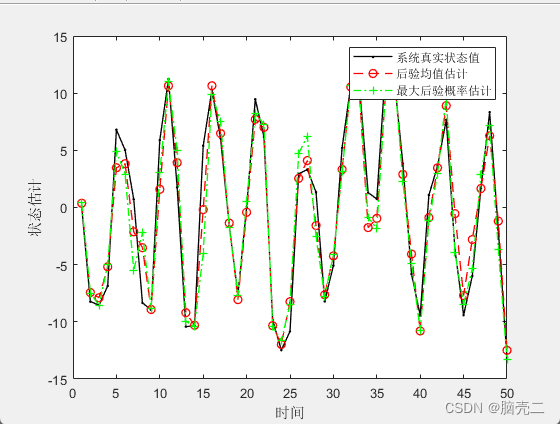
6.5、 基于系统重采样粒子滤波PF
6.6、 基于系统重采样粒子滤波PF代码
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %% 粒子滤波一维系统仿真 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% function ParticleFilter_standardmodel clear all;close all;clc; randn('seed',1); %为了保证每次运行结果一致,给定随机数的种子点 %初始化相关参数 T=50;%采样点数 dt=1;%采样周期 Q=10;%过程噪声方差 R=1;%测量噪声方差 v=sqrt(R)*randn(T,1);%测量噪声 w=sqrt(Q)*randn(T,1);%过程噪声 numSamples=100;%粒子数 %%%%%%%%%%%%%%%%%%%%%%%%%%% x0=0.1;%初始状态 %产生真实状态和观测值 X=zeros(T,1);%真实状态 Z=zeros(T,1);%量测 X(1,1)=x0;%真实状态初始化 Z(1,1)=(X(1,1)^2)./20+v(1,1);%观测值初始化 for k=2:T %状态方程 X(k,1)=0.5*X(k-1,1)+2.5*X(k-1,1)/(1+X(k-1,1)^2)+8*cos(1.2*k)+w(k-1,1); %观测方程 Z(k,1)=(X(k,1).^2)./20+v(k,1); end %%%%%%%%%%%%%%%%%%%%%%%%%%% %粒子滤波器初始化,需要设置用于存放滤波估计状态,粒子集合,权重等数组 Xpf=zeros(numSamples,T);%粒子滤波估计状态 Xparticles=zeros(numSamples,T);%粒子集合 Zpre_pf=zeros(numSamples,T);%粒子滤波观测预测值 weight=zeros(numSamples,T);%权重初始化 %给定状态和观测预测的初始采样: Xpf(:,1)=x0+sqrt(Q)*randn(numSamples,1); Zpre_pf(:,1)=Xpf(:,1).^2/20; %更新与预测过程 for k=2:T %第一步:粒子集合采样过程 for i=1:numSamples QQ=Q;%跟卡尔曼滤波不同,这里的Q不要求与过程噪声方差一致 net=sqrt(QQ)*randn;%这里的QQ可以看成是网的半径,数值可调 Xparticles(i,k)=0.5.*Xpf(i,k-1)+2.5.*Xpf(i,k-1)./(1+Xpf(i,k-1).^2)+8*cos(1.2*k)+net; end %第二步:对粒子集合中的每个粒子,计算其重要性权值 for i=1:numSamples Zpre_pf(i,k)=Xparticles(i,k)^2/20; weight(i,k)=exp(-.5*R^(-1)*(Z(k,1)-Zpre_pf(i,k))^2);%省略了常数项 end weight(:,k)=weight(:,k)./sum(weight(:,k));%归一化权值 %第三步:根据权值大小对粒子集合重采样,权值集合和粒子集合是一一对应的 %选择采样策略 outIndex = systematicR(weight(:,k)'); %第四步:根据重采样得到的索引,去挑选对应的粒子,重构的集合便是滤波后的状态集合 %对这个状态集合求均值,就是最终的目标状态、 Xpf(:,k)=Xparticles(outIndex,k); end %计算后验均值估计、最大后验估计及估计方差 Xmean_pf=mean(Xpf);%后验均值估计,及上面的第四步,也即粒子滤波估计的最终状态 bins=20; Xmap_pf=zeros(T,1); for k=1:T [p,pos]=hist(Xpf(:,k,1),bins); map=find(p==max(p)); Xmap_pf(k,1)=pos(map(1));%最大后验估计 end for k=1:T Xstd_pf(1,k)=std(Xpf(:,k)-X(k,1));%后验误差标准差估计 end %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %画图 figure();clf;%过程噪声和测量噪声图 subplot(221); plot(v);%测量噪声 xlabel('时间');ylabel('测量噪声'); subplot(222); plot(w);%过程噪声 xlabel('时间');ylabel('过程噪声'); subplot(223); plot(X);%真实状态 xlabel('时间');ylabel('状态X'); subplot(224); plot(Z);%观测值 xlabel('时间');ylabel('观测Z'); %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% figure(); k=1:dt:T; plot(k,X,'.-k',k,Xmean_pf,'--ro',k,Xmap_pf,'-.g+','LineWidth',1);%注:Xmean_pf就是粒子滤波结果 legend('系统真实状态值','后验均值估计','最大后验概率估计'); xlabel('时间');ylabel('状态估计'); %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% figure(); subplot(121); plot(Xmean_pf,X,'+');%粒子滤波估计值与真实状态值如成1:1关系,则会对称分布 xlabel('后验均值估计');ylabel('真值'); hold on; c=-25:1:25; plot(c,c,'r');%画红色的对称线y=x hold off; subplot(122);%最大后验估计值与真实状态值如成1:1关系,则会对称分布 plot(Xmap_pf,X,'+'); xlabel('Map估计');ylabel('真值'); hold on; c=-25:25; plot(c,c,'r');%画红色的对称线y=x hold off; %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %画直方图,此图形是为了看粒子集的后验密度 domain=zeros(numSamples,1); range=zeros(numSamples,1); bins=10; support=[-20:1:20]; figure(); hold on;%直方图 xlabel('时间');ylabel('样本空间'); vect=[0 1]; caxis(vect); for k=1:T %直方图反映滤波后的粒子集合的分布情况 [range,domain]=hist(Xpf(:,k),support); %调用waterfall函数,将直方图分布的数据画出来 waterfall(domain,k,range); end axis([-20 20 0 T 0 100]); %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% figure(); xlabel('样本空间');ylabel('后验密度'); k=30;%k=?表示要查看第几个时刻的粒子分布与真实状态值的重叠关系 [range,domain]=hist(Xpf(:,k),support); plot(domain,range); %真实状态在样本空间中的位置,画一条红色直线表示 XXX=[X(k,1),X(k,1)]; YYY=[0,max(range)+10]; line(XXX,YYY,'Color','r'); axis([min(domain) max(domain) 0 max(range)+10]); figure(); k=1:dt:T; plot(k,Xstd_pf,'-ro','LineWidth',1); xlabel('时间');ylabel('状态估计误差标准差'); axis([0,T,0,10]); %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% % 系统重采样子函数 % 输入参数:weight为原始数据对应的权重大小 % 输出参数:outIndex是根据weight筛选和复制结果 function outIndex = systematicR(weight); N=length(weight); N_children=zeros(1,N); label=zeros(1,N); label=1:1:N; s=1/N; auxw=0; auxl=0; li=0; T=s*rand(1); j=1; Q=0; i=0; u=rand(1,N); while (TT) T=T+s; N_children(1,li)=N_children(1,li)+1; else i=fix((N-j+1)*u(1,j))+j; auxw=weight(1,i); li=label(1,i); Q=Q+auxw; weight(1,i)=weight(1,j); label(1,i)=label(1,j); j=j+1; end end index=1; for i=1:N if (N_children(1,i)>0) for j=index:index+N_children(1,i)-1 outIndex(j) = i; end; end; index= index+N_children(1,i); end %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%PF的妈妈贝叶斯滤波Part-I、蒙特卡洛方法Part-II、序贯重采样Part-III
原创不易,路过的各位大佬请点个赞



